一、基于候选区域的目标检测器
滑动窗口检测器
根据滑动窗口从图像中剪切图像块,把图像块处理成固定大小。随后输入CNN分类器中,提取特征。最后使用SVM分类器识别种类,并且用线性回归器得到边框。

选择性搜索selective search
首先将每个像素作为一组。
然后,计算每一组的纹理,并将两个最接近的组结合起来。
但是为了避免单个区域吞噬其他区域,我们首先对较小的组进行分组。我们继续合并区域,直到所有区域都结合在一起。
R-CNN
R-CNN 利用候选区域方法创建了约 2000 个 ROI。这些区域被转换为固定大小的图像,并分别馈送到卷积神经网络中。该网络架构后面会跟几个全连接层,以实现目标分类并提炼边界框。

比滑动窗口更快速、更准确。
边界框回归器

使用回归的方法,将蓝色边界框转变成红色边界框。

经过平移、缩放,得到回归窗口。
把A框经过映射,得到与真实窗口G框更接近的回归窗口G’。
Fast R-CNN
R-CNN缺点:需要非常多的候选区域以提升准确度,但其实有很多区域是彼此重叠的。对每个候选区域都要提取一次特征,速度很慢。
Fast R-CNN先用CNN提取整个图像的特征,再把SS应用到提取到的特征图上。这样只需要提取一次特征,加快了速度。

ROI池化
因为 Fast R-CNN 使用全连接层,所以我们应用 ROI 池化将不同大小的 ROI 转换为固定大小。

左上角:特征图
右上角:ROI(蓝色框)
左下角:将ROI拆成目标维度(这里是2*2)
右下角:找到每个部分的最大值,得到变换后的特征图
这样就把特征区域resize成固定大小了。
Faster R-CNN
Fast R-CNN缺点:使用SS,太慢了
Faster R-CNN 采用与 Fast R-CNN 相同的设计,只是它用内部深层网络代替了候选区域方法。新的候选区域网络(RPN)在生成 ROI 时效率更高。

流程图与Fast R-CNN相同,只是生成候选区域的方法不同。
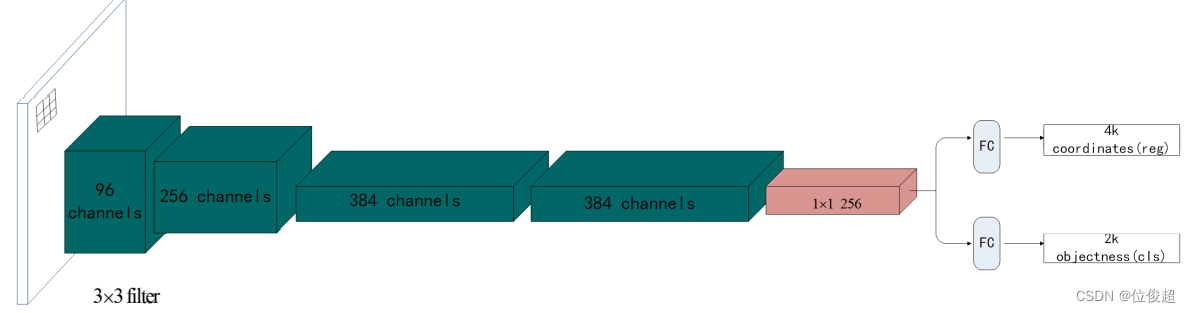
候选区域网络RPN
候选区域网络(RPN)将第一个卷积网络的输出特征图作为输入。
它在特征图上滑动一个 3×3 的卷积核,以使用卷积网络(如下所示的 ZF 网络)构建与类别无关的候选区域。其他深度网络(如 VGG 或 ResNet)可用于更全面的特征提取,但这需要以速度为代价。

