1、主要贡献
主要是现有的一些trick的集合以及模块重参化和动态标签分配策略,最终在 5 FPS 到 160 FPS 范围内的速度和准确度都超过了所有已知的目标检测器。
当前目标检测主要的优化方向:更快更强的网络架构;更有效的特征集成方法;更准确的检测方法;更精确的损失函数;更有效的标签分配方法;更有效的训练方法。
2、主要思路
按照论文,目前模型精度和推理性能比较均衡的是yolov7 模型(对应的开源git版本为0.1版)。根据源码+导出的onnx文件+“张大刀”等的网络图(修改了其中目前我认为的一些bug,增加一些细节)。重新绘制了yoloV7 0.1版本的非常详尽网络结构。注意:
1)其中的特征图结果维度注释是按照箭头的流方向,不是固定的上下方向。
2)输入输出仅仅是指当前模块的输入输出,整体需要根据流方向累乘计算最终的结果。
3)该模型版本没有辅助训练头。
整体上和YOLOV5是相似的,主要是网络结构的内部组件的更换(涉及一些新的sota的设计思想)、辅助训练头、标签分配思想等。整体预处理、loss等可参考yolov5: 目标检测算法——YOLOV5_TigerZ*的博客-CSDN博客_目标检测yolov5
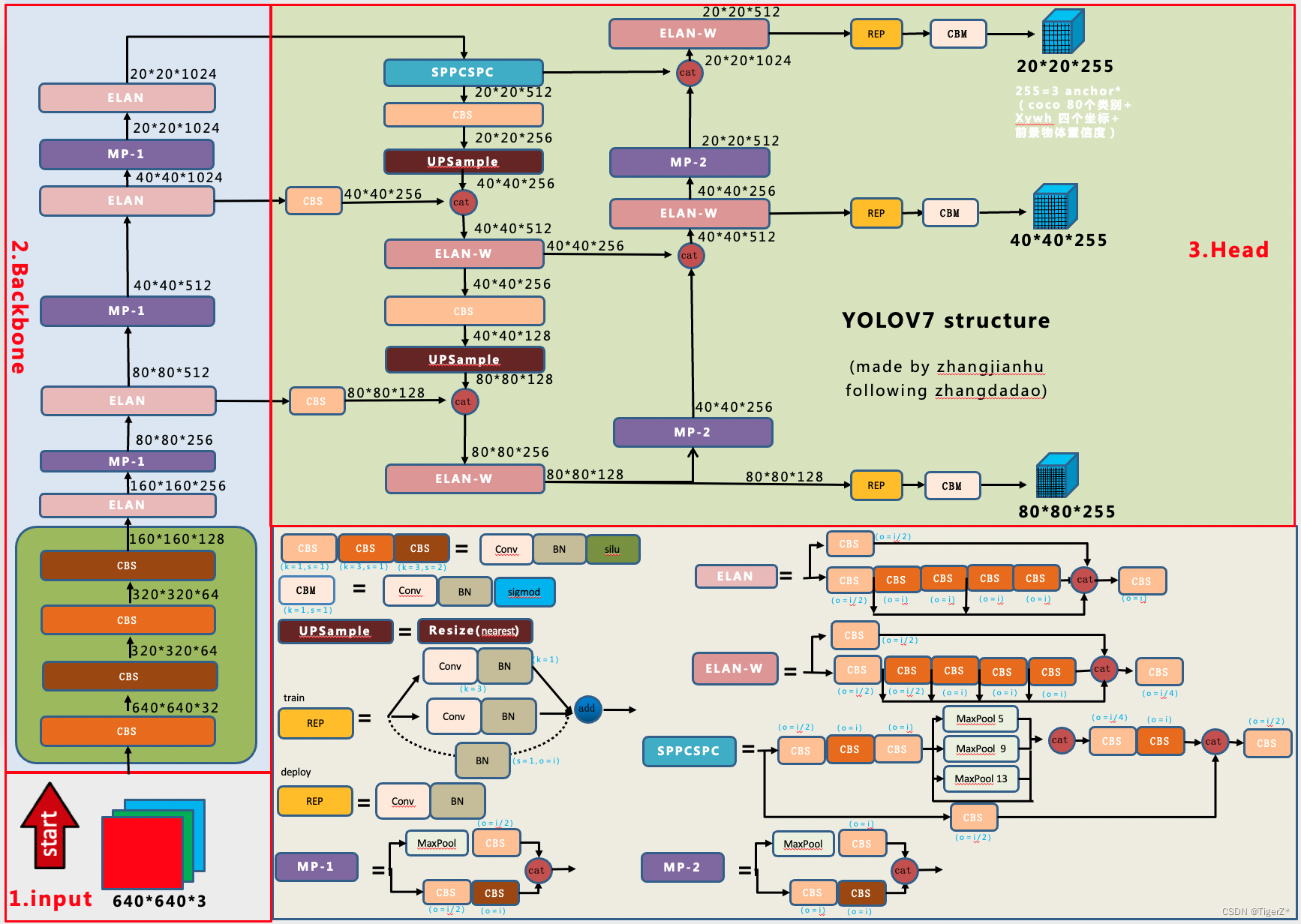
3、具体细节
1)input
整体复用YOLOV5的预处理方式和相关源码,唯一需要注意的是,官方主要是在640*640和1280*1280这样的相对较大的图片上进行的训练和测试。
具体参考我的另一篇YOLOV5博客中的 “具体细节” -> ‘input’ 章节即可。目标检测算法——YOLOV5_TigerZ*的博客-CSDN博客_目标检测yolov5
2)backbone
主要是使用ELAN(该版本模型并没有使用论文里提到的最复杂的E-ELAN结构) 和 MP 结构。该版本模型的激活函数使用的是Silu。
详细可以参考源码的 cfg/training/yolov7.yaml 文件 + models/yolo.py 文件 + 使用 export.py 导出onnx 结构使用 netron等软件来梳理。
a.ELAN结构
