在项目迭代的过程中,不可避免需要“上线”。上线对应着部署,或者重新部署;部署对应着修改,修改则意味着风险。应用程序升级面临最大挑战是新旧业务切换,将软件从测试的最后阶段带到生产环境,同时要保证系统不间断提供服务。如果直接将某版本上线发布给全部用户,一旦遇到线上事故(或BUG),对用户的影响极大,解决问题周期较长,甚至有时不得不回滚到前一版本,严重影响了用户体验。
长期以来,业务升级逐渐形成了几个发布策略:灰度发布(金丝雀发布)、蓝绿发布、A/B测试、滚动升级以及分批暂停发布,尽可能避免因发布导致的流量丢失或服务不可用问题。
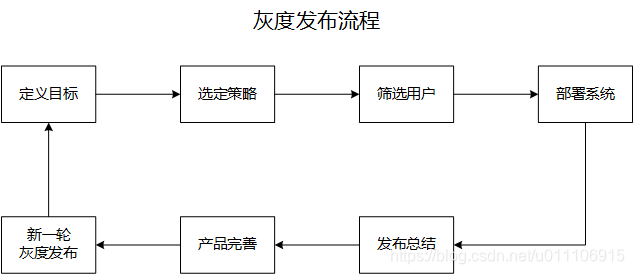
灰度发布
定义:
灰度发布(又名金丝雀发布)是指在黑与白之间,能够平滑过渡的一种发布方式。在其上可以进行A/B testing,即让一部分用户继续用产品特性A,一部分用户开始用产品特性B,如果用户对B没有什么反对意见,那么逐步扩大范围,把所有用户都迁移到B 上面来。灰度发布可以保证整体系统的稳定,在初始灰度的时候就可以发现、调整问题,以保证其影响度。
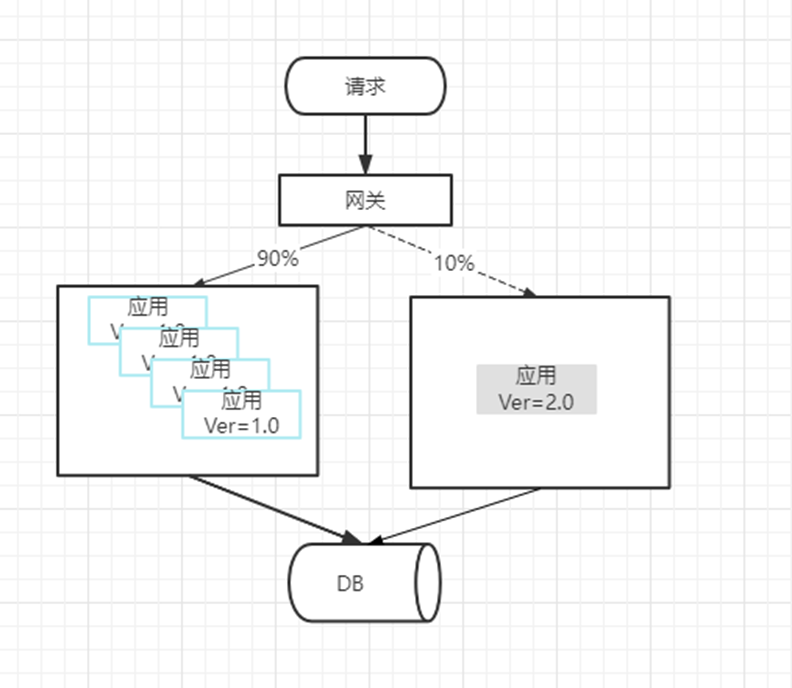
网关可以按照流量比例权重进行路由,也可以按照请求内容规则进行路由。
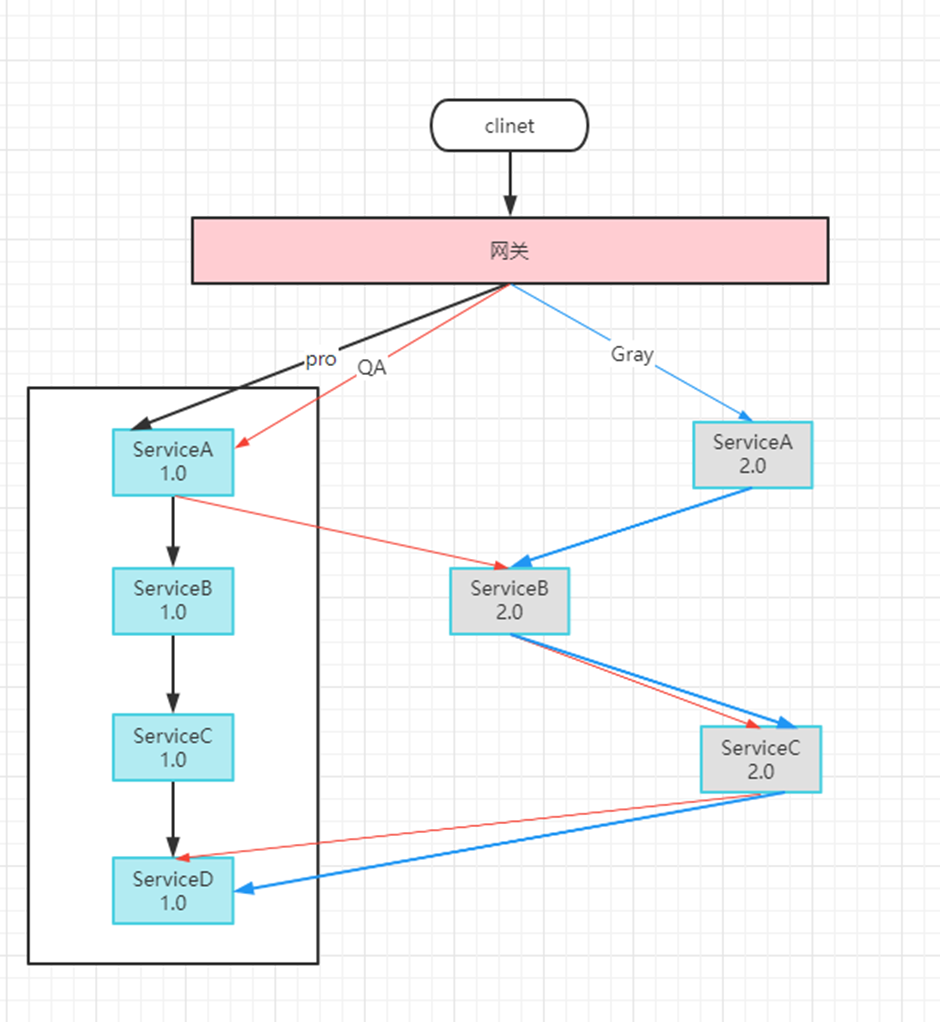
