目录
一、缺失数据定义
二、缺失数据原因
三、缺失数据处理步骤
四、数据缺失机制
1.完全随机缺失(MCAR)
2.随机缺失(MAR)
3.非随机、不可忽略缺失(NMAR)
五、缺失数据处理方法
1.直接删除
2.缺失值插补
3.单一插补
(1)介绍
(2)均值插补
(3)随机插补法
(4)回归插补法
(5)随机回归插补
4.多重插补方法(R语言mice包可做)
(1)介绍
(2)优点
六、缺失数据处理实例——R语言VIM包中的sleep数据集
一、缺失数据定义
在实际工作中,常会因为某些原因导致数据缺失,只能观测到一部分数据,统计学中一般称为缺失数据。
二、缺失数据原因
- 调查对象忘记回答问题
- 调查对象拒绝回答敏感问题
- 调查对象错过约定时间或过早退出调查
- 获取这些信息的代价太大
- 记录设备出现问题或数据误记
三、缺失数据处理步骤
- 识别缺失数据
- 检查导致数据缺失的原因
- 删除包含缺失值的案例或用合理的数值插补缺失值
四、数据缺失机制
1.完全随机缺失(MCAR)
数据的缺失完全是随机的,数据缺失与否与其它任何完全观测或含缺失数据变量都无关,此时可以将数据完整的样本看作是所有数据集的一个简单随机样本。
2.随机缺失(MAR)
数据的缺失不是完全随机的,某变量数据缺失与否与其他完全观测变量相关,但与它自己的未观测值无关。
3.非随机、不可忽略缺失(NMAR)
数据不完全变量中数据缺失的概率依赖于数据不全变量的数值本身,这种缺失机制是不可忽略缺失。
【注】第三种缺失机制不易处理和建模,因而通常假设缺失数据前两种缺失机制。
五、缺失数据处理方法
1.直接删除
也就是将存在缺失数据的对象(元组、记录)删除,从而得到一个完整的数据信息表。
数据缺失机制为完全随机缺失时可用此方法。
2.缺失值插补
将缺失值作为一种特殊的属性值来处理,利用已有的数据对缺失值进行插补,以得到完整数据集加以分析。
数据缺失机制为完全随机缺失或随机缺失时可用此方法。
缺失值插补方法:可以用回归插补、均值插补、多重插补等方法得到缺失值的预测值,本质上是用现有数据的信息来推测缺失值。
3.单一插补
(1)介绍
单一插补是以估算为基础的方法,利用已有数据对缺失数据进行推算,在缺失数据被替代后,对新生成的数据集进行相应的统计分析。
- 优点:单一插补法改变了传统方法将缺失值忽略不考虑的习惯,使得各种统计分析均可以在插补后的完整数据集上展开
- 缺点:无论采用何种方法,都存在没有考虑缺失数据的不确定性,从而导致参数估计量方差被低估的问题。尽管由于随机回归插补引入了随机误差项,能够缓解这一问题,但是随机误差项分布的确定是比较困难的
(2)均值插补
将数据表中的变量分为连续型和非连续型来分别进行处理。
- 连续型:根据该变量在其他所有对象取值的平均值来插补该缺失的变量值
- 非连续型:根据统计学中的众数原理,用该变量在其他所有对象的取值次数最多的值(即出现频率最高的值)来插补该缺失的变量值
