写在前文:撰写本文仅用于学习交流,不承担因此带来任何的潜在风险和责任
文章目录
- 0 目的明确,限制和思考
- 1 前置模块准备
- 1.1 selenium安装及简单操作
- 1.2 python lxml模块安装
- 2 代码撰写
- 2.1 selenium操作网页
- 2.1.1 元素定位
- 2.1.2 验证码图片保存到本地
- 2.1.3 验证码识别
- 2.1.4 登录按钮点击
- 2.2 课程网站登录后的操作
- 2.2.1 课程作业模块定位
- 2.2.2 作业爬取思路
- 2.2.3 作业爬取补充说明
- 3 后续进一步处理
- 3.1 邮箱发送清单
- 3.2 云服务器定时
- 4 结语
0 目的明确,限制和思考
目的及需求:博主老师把作业都布置在一个网站的作业模块上,但是有时候可能忘记告知学生。如果一门课这样,那也不值得撰写该程序。但是博主有十多门课,课程一多,有时候确实会忘记个别课的作业的截止时间,然后没有提交作业。
本文限制:1.本文所述的全部内容均基于网页操作,如果是想爬取app或者其他平台的小伙伴可以退出去啦~ 2. 另外,本文自动化操作的网页的前提是网页代码规范(解释:两个课程的作业模块的html代码的关键属性需要一致,如果实在不一致,需要根据具体内容再写其他代码) 3. 本文涉及的验证码识别是图片验证码(不是滑动模块,也不是交换顺序,也不是按顺序识字等)
思考:所以!为啥老师只布置作业,而不提醒学生作业截止时间呢?(狗头保命)另外,本文设计的技术不止可以爬取课程网站作业,其他用途可以自行思考~
1 前置模块准备
1.1 selenium安装及简单操作
selenium是什么?:selenium是web自动化测试工具,通俗来说,就是可以通过selenium代码调用浏览器驱动,来驱使浏览器的工具(个人见解)。可能有小伙伴会问:我用鼠标直接操作网站不香嘛?为啥还要死气八咧写个程序?这么来说:“你有没有重复的一些需求?比如把一些数据重复的输入到某网站的部分模块以达到一个测试的目的” 那这个时候,如果有一个程序可以帮助你自动化输入数据,是不是很爽呢?
python环境:python3.9
selenium安装:cmd输入pip install selenium 安装完成后,可以继续输入pip list看一下有没有安装成功(博主的selenium是4.4.3)
浏览器驱动下载及安装:前文提到selenium是调用浏览器驱动来执行后续操作,所以需要下载一个浏览器驱动。不同的浏览器有不同的驱动,这里要注意的是一定要下载和浏览器版本对应的驱动
博主下载的是edge浏览器驱动,以edge浏览器驱动下载为例:
- 首先,查看自己edge浏览器的版本

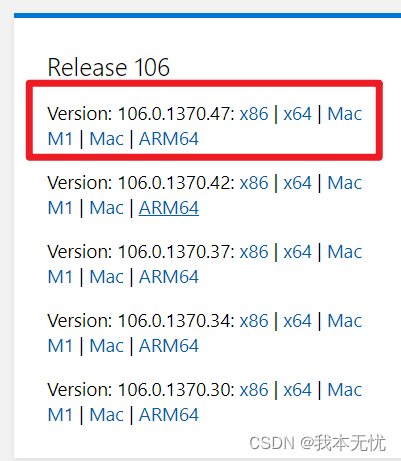
- 其次,去官网(https://developer.microsoft.com/en-us/microsoft-edge/tools/webdriver/)下载对应的浏览器驱动
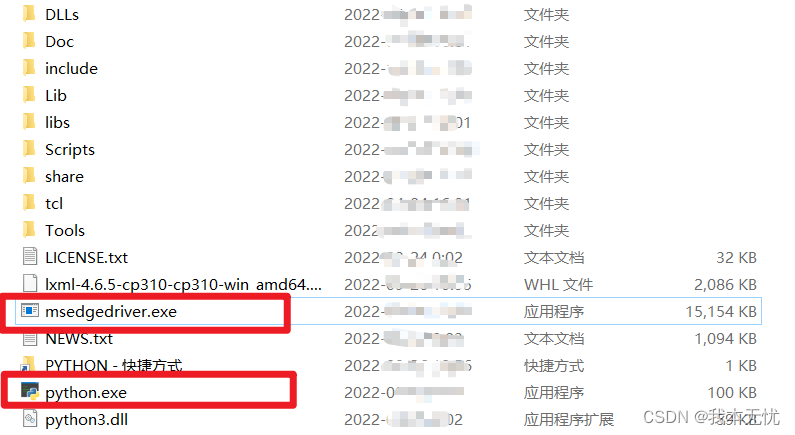
- 最后,将下载完成的
msedgedriver.exe放入python的安装目录下(和python.exe在同一个目录即可)be like:
- 上述步骤完成后,可以打开pycharm等python编辑器测试下,测试样例网上很多,这里就不赘述了。另外,如果不是edge浏览器,是谷歌或者火狐等等,也可以下载对应的浏览器驱动,测试代码可能会存在不同,这点要注意。
1.2 python lxml模块安装
模块说明:xpath语法依托于lxml模块,故在cmd输入pip install lxml下载即可
模块使用:在pycharm中输入 from lxml import etree使用爬虫常用代码测试即可
2 代码撰写
2.1 selenium操作网页
# edge浏览器selenium引入
from selenium import webdriver
from selenium.webdriver.common.by import By # 这句话是用来后续元素定位的
driver = webdriver.Edge() # 不同浏览器这句不一样,要注意
driver.get("课程网站网址")# 这里要修改,这句代码是用edge浏览器打开网址为:“课程网站网址”的网站
如果是其他浏览器,请百度搜索:XX浏览器selenium测试代码,把定义driver的相关代码复制过来,这样它才可以操作
2.1.1 元素定位
定义:元素定位的意思就是,我们要告诉selenium登录框、密码框在哪,登录按钮等在哪里
老版本的定位方法是:driver.find_element_by_name等方法,但是selenium新版本变成了:
先引入:from selenium.webdriver.common.by import By
再使用:driver.find_element(By.NAME, 'xxx')
对于特定的课程网站元素定位,这里列举几个例子:
- 要寻找用户名输入框
在课程网站网页点击F12,调出下述图
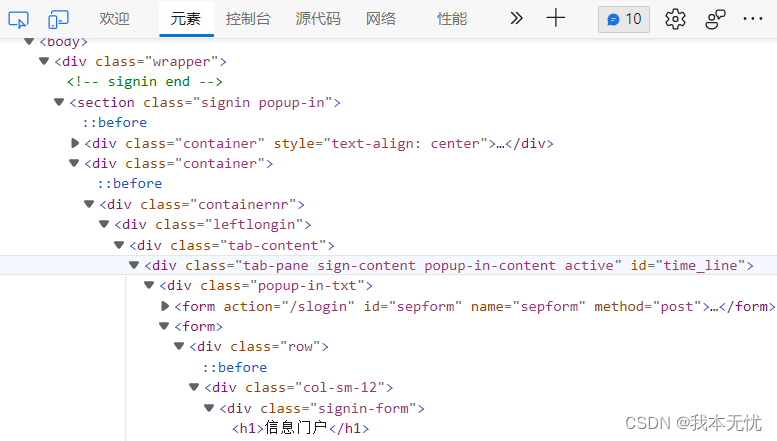
点击左上角的这个按钮

