准确率、精确率、召回率、F1值
定义:
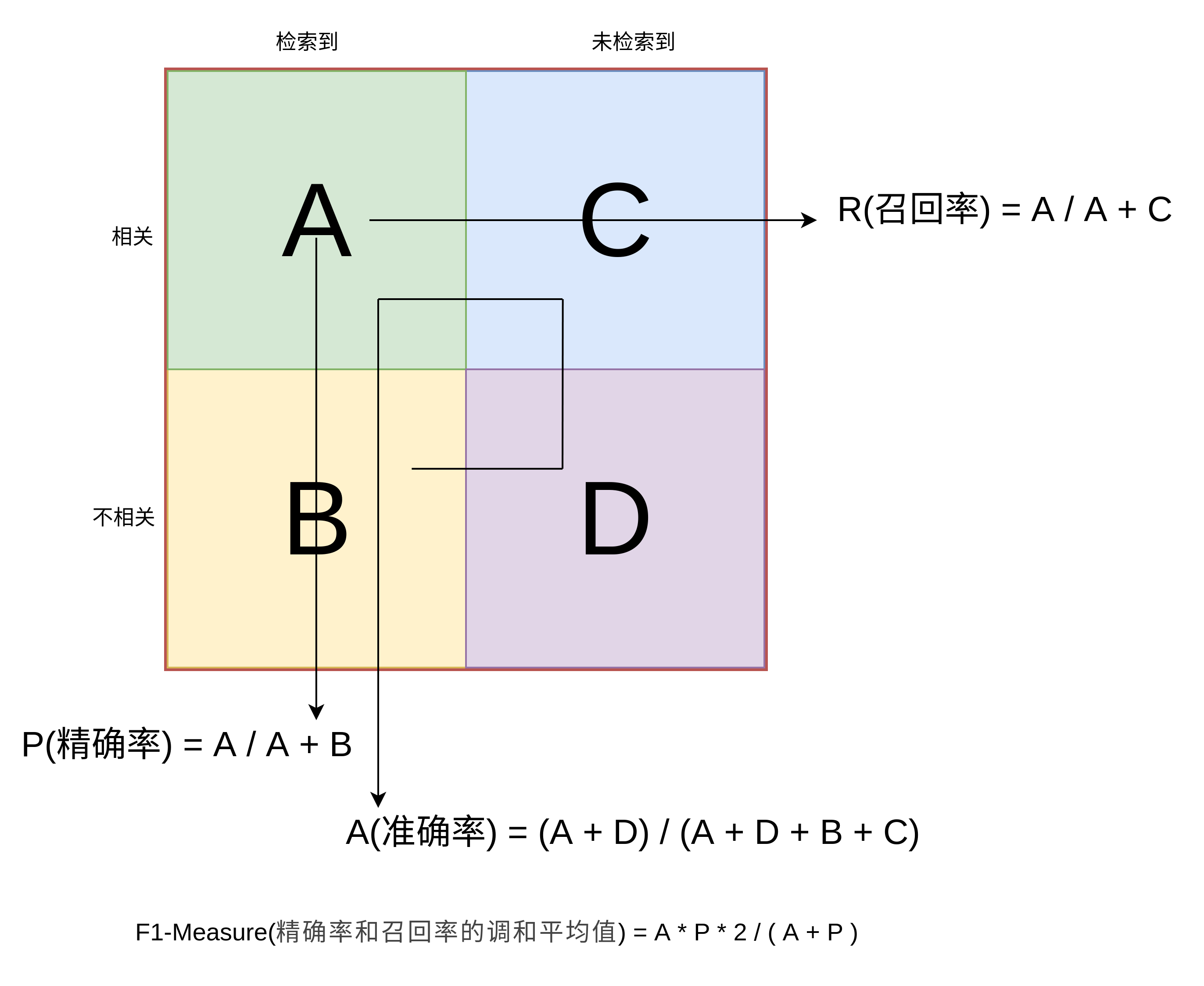
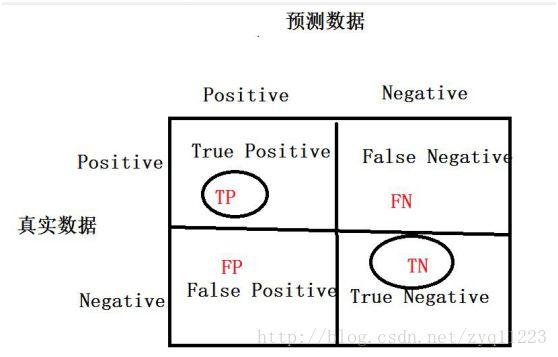
准确率(Accuracy):正确分类的样本个数占总样本个数, A = (TP + TN) / N
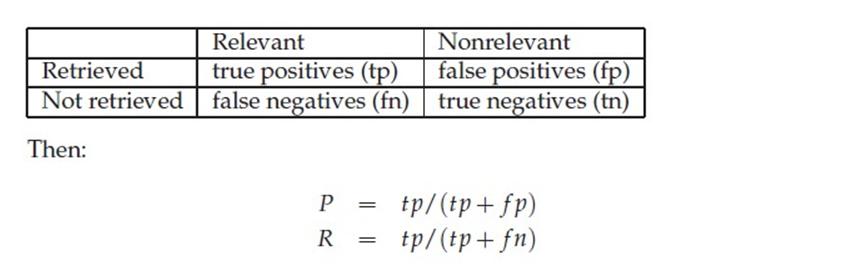
精确率(Precision)(查准率):预测正确的正例数据占预测为正例数据的比例, P = TP / (TP + FP)
召回率(Recall)(查全率):预测为正确的正例数据占实际为正例数据的比例, R = TP / (TP + FN)
F1 值(F1 score): 调和平均值, F = 2 / (1/P + 1/R) = 2 * P * R / (P + R)
作者的任务是一个典型的三分类问题, 下面通过混淆矩阵来解释一下:

横轴:实际负类、实际中性类、实际正类 (真实结果)
纵轴:预测负类、预测中性类、预测正类 (预测结果)
T00 F01 F02
F10 T11 F12
F20 F21 T22
T00: T or F 代表真假, 第一个数字代表真实结果即标签值, 第二个数字代表预测的类别即预测值
通过混淆矩阵,可以算出(总量4779):
A = (T00 + T11 + T22) / N = (1494 + 1244 + 1126) / 4779 = 0.8085
P0 = T00 / (T00 + F10 + F20) = 1494 / 1912 = 0.7813
P1 = T11 / (F01 + T11 + F21) = 1244 / 1487 = 0.8365
P2 = T22 / (F02 + F12 + T22) = 1126 / 1380 = 0.8159
P = (0.7813 + 0.8365 + 0.8159) / 3 = 0.8112
R0 = T00 / (T00 + F01 + F02) = 1494 / 1748 = 0.8546
R1 = T11 / ( F10 + T11 + F12) = 1244 / 1558 = 0.7856
R2 = T22 / (F20 + F21 + T22) = 1126 / 1473 = 0.7644
R = (0.8546 + 0.7856 + 0.7644) / 3 = 0.8015
F1 = 2 * P * R / (P + R) = 2 * 0.8112 * 0.8015 / (0.8112 + 0.8015) = 0.8063
优缺点:
准确率、精确率、召回率、F1 值主要用于分类场景。
准确率可以理解为预测正确的概率,其缺陷在于:当正负样本比例非常不均衡时,占比大的类别会影响准确率。如异常点检测时:99% 的都是非异常点,那我们把所有样本都视为非异常点准确率就会非常高了。
精确率,查准率可以理解为预测出的东西有多少是用户感兴趣的;
召回率,查全率可以理解为用户感兴趣的东西有多少被预测出来了。
