目录
- YOLOv3目标检测算法
- 前沿
- 一.YOLOv3
- 二.损失函数
YOLOv3目标检测算法
前沿
前两篇文章我们讲了下关于YOLOv1和YOLOv2的原理,有不懂的小伙伴可以回到前面再看看:
- YOLOv1目标检测算法——通俗易懂的解析
- YOLOv2目标检测算法——通俗易懂的解析
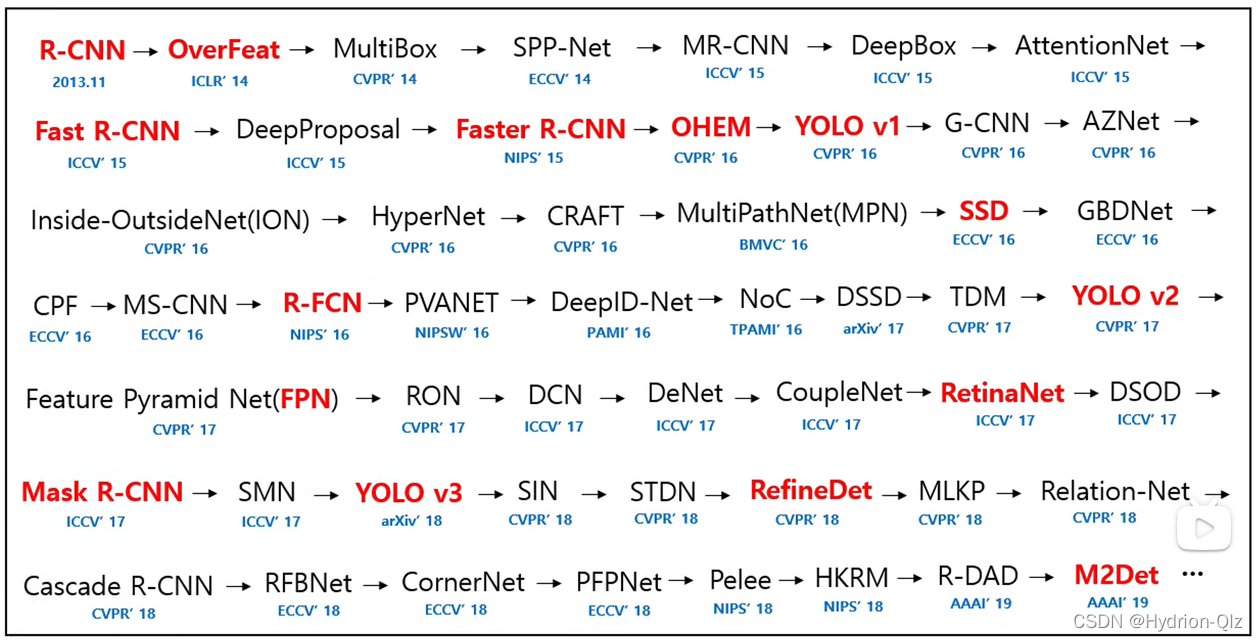
作者出于道德问题从YOLOv3开始将不再更新YOLO系列算法,俄罗斯的一位大佬Alexey Bochkovskiy接过了YOLO系列的这个任务的大旗,继续开创了后续的YOLOv4,后来ultralytics(西班牙的一个公司)提出了YOLOv5,2021年旷视可以又发布了YOLOx。最近又提出了YOLOv7,YOLO系列的发展可谓如火如荼呀。但是后面的YOLO系列基本上都是对YOLOv3的修修补补,没什么惊人的改变,目前工业界使用最多的还是YOLOv3。看下下面的图,YOLOv3和当时已经存的检测模型进行对比,YOLOv3的性能远好于其他的检测模型(是不是被作者给装到了)。

一.YOLOv3
接下来我们来介绍下YOLOv3的理论部分,其核心思想还是YOLOv2,对YOLOv2不足的地方进行了一些改进,如更换了提取特征的骨干网络,提升小目标检测能力。作者把YOLOv2里面的Darknet19换成了Darknet53网络,如下图所示,53表示总共53个卷积层。

下面我们来看下YOLOv3的骨干网络。从图中可以发现,作者使用了多尺度的一个特征提取,提取了三次特征,分别下采样了8倍,16倍和32倍。分别负责检测小目标,中等目标和大目标。骨干网络Darknet53的性能跟Resnet50相媲美,速度能达到Resnet50的两倍。
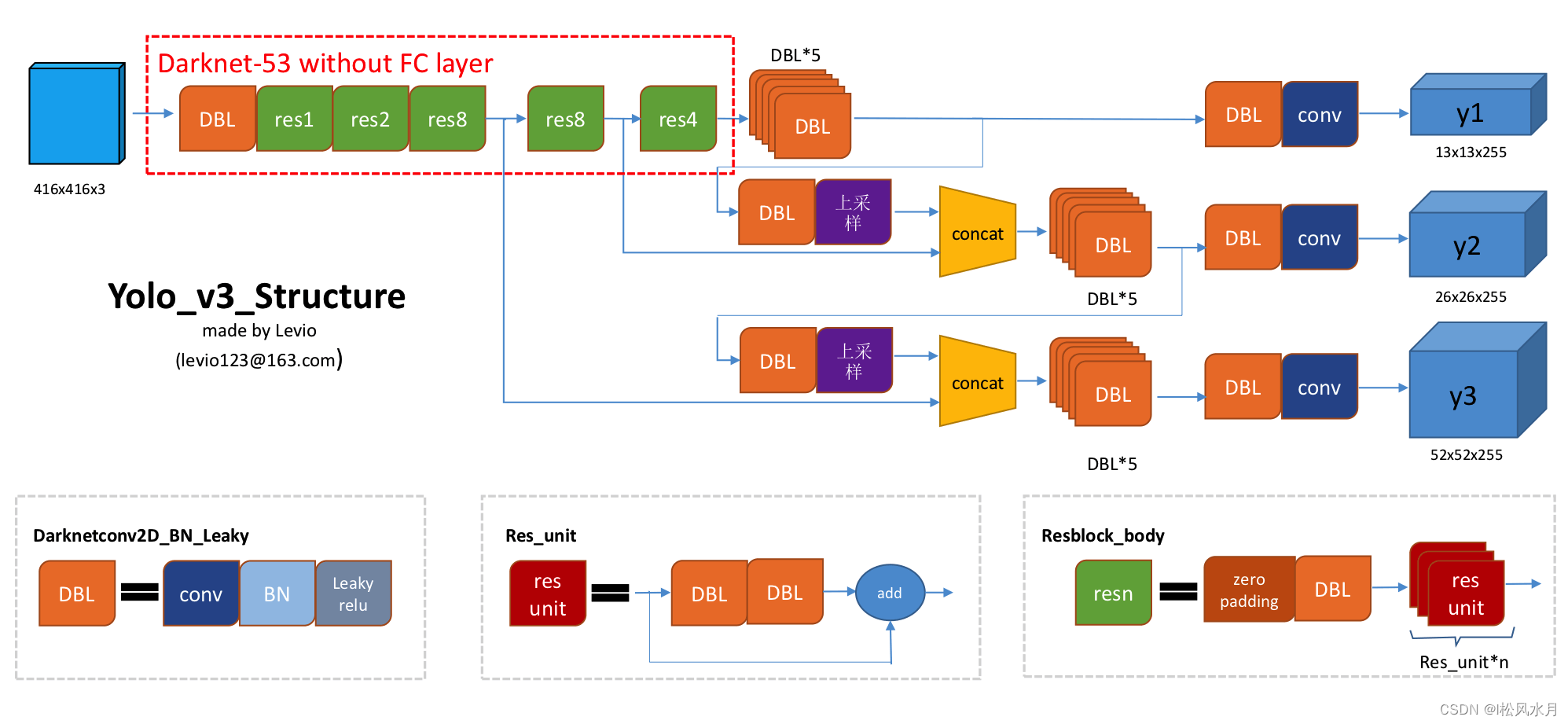
通过前面的讲解我们知道YOLOv1的输出是 7 × 7 × 30 7\times7\times30 7×7×30,YOLOv2的输出是 13 × 13 × 125 13\times13\times125 13×13×125,那么YOLov3的输出应该是什么样的呢?观察上面的YOLOv3的框图可以发现,YOLOv3跟前面的YOLOv1,YOLOv2有所不同。YOLOv3有三个输出特征层,分别负责检测大中小三个尺度的目标,提升了对小目标的检测能力。下面我们来解释下这三个输出特征层分别是什么意思。
- 13 × 13 × 255 13\times13\times255 13×13×255表示网络最后输出 13 × 13 13\times13 13×13个
