目录
- YOLOv5目标检测算法
- 前沿
- 一.网络结构
- 1.1.Backbone
- 1.2.Neck
- 1.3.Head
- 二.数据增强
- 2.1.Mosaic
- 2.2.Copy paste
- 2.3.Random affine
- 2.4.Mixup
- 2.5.Albumentation
- 2.6.Augment HSV
- 2.7.Random horizontal flip
- 三.训练策略
- 3.1.Multi-scale training
- 3.2.Auto anchor
- 3.3.Warmup and Cosine
- 3.4.EMA
- 3.5.Mixed presion
- 3.5.Evolve hype-parameters
- 四.损失函数
YOLOv5目标检测算法
前沿
前四篇文章我们讲了下关于YOLOv1、YOLOv2、YOLOv3、YOLOv4的原理,有不懂的小伙伴可以回到前面再看看:
- YOLOv1目标检测算法——通俗易懂的解析
- YOLOv2目标检测算法——通俗易懂的解析
- YOLOv3目标检测算法——通俗易懂的解析
- YOLOv4目标检测算法——通俗易懂的解析
这篇文章我们来介绍下YOLOv5算法的理论部分,看下YOLOv5又做了哪些改进。前面重复过好几次了,YOLOv3后面的一系列YOLO算法都是基于YOLOv3的一些小改动,核心还都是YOLOv3算法。YOLOv5也是代码先于论文推出,各位小伙伴们可能会在网上看到不少YOLOv5的版本讲解都会有一些小的不同,并且YOLOv5的官网现在针对YOLOv5也推出了不少版本。在我写这篇博文的时候就已经推出了YOLOv5的6.2版本了,不过本博文仍然按照6.1的版本,个位小伙伴们看的YOLOv5如果不是6.1版本可能会有些出入的地方,但问题不大。YOLOv5的官方代码地址如下:YOLOv5。
我们先来看张图,先看下YOLOv5的性能。可以看到速度和mAP都已经很高了。
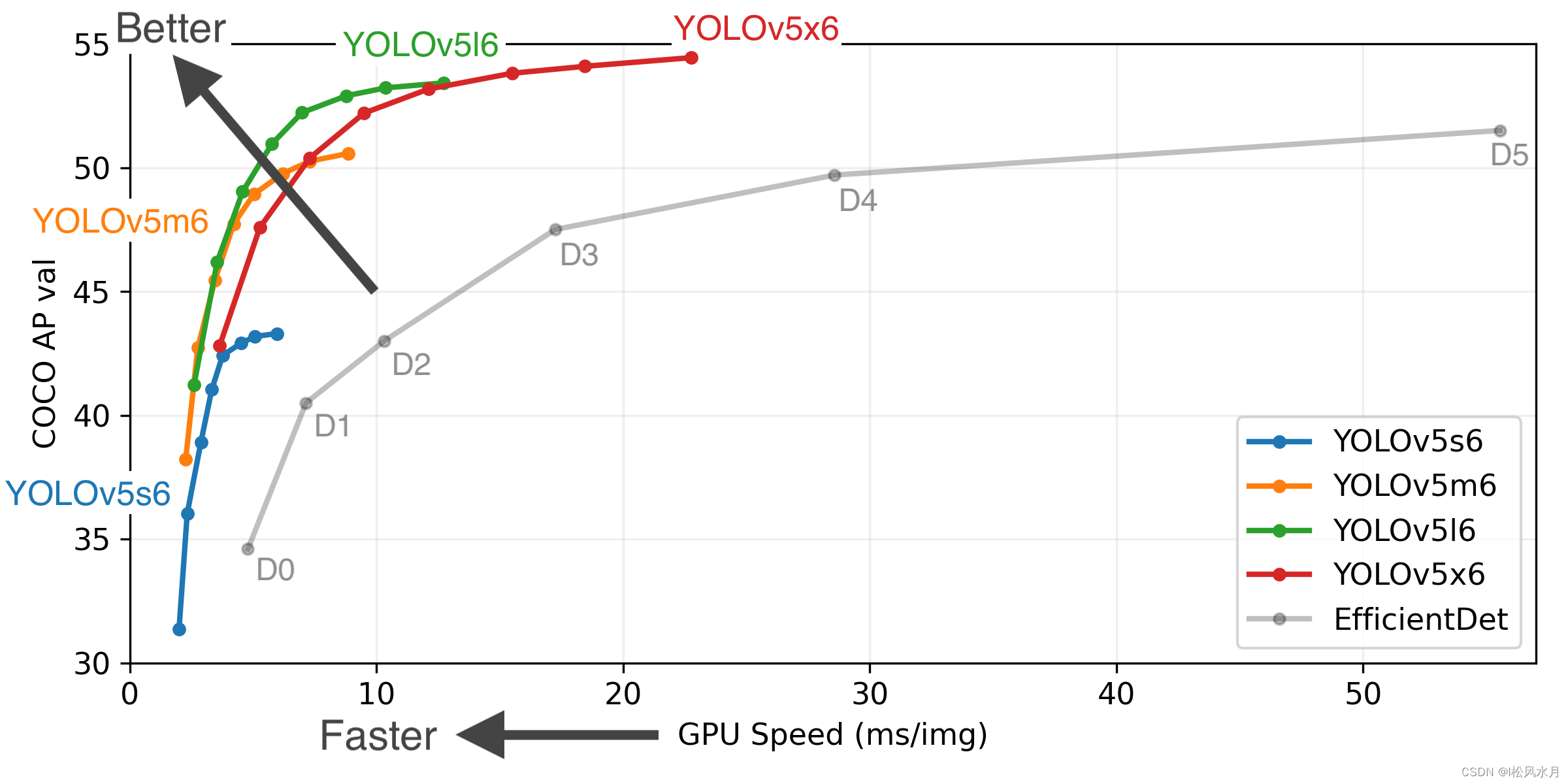
接下来我们来介绍下YOLOv5。本文主要从YOLOv5的网络结构,数据增强,训练策略,以及损失函数等方面去介绍,其他部分跟前面YOLOv1-v4算法重复的地方不在赘述。
一.网络结构
下面先放着一张噼里啪啦大佬绘制的YOLOv5(6.1)版本的网络结构图。可以看到跟YOLOv4的整体结构看着还是很相似的,整体上没太大变化。

1.1.Backbone
改进版的Darknet53,
1.2.Neck
SPP换成了SPPF,PAN换成了CSP-PAN。
1.3.Head
Head仍然是YOLOv3的head结构。
注意:
Focus被换成 6 × 6 6\times6 6×6大小的卷积层,功能相同,只不过 6 × 6 6\times6 6×6卷积效率更高。看下面的图,是不是很熟悉,Focus模块跟YOLOv2里面的Fine-Grained Features很像。
首先将宽高变为原来一半,通道翻倍。

下面在看一个SPPF。在讲SPPF之前我们先回顾下SPP,之前讲的SPP是将输入的多个特征层并行的通过大小不同的maxpool2d,然后再跟原是输入的特征concat。但是SPPF是怎么做的呢?SPPF是将输入的特征串行的通过maxpool2d。最后再做concat拼接。你有没有疑问,为什么一定要串行呢,并行为什么没有串行好呢?因为两个 5 × 5 5\times5 5×5大小的maxpool2d串行一块等价于一个 9 × 9 9\times9 9×9的maxpool2d。如果是三个 5 × 5 5\times5 5×5的maxpool2d串行一块的话就等价于一个 13 × 13 13\times13 13×13的maxpool2d。这样的话是不是直接通过串行maxpool2d就可以实现并行maxpool2d实现的功能。是不是提高了效率,降低了计算参数。