一般来说精确率和召回率是一对矛盾的度量。为了更好的表征学习器在精确率和召回率的性能度量,引入 F1 值。
ROC曲线和评价指标AUC
ROC:接受者操作特性曲线(receiver operating characteristic curve,简称ROC曲线),是指在特定刺激条件下,以被试在不同判断标准下所得的虚报概率P(y/N)为横坐标,以击中概率P(y/SN)为纵坐标,画得的各点的连线。
所以需要计算两个值1、虚报概率P; 2、击中概率P
首先利用混淆矩阵计算ROC:
假阳性率(False Positive Rate, FPR)(虚报概率): 横坐标,N是真实负样本的个数,FP是N个负样本中被分类器预测为正样本的个数。 FPR=FP/(FP+TN)
真阳性率(True Positive Rate, TPR)(击中概率):纵坐标, TPR=TP / (TP+FN)
二分类就不做概述,从roc_curve的函数定义,直接作出示例:
import numpy as np
from sklearn import metricsy = np.array([1, 1, 2, 2])
scores = np.array([0.1, 0.4, 0.35, 0.8])
# 机器学习中y为y_test的label值, socres为预测概率,即clf.predict_proba(x_test)[:, 1]
fpr, tpr, thresholds = metrics.roc_curve(y, scores, pos_label=2)
# fpr array([0. , 0. , 0.5, 0.5, 1. ])
# tpr array([0. , 0.5, 0.5, 1. , 1. ])
# thresholds array([1.8 , 0.8 , 0.4 , 0.35, 0.1 ])auc=metrics.auc(fpr,tpr)
# 也可以直接进行计算
auc = metrics.roc_auc_score(y, scores)
结合三分类做具体解释:
①方法一:每种类别下,都可以得到m个测试样本为该类别的概率(矩阵P中的列)。所以,根据概率矩阵P和标签矩阵L中对应的每一列,可以计算出各个阈值下的假正例率(FPR)和真正例率(TPR),从而绘制出一条ROC曲线。这样总共可以绘制出n条ROC曲线。最后对n条ROC曲线取平均,即可得到最终的ROC曲线。
②方法二:
首先,对于一个测试样本:1)标签只由0和1组成,1的位置表明了它的类别(可对应二分类问题中的‘’正’’),0就表示其他类别(‘’负‘’);2)要是分类器对该测试样本分类正确,则该样本标签中1对应的位置在概率矩阵P中的值是大于0对应的位置的概率值的。基于这两点,将标签矩阵L和概率矩阵P分别按行展开,转置后形成两列,这就得到了一个二分类的结果。所以,此方法经过计算后可以直接得到最终的ROC曲线。
上面的两个方法得到的ROC曲线是不同的,当然曲线下的面积AUC也是不一样的。 在python中,方法1和方法2分别对应sklearn.metrics.roc_auc_score函数中参数average值为’macro’和’micro’的情况。下面参考sklearn官网提供的例子,对两种方法进行实现。