(3)随机插补法
从有回答单位中随机抽取插补值,对缺失数据进行插补的方法。
(4)回归插补法
该方法主要是通过建立含缺失值目标变量与数据完全的辅助变量之间的回归模型来实现缺失数据的插补。
(5)随机回归插补
该方法就是在回归插补值的基础上再加上残差项,以反映缺失数据的不确定性。
残差项的分布可以包括正态分布,也可以是其它的非正态分布。
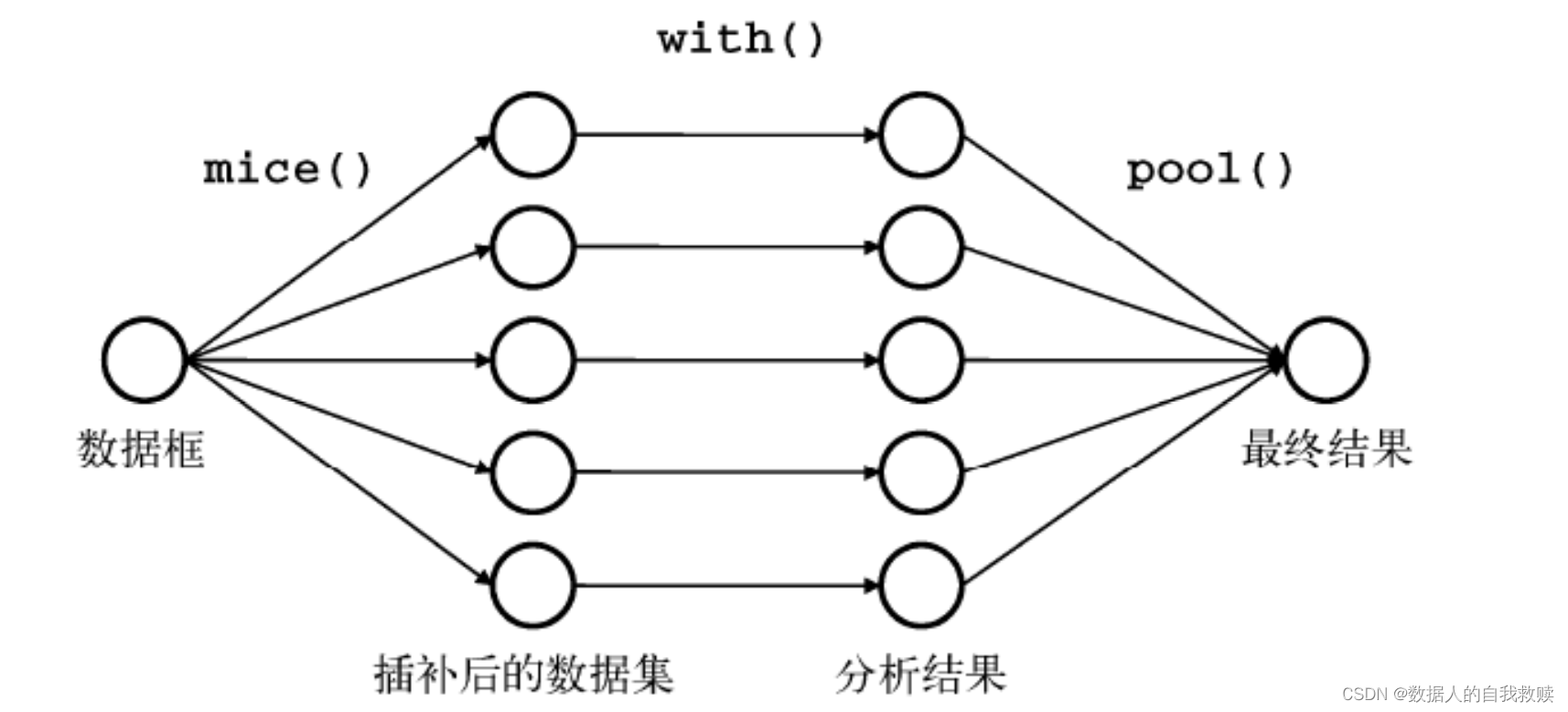
4.多重插补方法(R语言mice包可做)
(1)介绍
多重插补建立在贝叶斯理论基础之上,基于Gibbs算法来实现对缺失数据的处理。
多重插补法分为三个步骤:
- 插补步:基于已有数据,为含缺失数据变量建立插补模型,为每个缺失值产生多组插补值,得到多组完整数据集
- 分析步:基于各组完整数据集进行参数估计
- 合并步:将多组参数估计结果加以汇总
 (2)优点
(2)优点
多重插补的出现,弥补了单一插补法的缺陷。
- 第一,多重插补过程产生多个中间插补值,可以利用插补值之间的变异反应无回答的不确定性,包括无回答原因已知情况下抽样的变异性和无回答原因的不确定造成的变异性
- 第二,多重插补通过模拟缺失数据的分布,较好地保持变量之间地关系
- 第三,多重插补能给出衡量估计结果不确定性地大量信息,单一插补给出的估计结果则较为简单
六、缺失数据处理实例——R语言VIM包中的sleep数据集
#install.packages("VIM")
#install.packages("mice")
library(VIM)
library(mice)
View(sleep)
sleep[complete.cases(sleep),]#得到无缺失值样本
sum(is.na(sleep$Dream))#Dream变量缺失样本个数
mean(is.na(sleep$Dream))#Dream变量缺失样本概率
fit=lm(Dream~Span+Gest,data=na.omit(sleep))#采用完整样本建立Dream和其他变量的回归模型
summary(fit)#查看缺失模式,有2^10种可能
md.pattern(sleep)#多重插补
imp=mice(sleep)#默认生成五组数据集,可以主动调整
fit=with(imp,lm(Dream~Span+Gest))
pooled=pool(fit)#合并数据结果
summary(pooled)#观看最终分析结果
imp
imp$imp$Dream#查看Dream的五次插补结果
dataset2=complete(imp,action=2)#观看第二组得到的完整数据集
dataset2#模拟,比较多重插补和直接删除的优劣
#人为生成一个完整数据集,得到数据估计结果(真实的),随机生成一些缺失值
#然后用缺失值缺失方法处理,进行估计,和真实值进行比较,得到优劣个人见解,该请各位读者批评指正!