通过控制最短最长的梯度路径,更深的网络可以有效地学习和收敛。作者提出ELAN结构。基于ELAN设计的E-ELAN 用expand、shuffle、merge cardinality来实现在不破坏原有梯度路径的情况下不断增强网络学习能力的能力。(PS:该版本模型以及E6E网友反馈均未实现E-ELAN),论文中相关的图如下,其中的cross stage connection 其实就是1*1卷积:

简化如下:


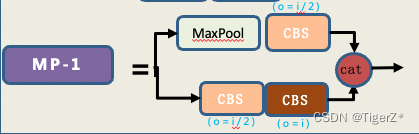
b.MP 结构
个人认为这是一个相对鸡贼的结构,之前下采样我们通常最开始使用maxpooling,之后大家又都选用stride = 2的3*3卷积。这里作者充分发挥:“小孩子才做选择,大人都要”的原则,同时使用了max pooling 和 stride=2的conv。 需要注意backbone中的MP前后通道数是不变的。
3)neck & head
检测头整体结构和YOLOV5类似,仍然是anchor based 结构,仍然没有使用YOLOX 和YOLOV6 的解耦头(分类和检测)思路,这一点目前不太理解,后续有精力可以魔改一下。主要是使用了:
*SPPCSPC结构
*ELAN-W(我自己命名非官方名字,因为基本上和ELAN类似,但是又不是论文中的E-ELAN)
*MP 结构(和backbone参数不同)
*比较流行的重参数化结构Rep结构
以上参见本篇博客中的“主要思路”中的整体图,里面就有可视化的这些部件,可以非常直观的理解这些结构。详细可以参考源码的 cfg/training/yolov7.yaml 文件 + models/yolo.py 文件 + 使用 export.py 导出onnx 结构使用 netron等软件来梳理。
4)loss function
主要分带和不带辅助训练头两种,对应的训练脚本是train.py 和 train_aux.py。
不带辅助训练头(分损失函数和匹配策略两部分讨论)。
损失函数
整体和YOLOV5 保持一致,分为坐标损失、目标置信度损失(GT就是训练阶段的普通iou)和分类损失三部分。其中目标置信度损失和分类损失采用BCEWithLogitsLoss(带log的二值交叉熵损失),坐标损失采用CIoU损失。详细参见utils/loss.py 里面的 ComputeLossOTA 函数 配合 配置文件里的各部分的权重设置。
匹配策略
主要是参考了YOLOV5 和YOLOV6使用的当下比较火的simOTA.