ZF网络最后输出256个值,分别送入两个全连接层,以预测边界框和两个objectness 分数,这两个 objectness 分数度量了边界框是否包含目标(0或1)。
对于特征图中的每一个位置,RPN 会做 k 次预测。
因此4k表示,每次4个坐标,总共4k个参数。
2k表示,每个位置上0或1得分,总共2k个参数。
Faster R-CNN 使用更多的锚点。它部署 9 个锚点框:3 个不同宽高比的 3 个不同大小的锚点框。每一个位置使用 9 个锚点,每个位置会生成 2×9 个 objectness 分数和 4×9 个坐标。
基于区域的全卷积神经网络(R-FCN)
Faster R-CNN缺点:如果ROI数量过多,送入全连接层进行预测,速度太慢了。
因此R-FCN 通过减少每个 ROI 所需的工作量实现加速。
1、现有一个5x5的特征图M,内部包含一个蓝色方块。我们将蓝色方块划分成3x3个区域。

2、创建一个新的特征图,来检测方块的左上角。只有黄色区域是处于激活状态。

3、类似的,创建出9个特征图,来分别检测对应的目标区域。这些叫做位置敏感得分图。

4、红色虚线矩形是建议的 ROI,将其分割成3x3个区域,并用得分图来求每个区域包含目标对应部分的概论是多少。
例如,左上角 ROI 区域包含左眼的概率。


最后得到一个3x3的vote数组,这个过程叫做位置敏感ROI池化。
对ROI的每个区域,都进行一次映射后,得到了3x3个得分,最后计算所有元素得分的平均值。
(得分的意思,就是你这块区域是目标区域的概率。如,目标区域是检测眼睛的,这块区域是眼睛的概率是多少。因此,最后的平均分,就表示这个ROI区域是目标物体的概论)

假如我们有 C 个类别要检测。我们将其扩展为 C + 1 个类别,这样就为背景(非目标)增加了一个新的类别。每个类别有 3 × 3 个得分图,因此一共有 (C+1) × 3 × 3 个得分图。使用每个类别的得分图可以预测出该类别的类别得分。然后我们对这些得分应用 softmax 函数,计算出每个类别的概率。
二、单次目标检测器
第二部分,我们将对单次目标检测器(包括 SSD、YOLO、YOLOv2、YOLOv3)进行综述。
单次检测器
以前的滑动窗口检测器,有一个缺点,就是把窗口边界作为最终的边界框,这样无法准确定位目标。
更为有效的方法,就是把窗口当作初始的猜想,然后根据初始窗口得到预测类别和边界框的检测器。
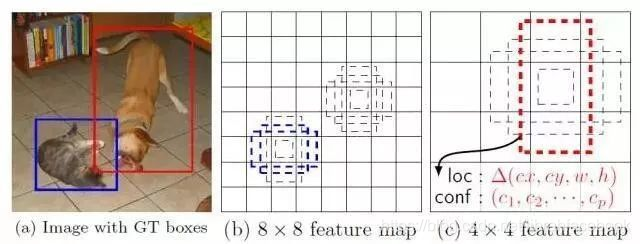
单次检测器会同时预测边界框和类别。
在 Faster R-CNN 中,卷积核做5个参数的预测:4个参数对应预测边框+1个目标得分,得到8 x 8 x 5。
现在单次检测器中,卷积核还预测C个类别概率以执行分类。因此得到特征图8 x 8 x(C+5)。
SSD
SSD 是使用 VGG19 网络作为特征提取器(和 Faster R-CNN 中使用的 CNN 一样)的单次检测器。
在该网络中,添加自定义卷积层(蓝色),并使用卷积核(绿色)进行预测。

但是,多个卷积层会降低维度和分辨率。为了解决该问题,从多个特征图上执行独立的目标检测。

YOLO
YOLO 在卷积层之后使用了 DarkNet 来做特征检测。

YOLO没有使用多尺度特征图,而将特征图部分平滑化,并将其和另一个较低分辨率的特征图拼接。例如,将一个 28 × 28 × 512 的层重塑为 14 × 14 × 2048,然后将它和 14 × 14 ×1024 的特征图拼接。之后,YOLO 在新的 14 × 14 × 3072 层上应用卷积核进行预测。
YOLOv3
YOLOv3 使用了更加复杂的骨干网络来提取特征。DarkNet-53 主要由 3 × 3 和 1× 1 的卷积核以及类似 ResNet 中的跳过连接构成。
YOLOv3 还添加了特征金字塔,以更好地检测小目标。