二.数据增强
上面介绍了网络结构的部分的改进,下面我们再来介绍下数据增强部分。
2.1.Mosaic
Mosaic数据增强,这个已经讲烂掉了,不再过多赘述。
2.2.Copy paste
用一句话概括他,就是把一张图像的目标抠出来粘贴到另一张图像上。需要注意的是数据集必须要有实例分割的标签。
2.3.Random affine
随机仿射变换,如旋转,平移等。
2.4.Mixup
简言之就是将两幅图像按照一定的比例混合成一张新的图像。
2.5.Albumentation
Albumentation是一个比较强大的数据增强库,关于Albumentation更详细的介绍可以参考我的另一篇博文:pytorch结合albumentations在图像分割中的应用。
2.6.Augment HSV
随机调整色调,饱和度和明度。
2.7.Random horizontal flip
随机水平翻转。
上面介绍了一些关于YOLOv5的数据增强的方法,下面我们在来看下YOLOv5使用的一些训练策略。仅仅介绍YOLOv5里面用到的一些典型的训练策略。
三.训练策略
- Multi-scale training
- Auto anchor
- Warmup and Cosine LR scheduler
- EMA
- Mixed presion
- Evolve hype-parameters
3.1.Multi-scale training
对训练数据集按照 0.5 − 1.5 × 0.5-1.5\times 0.5−1.5×的不同尺度进行训练,随机取值只取32的整数倍。
3.2.Auto anchor
重新根据自己的数据集聚类生成相应尺寸的anchor。
3.3.Warmup and Cosine
Warmup表示在训练的初期将学习率从一个比较小的值慢慢生长为我们设置的学习率。Cosine LR scheduler表示以cos的形式慢慢降低学习率。
3.4.EMA
将学习率加上一个动量
3.5.Mixed presion
混合精度训练,可以参考apex的使用。
3.5.Evolve hype-parameters
超参数,大神可以自己炼丹。
上面讲了数据增强,训练策略,下面我们再来看下YOLOv5的损失函数。
四.损失函数
YOLOv5的损失函数主要包含三个部分:分类损失,目标损失,定位损失。分类损失和目标损失采用的都是BCE loss,定位损失采用的是CIoU loss。不懂CIoU损失的可以移步到我的另一篇博文:IoU的进化之路。在目标损失里面使用的是obj损失,obj指的是网络预测的目标边界框与Ground的CIoU,这里计算所有样本的obj损失。我们之前在讲YOLOv3,YOLOv4计算目标损失的时候都是anchor里面是否有目标,有目标就将其设置为1,没目标就将其设置为0。YOLOv5里面使用的是CIoU,计算所有样本的obj损失。
L o s s = λ 1 L c l s + λ 2 L o b j + λ 3 L l o c Loss = \lambda_{1}L_{cls}+\lambda_{2}L_{obj}+\lambda_{3}L_{loc} Loss=λ1Lcls+λ2Lobj+λ3Lloc
下面我们再来看下平衡不同尺度损失,针对三个预测特征层 ( P 3 , P 4 , P 5 ) (P_{3},P_{4},P_{5}) (P3,P4,P5)上的obj损失采用不同的权重,用来预测不同尺寸大小的目标。基本上跟前面讲的损失函数大差不差。