但是,在实际场景中,业务往往是复杂的,可能升级过程中需要多个服务同时升级。如下图所示:
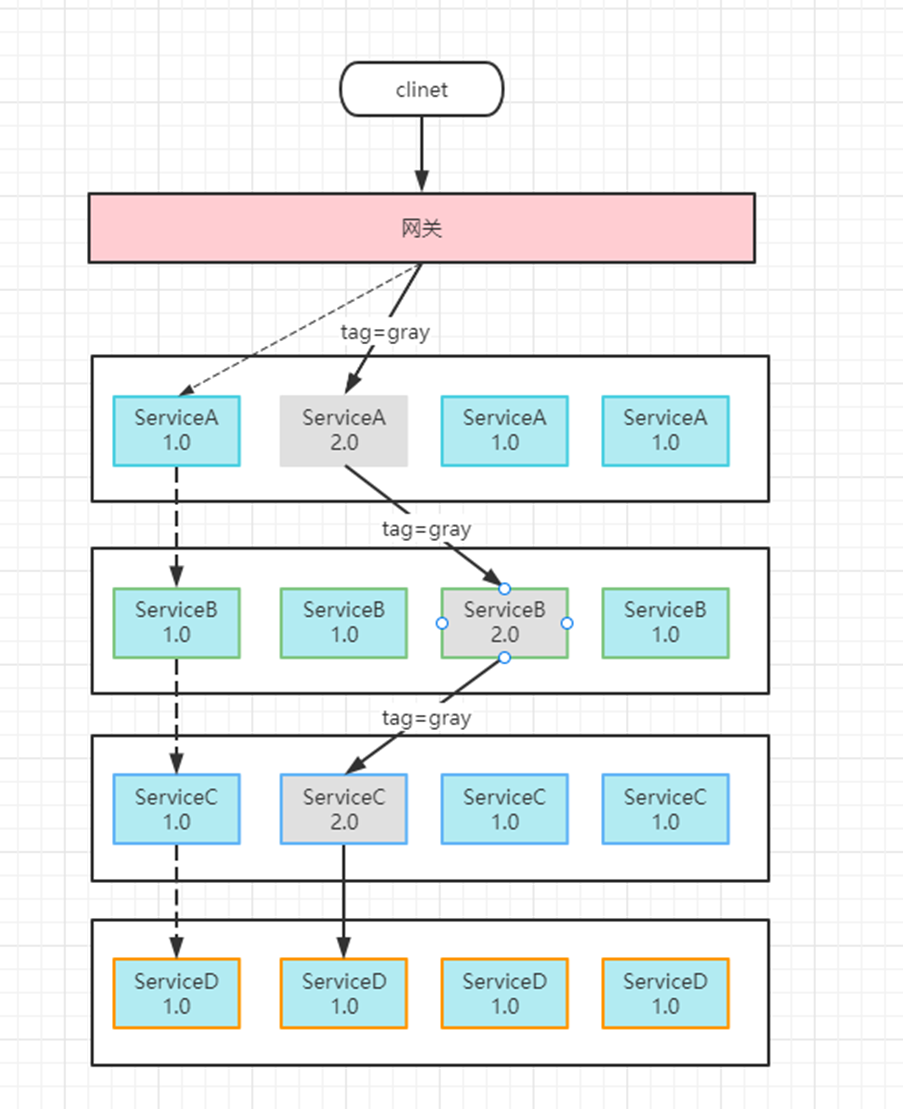
如上图所示,针对服务ServiceA调用服务ServiceB来分析,需要额外配置服务ServiceB的治理规则,确保来自灰度环境的ServiceA的流量转发至服务ServiceB的灰度版本。这样的做法看似符合正常的操作逻辑,但是在真实业务场景中,业务的微服务规模和数量远超上述的例子,其中一条请求链路可能经过数十个微服务,新功能发布时也可能涉及到多个微服务同时变更,并且业务的服务之间依赖错综复杂,频繁的服务发布、以及服务多版本并行开发导致流量治理规则日益膨胀,给整个系统的维护性和稳定性带来了不利因素。
针对以上的问题,可以采用全链路灰度来解决。
全链路灰度:在微服务体系架构中,服务之间的依赖关系错综复杂,有时某个功能发版依赖多个服务同时升级上线。我们希望可以对这些服务的新版本同时进行小流量灰度验证,这就是微服务架构中特有的全链路灰度场景,通过构建从网关到整个后端服务的环境隔离来对多个不同版本的服务进行灰度验证。
我们只需部署服务的灰度版本,流量在调用链路上流转时,由流经的网关、各个中间件以及各个微服务来识别灰度流量,并动态转发至对应服务的灰度版本。