先考察一下四个特殊的点:
点(0,1),即FPR=0,TPR=1。FPR=0说明FP=0,也就是说,没有假正例。TPR=1说明,FN=0,也就是说没有假反例。这不就是最完美的情况吗?所有的预测都正确了。良性的肿瘤都预测为良性,恶性肿瘤都预测为恶性,分类百分之百正确。这也体现了FPR 与TPR的意义。就像前面说的我们本来就希望FPR越小越好,TPR越大越好。
点(1,0),即FPR=1,TPR=0。这个点与上面那个点形成对比,刚好相反。所以这是最糟糕的情况。所有的预测都预测错了。
点(0,0),即FPR=0,TPR=0。也就是FP=0,TP=0。所以这个点的意义是所有的样本都预测为恶性肿瘤。也就是说,无论给什么样本给我,我都无脑预测成恶性肿瘤就是了。
点(1,1),即FPR=1,TPR=1。显然,这个点跟点(0,0)是相反的,这个点的意义是将所有的样本都预测为良性肿瘤。
考察完这四个点,我们可以知道,如果一个点越接近左上角,那么说明模型的预测效果越好。如果能达到左上角(点(0,1)),那就是最完美的结果了。
ROC曲线特性:当测试集中的正负样本分布发生变化了,ROC曲线可以保持不变。在实际的数据集中经常会出现类不平衡(class imbalance)现象,即负样本比正样本多很多(或者相反),而且测试数据中的正负样本的分布也可能随着时间变化。
为什么ROC不受样本不平衡的影响呢?
TPR考虑的都是正例,既分母TP+FN是真实正例的数目;FPR考虑的都是负例,分母FP+TN是真实负例的数目。
想一下ROC曲线绘画过程,可以看成以预测为正例的概率进行排序,然后概率由大到小依次把样本预测为正例,每次把一个样本当成正例ROC曲线上就多了一个点(TPR,FPR)。这个过程也可以看成一个由大到小的阈值去筛选概率高的样本作为正例(预测值)。
如果负例增加到10倍,可以假设增加的负样本与原有的负样本保持独立同分布。
TPR:在学习器和上述阈值不变的情况下,我们看一下负例增加前后TPR会不会变化。首先分母不会变。再考虑分子,因为阈值和学习器也不变,那么对于真实的正例来说,预测结果不变,则TPR不变。
FPR:对于FPR来说,分母变为10*(FP+TN),给定学习器和阈值,因为假设增加的数据与原数据独立同分布,那么大于这个阈值的负样本(label为负)也会变为原来的10倍,即10*FP。所以FPR也不变。
上述的讨论是对于ROC中的一个点讨论的,再让阈值动起来的话,那么可以得到ROC上每个点都不变。当然这是理想情况,实际上由于数据噪声等影响,曲线肯定会有轻微扰动,但整体不会有较大的变化。
二分类参考:https://blog.csdn.net/liweibin1994/article/details/79462554
多分类参考:https://blog.csdn.net/xyz1584172808/article/details/81839230