L o b j = 4.0 L o b j s a m l l + 1.0 L o b j m e d i u n + 0.4 L o b j l a r g e L_{obj}=4.0L_{obj}^{samll}+1.0L_{obj}^{mediun}+0.4L_{obj}^{large} Lobj=4.0Lobjsamll+1.0Lobjmediun+0.4Lobjlarge
消除Grid敏感度
下面我们再来讲下消除Grid敏感度的问题。在YOLOv5里面作者做了两个变化,其中一个我们在YOLOv4里面讲过。不懂的可以跳转到YOLOv4目标检测算法——通俗易懂的解析里面的Eliminate grid sensitiy小节查看。另一个改进是对 b w = p w e t w , b h = p h e t h b_{w}=p_{w}e^{t_{w}},b_{h}=p_{h}e^{t_{h}} bw=pwetw,bh=pheth的改进,将之前的 b w = p w e t w , b h = p h e t h b_{w}=p_{w}e^{t_{w}},b_{h}=p_{h}e^{t_{h}} bw=pwetw,bh=pheth改进为:
b w = p w ( 2 σ ( t w ) ) 2 b h = p h ( 2 σ ( t h ) ) 2 b_{w}=p_{w}(2\sigma(t_{w}))^{2}\\ b_{h}=p_{h}(2\sigma(t_{h}))^{2} bw=pw(2σ(tw))2bh=ph(2σ(th))2
观察修改之前和修改之后的函数表达式可以刚发现,修改之前的 b w 和 b h b_{w}和b_{h} bw和bh是不受限制的,就有可能会出现梯度爆炸的情况,就有可能出现损失为None和训练不稳定的情况。而修改之后的 b w 和 b h b_{w}和b_{h} bw和bh则被限制在了(0,4)之间,就不会出现计算损失为None和训练不稳定的情况。
匹配正样本
下面我们再来讲下匹配正样本的内容。内容基本上跟之前在YOLOv3/v4里面讲的一样,在此我们只讲下不同的地方。不同之处就在于anchor模板和GT进行匹配的过程。在YOLOv4里面是将GT和每个anchor模板的左上角对齐,然后计算IoU,如果IoU大于所设置的阈值,就将GT分配给所对应的模板。但是在YOLOv5里面是先计算GT和每个模板的宽度比值和高度比值。然后再分别计算 r w 和 1 r w r_{w}和\frac{1}{r_{w}} rw和rw1的最大值, r h 和 1 r h r_{h}和\frac{1}{r_{h}} rh和rh1, r w m a x 和 r h m a x r_{w}^{max}和{r_{h}^{max}} rwmax和rhmax的最大值。公式如下:
r w = w g t / w a t r h = h g t / h a t r w m a x = m a x ( r w , 1 r w ) r h m a x = m a x ( r h , 1 r h ) r m a x = m a x ( r w m a x , r h m a x ) r_{w}=w_{gt}/w_{at}\\ r_{h}=h_{gt}/h_{at}\\ r_{w}^{max}=max(r_{w},\frac{1}{r_{w}})\\ r_{h}^{max}=max(r_{h},\frac{1}{r_{h}})\\ r^{max}=max(r_{w}^{max},r_{h}^{max}) rw=wgt/watrh=hgt/hatrwmax=max(rw,rw1)rhmax=max(rh,rh1)rmax=max(rwmax,rhmax)
其他部分同YOLOv4。
至此,YOLOv1-YOLOv5的理论部分已经完结了,欢迎各位大佬的支持,同时欢迎个位大佬提出批评指正。