用不同的颜色来表示不同版本的灰度流量,可以看出无论是微服务网关还是微服务本身都需要识别流量,根据治理规则做出动态决策。当服务版本发生变化时,这个调用链路的转发也会实时改变。相比于利用机器搭建的灰度环境,这种方案不仅可以节省大量的机器成本和运维人力,而且可以帮助开发者实时快速的对线上流量进行精细化的全链路控制。
蓝绿发布
定义:
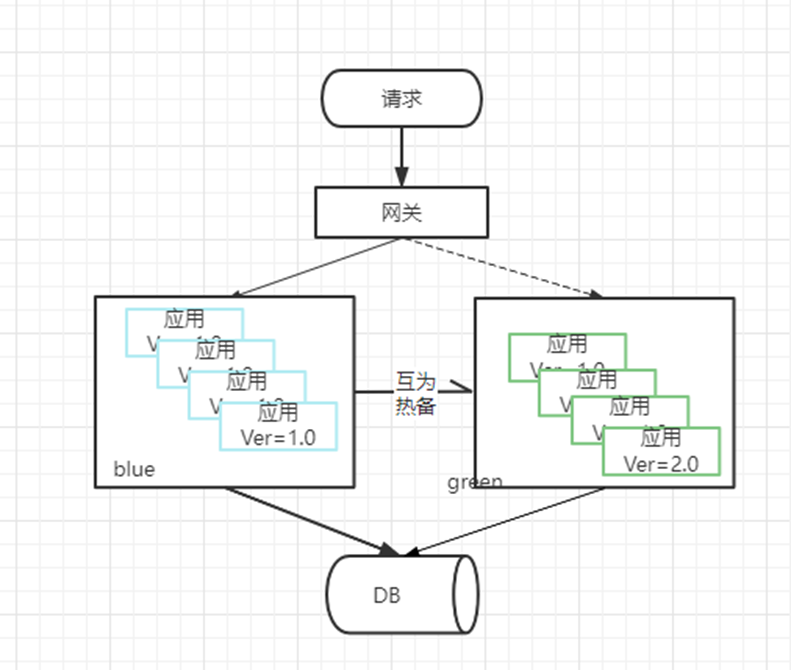
蓝绿部署,是指同时运行两个版本的应用。蓝绿部署的时候,并不停止掉老版本,而是直接部署一套新版本,等新版本运行起来后,再将流量切换到新版本上。但是蓝绿部署要求在升级过程中,同时运行两套程序,对硬件的要求就是日常所需的二倍,比如日常运行时,需要3台服务器支撑业务,那么使用蓝绿部署,你就需要购置6服务器。
滚动发布
定义:
所谓滚动升级,就是在升级过程中,并不一下子启动所有新版本,是先启动一台新版本,再停止一台老版本,然后再启动一台新版本,再停止一台老版本,直到升级完成,这样的话,如果日常需要6台服务器,那么升级过程中也就只需要6+1台就行了。但是滚动升级有一个问题,在开始滚动升级后,流量会直接流向已经启动起来的新版本,但是这个时候,新版本是不一定可用的,比如需要进一步的测试才能确认。那么在滚动升级期间,整个系统就处于非常不稳定的状态,如果发现了问题,也比较难以确定是新版本还是老版本造成的问题。为了解决这个问题,我们需要为滚动升级实现流量控制能力。