S1.训练前,会基于训练集中gt框,通过k-means聚类算法,先验获得9个从小到大排列的anchor框。(可选)
S2.将每个gt与9个anchor匹配:Yolov5为分别计算它与9种anchor的宽与宽的比值(较大的宽除以较小的宽,比值大于1,下面的高同样操作)、高与高的比值,在宽比值、高比值这2个比值中,取最大的一个比值,若这个比值小于设定的比值阈值,这个anchor的预测框就被称为正样本。一个gt可能与几个anchor均能匹配上(此时最大9个)。所以一个gt可能在不同的网络层上做预测训练,大大增加了正样本的数量,当然也会出现gt与所有anchor都匹配不上的情况,这样gt就会被当成背景,不参与训练,说明anchor框尺寸设计的不好。
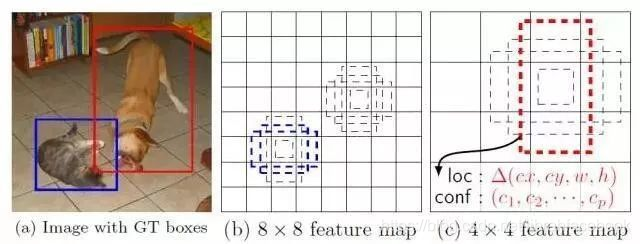
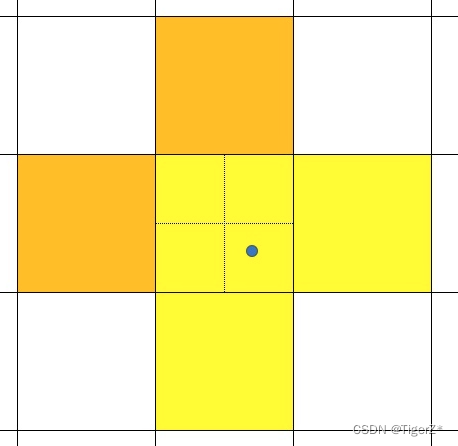
S3.扩充正样本。根据gt框的中心位置,将最近的2个邻域网格也作为预测网格,也即一个groundtruth框可以由3个网格来预测;可以发现粗略估计正样本数相比前yolo系列,增加了三倍(此时最大27个匹配)。图下图浅黄色区域,其中实线是YOLO的真实网格,虚线是将一个网格四等分,如这个例子中,GT的中心在右下虚线网格,则扩充右和下真实网格也作为正样本。
S4.获取与当前gt有top10最大iou的prediction结果。将这top10 (5-15之间均可,并不敏感)iou进行sum,就为当前gt的k。k最小取1。
S5.根据损失函数计算每个GT和候选anchor损失(前期会加大分类损失权重,后面减低分类损失权重,如1:5->1:3),并保留损失最小的前K个。
