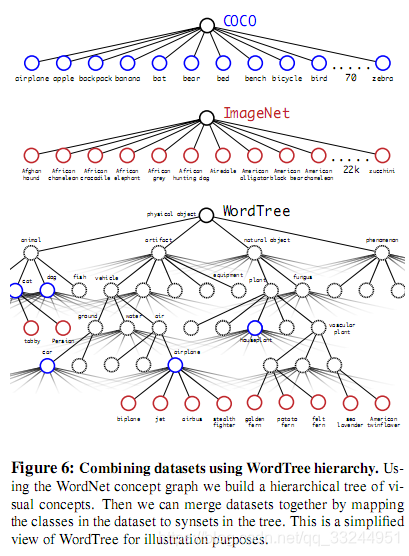
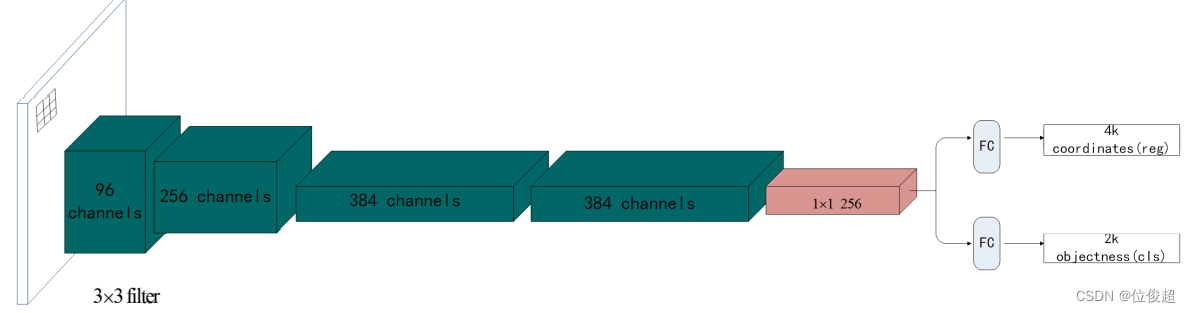
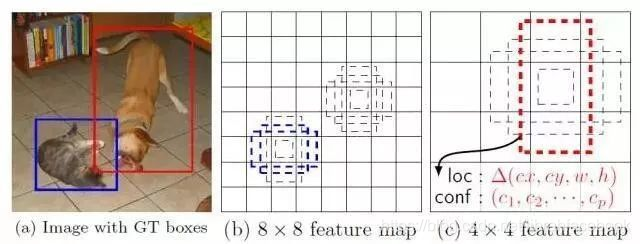
1、目标检测基本介绍
1.1、项目结构

1.2、目标检测的算法分类
1.2.1两步走的目标检测:先进行区域推荐、而后进行目标分类
代表算法 :R-CNN、 SPP-net、Fast-R-CNN、Faster R-CNN

1.2.2、端到端的目标检测:采用一种网络一步到位
代表:YOLO、SSD

1.3目标检测的本质
分类问题和目标检测问题的对比:
分类问题:
- N个类别
- 输入:图片
- 输出:类别
- 评估指标:准确率
目标检测问题:
- N个类别
- 输入:图片
- 输出:物体的位置坐标、物体的类别
- 评估指标:IOU

其中,计算出来的(x,y,w,h)的专有名词叫做bounding box(bbox):
物体的位置:
- x、y为物体的中心点位置,w、h为中心点到能够完整把物体框住的几何框的边的距离。
- xmin、ymin、xmax、ymax,物体位置的左上角坐标和右下角坐标。
1.4、目标检测实现思路

如下图所示:

1.5、两种Bounding box的名称
在目标检测中,对于bbox主要有两种类别;
- Ground-Truth bounding box:图片中的真实标记框
- Predicted bounding box:预测标记框
一般在目标检测当中,我们预测的框可以有很多GRE,真实框也肯定有很多个。
2、目标检测算法-RCNN
2.1、R-CNN
对于多个目标的情况下,就不能以 固定个数输出物体的位置值,那么如何解决这个问题呢?解决方法如下:
2.1.1目标检测-Overfeat模型
2.1.1.1 滑动窗口
原理: 目标检测的暴力方法是从左到右,从上到下利用分类识别目标,为了检测不同形状大小的目标类型,我们使用不同大小和宽高比的窗口去在图片上滑动,类似于截取图片的,每滑动一次截取一次,因此会涉及K类目标框设置的参数。然后进行利用这些图片进行分类。类别作为目标的类别,截取的框作为目标检测的框,完成图片上多目标检测的任务。
该算法的缺陷:类似于暴力穷举的方式,需要消耗大量计算资源,窗口大小设置很难精确。可以作为一种原始的目标检测方法。
2.1.2、目标检测——R-CNN
2.1.2.1、具体步骤
- 粗分析,获取含有目标的候选区域,默认2000个;
- 规整,将候选区域进行规整到适合AlexNet网络的227*227,利用CNN进行特征向量提取,AlexNet输出为2000*4096;
- 分类:2000*4096送入SVM分类器进行分类(svm为二分类器,采用多个SVM进行组合实现多分类),然后选用非极大抑制进行优化,目的是剔除重叠的候选区域,得到与目标物体最高的 一些候选区域;
- 修正:修正bbox,对于bbox做回归微调
具体步骤细化解释:
粗分析: 1)候选区的获取:利用选择性搜索算法(SS算法),该算法的逻辑是利用图像像素点的相似性进行逐级合并的方法实现,首先将每个像素点作为一组,然后利用想进像素点相似性进行合并,为了避免大面的相似点吞并小的区域,优先对于较小的组进行 分组,然后继续合并区域,直到所有区域都合并在一起, 完成候选区域的选择。然后基于此在图片上获取默认2000张候选区域。
2)由于1)获得的候选集区域的形状大小不一致,因此需要对于候选区域进行变换,本质也是对于图像进行填充等操作,保证候选区域 大小一致,方便下一步的模型训练。

3)CNN网络提取特征
利用CNN网络进行2)处理的图像她特征提取,获取更高级特征向量,这些特征向量送入分类器、回归的数据数据。
4)特征向量的分类
R-CNN采用的是SVM二分类器,每个分类器负责分类一个类别,需要分类多少个类别就有多少个分类器。每个候选区域分别送入每个分类器及计算出来不同分类器的概率,选取最大的一个作为最终的类别。
5)非极大抑制(NMS)
目的:筛选候选区域框,目的是一个物体只保留一个最优的框,来抑制那些冗余的候选框。采用的候选框和真实框的占比,重叠越多说明该候选框越好。但是这个方法也是存在问题,当候选框大于真实框很多,并且能够完整框住物体,但是这类框严格意义上是不精确的,需要及进一步优化。
6)修正候选区域

此处如何回归呢?利用非极大一致法选取的最有候选边框坐标,然后依据该坐标和真实标注的框坐标进行回归运算,计算(Wx,Wy,Ww,Wh)参数,后期预测数据利用该参数进行回归预算,将处理后的坐标数据作为最终的物体边框坐标数据。
2.2、目标检测的评估指标
2.2.1、IoU交并比


通常识别正确:类别正确且IoU>0.5.
2.2.2、平均精确率(mean average precision)map
训练样本标记:候选框的标记方法,每个候选区域的IoU>0.7的标记为正样本,否则标记为负样本 。
定义:map为多个分类任务的AP平均值。
map=所有类别的AP之和/类别的总数
说明:AP指的是曲线下的面积(AUC曲线),AUC(Area Under Curve)被定义为ROC曲线下与坐标轴围成的面积,显然这个面积的数值不会大于1。又由于ROC曲线一般都处于y=x这条直线的上方,所以AUC的取值范围在0.5和1之间。AUC越接近1.0,检测方法真实性越高;等于0.5时,则真实性最低,无应用价值。
AUC(Area Under Curve)被定义为ROC曲线下的面积。我们往往使用AUC值作为模型的评价标准是因为很多时候ROC曲线并不能清晰的说明哪个分类器的效果更好,而作为一个数值,对应AUC更大的分类器效果更好。
其中,ROC曲线全称为受试者工作特征曲线 (receiver operating characteristic curve),它是根据一系列不同的二分类方式(分界值或决定阈),以真阳性率(敏感性)为纵坐标,假阳性率(1-特异性)为横坐标绘制的曲线。
总结:
R-CNN在VOC2007年数据集上的表现map达到0.66,到目前为止也是很有优势的一个结果。
缺点:
- 训练阶段多:步骤繁琐:微调网络+训练SVM+训练边框回归分类器。
- 训练耗时:占用磁盘大,训练参数多
- 处理速度慢:使用GPU,VGG16模型处理一张图片需要47s。
- 图片形状变换:候选区域要经过crop/warp进行固定大小,无法保证图片不变形。
3、R-CNN改进-SPPNet
分析R-CNN慢的主要耗时在卷积运算,由于每张图片都要提取默认的2000个候选区域,实质一张图上不会有那么多对象,但是RCNN每次都需要卷积2000次。(候选区域依据采用R-CNN 算