grid,每个grid三个anchor,每个anchor对应一个预测框框,每个预测框又有4个位置坐标加上一个置信度参数,还有80个类别总共85个参数,3个anchor总共255个参数。这个特征层的感受野比较大,负责预测大物体。- 26 × 26 × 255 26\times26\times255 26×26×255,负责预测中等大小物体,其他参数解释同上。
- 52 × 52 × 255 52\times52\times255 52×52×255,负责预测小物体,其他参数解释同上。
观察上面的YOLOv3的整体网络框架,可以发现负责预测大目标的特征层融合了负责预测中等大小和大物体的特征层,负责预测中等大小目标的特征层融合了负责预测小目标的特征层。有点类似U-Net结构。上面的网络的具体结构我就不介绍了,我们主要讲下检测头的改进,其他部分自己看下就能看懂了,都是一些比较简单的常见的模块组合而成,最重要的还是要理解YOLOv3算法的核心,明白了YOLOv3算法,再看上面的图就很简单了。
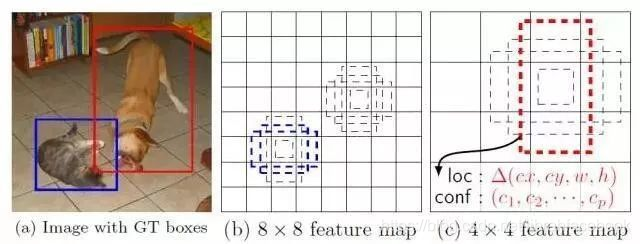
再次强调下上面的算法过程,总共三个输出特征层,每个输出特征层产生3个anchor,总共9个anchor,每个anchor对应一个预测框,每个预测框又有85个数,分别是4个坐标信息,1个置信度参数,80个类别条件类别概率。置信度参数跟80个类别条件类别概率相乘得到最终的预测概率,这里不懂的可以先移步到YOLOv1的那篇文章YOLOv1目标检测算法——通俗易懂的解析,看完再回来看这个YOLOv3。下图是一个检测头改进可视化图,跟YOLOv2整体思路大差不差,无非就是换了个骨干网络,输出三个特征层分别负责预测不同尺寸大小的目标。

下面我们以 13 × 13 13\times13 13×13为例来讲下怎么预测的。比如下面的柯基的中心点落在了红点所在的grid里面,那么就应该由这个红点所在的grid产生的三个anchor中的某一个去负责预测这个柯基。由这三个anchor中与柯基的 I o U IoU IoU最大的那个去负责拟合这个柯基。这个地方你会不会有疑问,YOLOv3不同于YOLOv2只有一个特征层,YOLOv3有三个尺寸的输出特征层,这三个尺度的特征层肯定都有一个ground truth落在各自的某一个grid的中心点,这个时候总共有9个anchor,那么究竟由哪个grid产生的anchor负责预测这个柯基呢?