S6.去掉同一个anchor被分配到多个GT的情况。
带辅助训练头(分损失函数和匹配策略两部分讨论)。
论文中,将负责最终输出的Head为lead Head,将用于辅助训练的Head称为auxiliary Head。本博客不重点讨论,原因是论文中后面的结构实验实现提升比较有限(0.3个点),具体可以看原文。
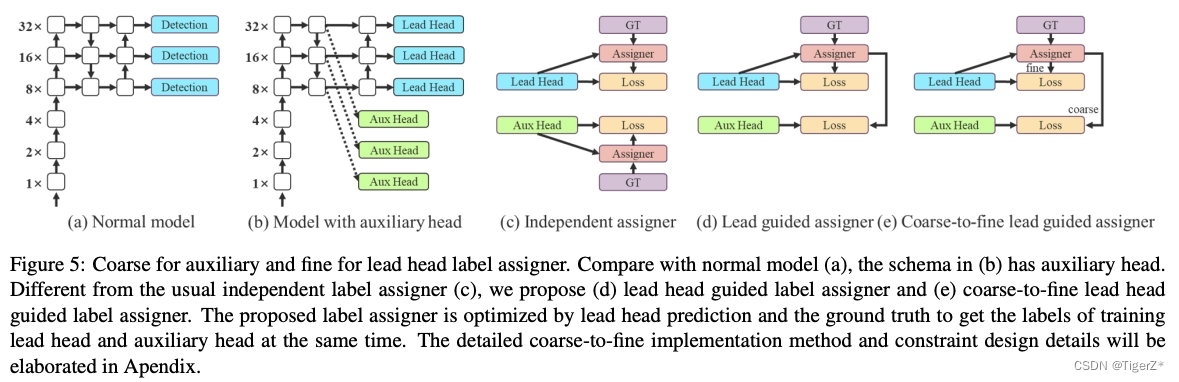
一些细节:其loss函数和不带辅助头相同,加权系数不能过大(aux head loss 和lead head loss 按照0.25:1的比例),否则会导致lead head出来的结果精度变低。匹配策略和上面的不带辅助头(只有lead head)只有很少不同,其中辅助头:
*lead head中每个网格与gt如果匹配上,附加周边两个网格,而aux head附加4个网格(如上面导数第二幅图,匹配到浅黄+橘黄共5个网格)。
*lead head中将top10个样本iou求和取整,而aux head中取top20。
aux head更关注于recall,而lead head从aux head中精准筛选出样本。
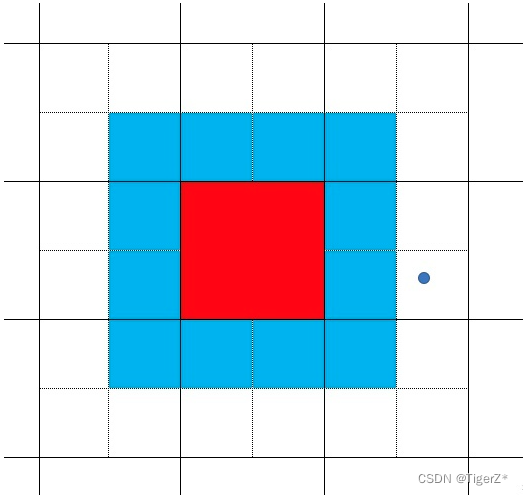
需要注意依照yolov5中的中心点回归方式,仅能将图中红色特征grid,预测在图中红色+蓝色区域(实线组成的网格代表着特征图grid,虚线代表着一个grid分成了4个象限),是根本无法将中心点预测到gt处(蓝色点)!而该红色特征grid在训练时是会作为正样本的。在aux head中,模型也并没有针对这种情况对回归方式作出更改。所以其实在aux head中,即使被分配为正样本的区域,经过不断的学习,可能仍然无法完全拟合至效果特别好。