另外的一出的改进:空间金字塔池化(spatial pygramid pooling)


4、Fast R-CNN(也是对于R-CNN的改进)
SPPNet的性能已经 得到很大程度上改善,但是由于网络之间 不统一训练,造成很大麻烦,所以接下来的fast R-CNN就是为了解决这个问题。(候选区域依据采用R-CNN 算法的方法,仅仅是做了映射)


4.1Fast R-CNN的改进
1)使用了softmax分类器,类别中加入背景类别;
2)使用了RoI-projection操作,这个操作和SPPNet算法中空间金字塔池化(spatial pygramid pooling)是一样的,不同点是只取了一种池化的,提取了一个固定长度的特征向量。
多任务损失-Multi-task loss:
 多任务损失就是将上面分类损失和回归损失加起来,作为最终的损失。
多任务损失就是将上面分类损失和回归损失加起来,作为最终的损失。
4.2、Fast R-CNN的效果对比

Fast R-CNN算法的原理图

缺点:候选区域的提取依旧选用的是Selective Search提取Regionproposals,没有实现真正意义上的端对端 ,操作 也十分耗时。
5、Faster R-CNN算法









6、YOLO算法
6.1、目标检测性能对比

6.2、YOLO结构

流程理解:
1)原始图片resize到448*448,经过前面的卷积网络之后,将图片输出成了一个7*7*30的结构
2)默认分割成7*7的单元格
3)每个网格给出两个bbox,这里以3*3的单元格做演示;

4、进行NMS筛选,筛选出概率以及IoU的;
5、得到两个候选框

 7*7*30的理解:7*7表示模型最终输出是将图像出来后转化成7*7个单元格,每个单元格深度为30是什么意思呢,这个30的由来:每个单元格给出两个bbox,每个bbox有4个坐标点,同时又1个置信度,那么两个bbox就有10个值,另外20个值是分类的20个类别概率值。
7*7*30的理解:7*7表示模型最终输出是将图像出来后转化成7*7个单元格,每个单元格深度为30是什么意思呢,这个30的由来:每个单元格给出两个bbox,每个bbox有4个坐标点,同时又1个置信度,那么两个bbox就有10个值,另外20个值是分类的20个类别概率值。
6.3、网络的输出筛选
最终网络的输出为 7*7*30,每个网格会预测两个bbox,在训练的时候只有一个bbox专门负责类别的预测,具体采用那个bbox,根据每个bbox置信度进行筛选,获取最大的bbox。其中置信度的大小是根据IoU的值替代。
因此,YOLO网络的输出为7*7*25,其中7为单元格数,25为筛选出置信度大的bbox4个坐标、1个置信度、20个类别。

损失函数:
1)bbox 4个坐标,采用回归的均方误差作为损失函数
2)1个置信度,采用回归的均方误差的损失函数
3)20个类别采用交叉熵损失函数计算损失
以上三个损失函数和作为模型最终的损失,进行GoogleNet+4个卷积+2个全连接网络的参数更新。

YOLO网络对于最终的输出是7*7*25(其中5表示候选区域的3个坐标和置信度,20是对象的类别数),并且每个单元格中默认只存在一个物体,因此对于物体挨的比较近或者物体比较小落在一个单元格中将识别不出来的问题。因此YOLO算法适合识别图像上物体不相对比较稀疏、分散的的场景下。优势是识别速度非常快,准确率也比较好。 缺点就是对于小的物体和密集的物体识别比价差。
7、SSD算法原理



可以这样理解,SSD算法从不同尺寸的特征图上进行预测一系列的bbox和类别,大的物体采用大点尺度的特征矩阵进行识别,小一点的物体可以采用小一点的尺度的特征矩阵进行识别。



默认每个单元格预测3个候选框,因此有5*5*3=75个候选框。



 \
\
1、YOLO算法评估指标
目标检测算法通常有两种评估指标:FPS 、MAP:
FPS:反映模型的检测速度,目标网络每秒可以处理(检测)多少帧(多少张图片),FPS简单来理解就是图像的刷新频率,也就是每秒多少帧,假设目标检测网络处理1帧要0.02s,此时FPS就是1/0.02=50张。
MAP:实际上是对测试集来评估的,主要是计算测试集和测试集的预测结果的准确率,指标是测试集中的真实框和目标是否检测出来,对于预测结果中的预测框和测试集中的真实框的IOU检测大于阈值,就判定这个框框和目标为TP即分类正确的正样本,其他的预测结果(预测框和真实框小于阈值)判定为FP负样本,而测试集中未被检测出来的目标和真实框(就是测试集标记的目标和框框减去预测正确的目标和框框)的就为FN。