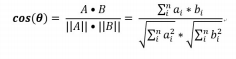对于这个题目,开始毫无头绪,后来经过查阅资料现在讲方法总结如下:
1、利用余弦定理
我们知道向量 a,b之间的夹角可用余弦定理求得:
如果夹角的余弦值越小,那么夹角也越大。如果2个向量相等,那么其值为1。利用此我们可以用来比较文章的相似性。
首先使用一个向量来描述一篇文章,对于一篇文章中的实词,我们可以计算出它们的单文本词汇频率/逆文本频率值(TF/IDF)。不难想象,和新闻主题有关的那些实词频率高,TF/IDF 值很大。我们按照这些实词在词汇表的位置对它们的 TF/IDF 值排序。比如,词汇表有六万四千个词,分别为
单词编号 汉字词
------------------
1 阿
2 啊
3 阿斗
4 阿姨
...
789 服装
....
64000 做作
在一篇新闻中,这 64,000 个词的 TF/IDF 值分别为
单词编号 TF/IDF 值
==============
1 0
2 0.0034
3 0
4 0.00052
5 0
...
789 0.034
...
64000 0.075
如果单词表中的某个文章中没有出现,对应的值为零,那么这 64,000 个数,组成一个64,000维的向量。我们就用这个向量来代表这篇新闻,并成为文章的特征向量。如果两篇文章的特征向量相近,则对应的新闻内容相似,它们应当归在一类,反之亦然。
2、利用simhash算法
simhash算法的输入是一个向量,输出是一个f位的签名值。为了陈述方便,假设输入的是一个文档的特征集合,每个特征有一定的权重。比如特征可以是文档中的词,其权重可以是这个词出现的次数。simhash算法如下:
1,将一个f维的向量V初始化为0;f位的二进制数S初始化为0;
2,对每一个特征:用传统的hash算法对该特征产生一个f位的签名b。对i=1到f:
如果b的第i位为1,则V的第i个元素加上该特征的权重;
否则,V的第i个元素减去该特征的权重。
3,如果V的第i个元素大于0,则S的第i位为1,否则为0;
4,输出S作为签名。
通过计算两篇文章的签名的海明距离得出相似度。
如图:

以上的所有算法我们都只关注文章的全局信息,忽略了文章的局部信息。
海明距离:
对于向量u,v,海明距离为2个向量相异的位数
其中u_i,v_i表示第i维值。
当然还有一些其他的好方法。本文部分内容来自德问,谢谢相关作者的回答。




![[将小白进行到底] 如何比较两篇文章的相似度](https://images0.cnblogs.com/blog/79263/201304/02151548-f7e8409392c846498b9d9e548e92926f.png)