5)trics
概述:ELAN设计思想、MP降维组件、Rep结构的思考、正负样本匹配策略、辅助训练头
6)inference
测试阶段(非训练阶段)过程
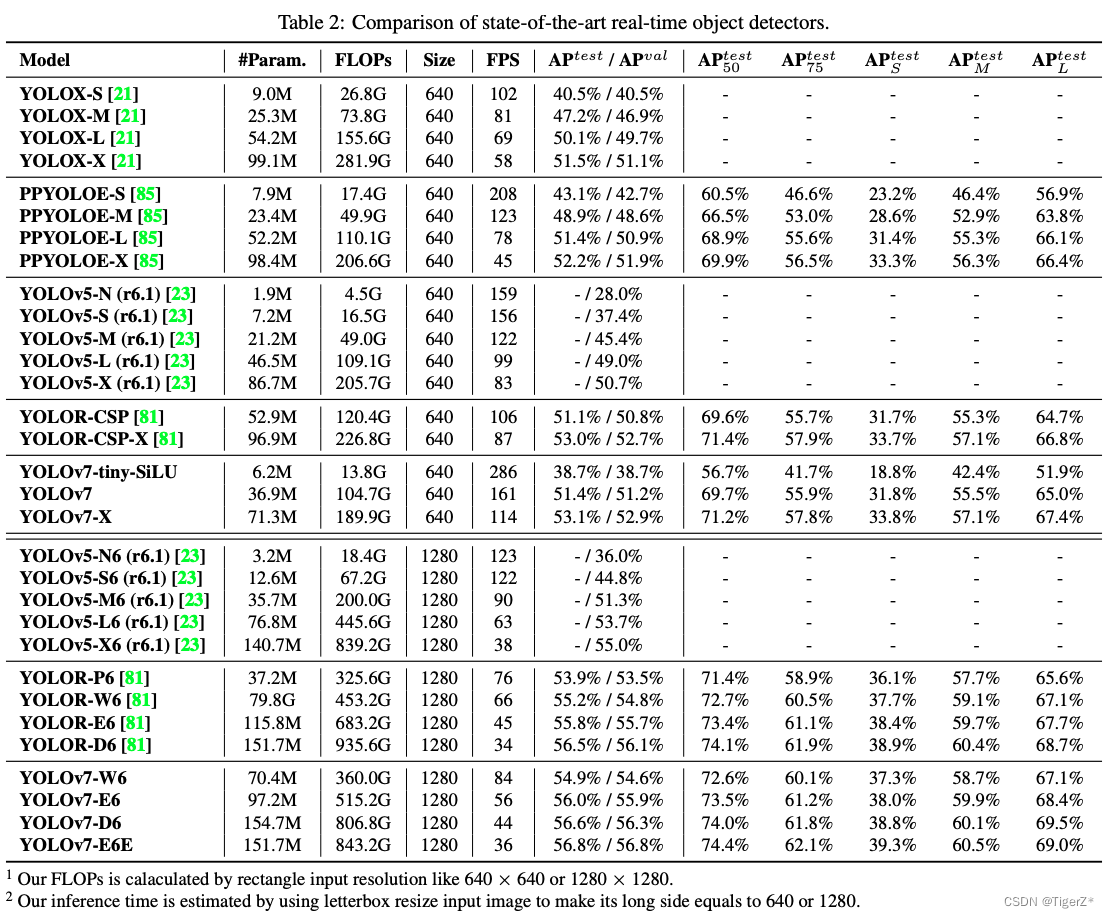
4、结果
打赏
你的打赏是我不断分享的动力,羞羞。点这里,嘿嘿。

参考连接
1、yolov7 网络架构深度解析_所向披靡的张大刀的博客-CSDN博客
2、https://d246810g2000.medium.com/%E6%9C%80%E6%96%B0%E7%9A%84%E7%89%A9%E4%BB%B6%E5%81%B5%E6%B8%AC%E7%8E%8B%E8%80%85-yolov7-%E4%BB%8B%E7%B4%B9-206c6adf2e69
3、【yolov7系列二】正负样本分配策略_所向披靡的张大刀的博客-CSDN博客+
4、https://arxiv.org/pdf/2207.02696.pdf
5、深入浅出 Yolo 系列之 Yolov7 基础网络结构详解 - 知乎
6、理解yolov7网络结构_athrunsunny的博客-CSDN博客
7、Yolov7算法卷土重来,精度速度超越所有Yolo算法,Yolov4作者全新力作!
8、深入浅出Yolov7之正负样本分配策略
9、yolov7正负样本分配详解 - 知乎
10、极市开发者平台-计算机视觉算法开发落地平台