答案应该是由与人工标注框的 I o U IoU IoU最大的那个anchor他所在的那个gird去负责预测,其基本思想还是跟YOLOv2一样,YOLOv2只有一个输出特征层,由哪个grid负责预测是确定的,核心还是anchor。而YOLOv3里面直接比较anchor与ground truth的 I o U IoU IoU的大小来决定由哪个grid负责预测。即YOLOv3里面正样本是anchor与ground truth的 I o U IoU IoU最大的那个anchor,其他的非最大的就不是正样本,什么是正负样本我们下面再讲。

关于YOLOv3的核心算法上面已经讲过了,基本思想跟YOLOv2差不多,接下来我们来讲下YOLOv3的损失函数。上面我们讲了正样本是什么,那么负样本是什么呢?。与ground truth的 I o U IoU IoU最大的anchor记为正样本,与ground truth有一部分的 I o U IoU IoU,但不是最大的那个,就直接忽略他们,如果是与ground truth的 I o U IoU IoU小于某个阈值他们就记为负样本。如下图所示,红色是ground truth,只有黄色的正样本(最大的),绿色的被抛弃直接不用的(高不成低不就),蓝色和紫色的记为负样本(摆烂的)。

二.损失函数
下面我们再来看下YOLOv3的损失函数:
λ c o o r d ∑ i = 0 S 2 ∑ j = 0 B 1 i , j o b j ⋅ [ ( b x − b x ^ ) 2 + ( b y − b y ^ ) 2 + ( b w − b w ^ ) 2 + ( b h − b h ^ ) 2 ] ⋅ ( 2 − w i × h i ) + ∑ i = 0 S 2 ∑ j = 0 B 1 i , j o b j ⋅ [ − l o g ( p c ) + ∑ n = 1 n B C E ( c i ^ , c i ) ] + λ n o o b j ∑ i = 0 S 2 ∑ j = 0 B 1 i , j n o o b j ⋅ [ − l o g ( 1 − p c ) ] \lambda_{coord}\sum_{i=0}^{S^2}\sum_{j=0}^{B}1_{i,j}^{obj}\cdot[(b_{x}-\hat{b_{x}})^{2}+(b_{y}-\hat{b_{y}})^{2}+(b_{w}-\hat{b_{w}})^{2}+(b_{h}-\hat{b_{h}})^{2}]\cdot(2-w_{i}\times h_{i})\\+ \sum_{i=0}^{S^2}\sum_{j=0}^{B}1_{i,j}^{obj}\cdot[-log(p_{c})+\sum_{n=1}^{n}BCE(\hat{c_{i}},c_{i})]\\+\lambda_{noobj}\sum_{i=0}^{S^2}\sum_{j=0}^{B}1_{i,j}^{noobj}\cdot[-log(1-p_{c})] λcoordi=0∑S2j=0∑B1i,jobj⋅[(bx−bx^)2+(by−by^)2+(bw−bw^)2+(bh−bh^)2]⋅(2−wi×hi)+i=0∑S2j=0∑B1i,jobj⋅[−log(pc)+n=1∑nBCE(ci^,ci)]+λnoobji=0∑S2j=0∑B1i,jnoobj⋅[−log(1−pc)]
损失函数总共分为三项:(网上大佬根据代码总结的,原文作者并没给出损失函数,每个人写的可能不一样)
- 正样本的坐标损失,前面的 ( 2 − w i × h i ) (2-w_{i}\times h_{i}) (2−wi×hi)是为了惩罚小框,对小框赋予更大的损失。
- 正样本置信度和类别损失,这里正样本的置信度的标签就是
1,在前面的YOLOv1和YOLOv2中置信度都是预测框与ground truth的 I o U IoU IoU,在这里是只要是正样本,他的标签就是1。 ∑ n = 1 n B C E ( c i ^ , c i ) \sum_{n=1}^{n}BCE(\hat{c_{i}},c_{i}) ∑n=1nBCE(ci^,ci)表示正样本的类别损失直接使用二元交叉熵损失。- 负样本置信度,负样本的置信度标签为
0,和YOLOv1,YOLOv2都一样的。
简单总结写YOLOv3的训练和测试过程,基本思想其实和YOLOv2差不多。
YOLOv3的训练过程:
在模型训练过程中模型会输出10647个框,这10647个框分别对应10647个标签值。每个框的85个数都有对应的标签,训练的时候就是让这10647个框的每个里面的85个数和她对应的标签去拟合,用损失函数去计算。
YOLOv3的测试过程:
输入一张 416 × 416 416\times416 416×416的图片,获取三个输出特征层,在进行参数解析(置信度过滤+非极大值抑制)获得最终的目标检测结果。
YOLOv3的内容基本讲完了,YOLOv4等我下一篇文章吧,在此附一个YOLO系列的文章链接:
- YOLOv1目标检测算法——通俗易懂的解析
- YOLOv2目标检测算法——通俗易懂的解析
- YOLOv4目标检测算法——通俗易懂的解析
- YOLOv5目标检测算法——通俗易懂的解析
欢迎各位大佬批评指正!