再点击用户名输入框

即可定位到用户输入框的源代码

我们可以看到:用户名输入框的{name}属性是userName1
所以,我们在pycharm代码中可以写:
elem = driver.find_element(By.NAME, "userName1") #寻找账号输入框,elem类似于变量名,可以根据变量命名规范命名
elem.clear()# 清空输入框原本的内容
elem.send_keys(username) #输入账号,需要提前将账号赋给username
- 寻找密码输入框
寻找密码输入框和寻找用户名输入框的类似

所以,我们在pycharm代码中可以写:
password = driver.find_element(By.NAME, 'pwd1') #寻找密码输入框
password.clear()
password.send_keys(pwd) #输入密码
- 寻找验证码输入框

code_login = driver.find_element(By.ID, 'certCode1') #寻找验证码输入框
- 定位验证码图片

imgelement = driver.find_element(By.XPATH,'//*[@id="code"]') # 寻找验证码输入框
code_login.send_keys(code_text) #输入验证码
这里要注意,只是定位到验证码输入框啦,但是具体输入验证码的内容还没实现,所以代码块中的code_login还没输入数据,请看后文2.1.2
2.1.2 验证码图片保存到本地
要爬取课程网站里的作业,一般要先登录课程网站(当然不用登录另说)。登录网站一般有好几种方法,比如post一个data到网站服务器(但是课程网站一般会使用加密技术把密码加密)博主觉得麻烦(其实是测试了几次不成功 ),亦或者使用cooike(只不过cooike一段时间会失效)
博主这里使用的是selenium自动化登录,要使用selenium,就需要处理验证码。网上看了下,大部分资料集中于对登录页面截图,然后通过图像坐标定位验证码图片,然后保存到本地。这种方法是可以的,但是存在以下限制:
- 自动坐标定位有时候定位不准,手动坐标定位如果换个分辨率的屏幕,也会定位不准
- 如果将程序放到云服务器上,云服务器的浏览器是没界面的,实现不了截图,坐标定位的功能
所以,考虑再三(搜索再三 )博主从网上某位博主那里借鉴了一个思路(具体是哪位博主实在是找不到网址了)
使用selenium的
screenshot功能,即可绕过图片坐标定位,直接将验证码图片保存到本地
完整的代码如下:
imgelement = driver.find_element(By.XPATH,'//*[@id="code"]') #验证码图片定位
imgelement.screenshot('./codedd.png') #保存验证码截图
code_text = tranformImgCode('./codedd.png',xxxx) #超鹰api调用
这里就是说将图片验证码保存到本地,然后使用超鹰api调用并识别
2.1.3 验证码识别
验证码的样子类似于这样:

识别验证码的方式其实也有很多种(不懂的小伙伴可以百度下)本文使用的是超鹰第三方打码平台,只需要将超鹰的api文件(需要在api文件chaoying.py中,修改自己的用户名、密码等参数)放入程序同级目录之下即可,然后调用下述代码
# 验证码软件识别API
def tranformImgCode(imgPath,imgType):chaojiying = Chaojiying_Client('超鹰用户名', '超鹰密码', '超鹰软件ID')# 用户中心>>软件ID 生成一个替换 软件IDim = open(imgPath, 'rb').read()return(chaojiying.PostPic(im, imgType))['pic_str']
code_text = tranformImgCode('./codedd.png',xxxx) # tranformImgCode是超鹰提供的函数,第一个参数是验证码图片,第二个是超鹰规定的参数(四位数字)
小伙伴们可以参考其他博主的超鹰平台使用文章,百度有很多
其他验证码识别方式也可以,比如手动输入验证码,具体思路就是用户手动在网页输入验证码即可
但是这样就不能放到云服务器让程序自动运行啦
2.1.4 登录按钮点击
和前面定位输入框、密码框一样,登录按钮也需要去定位

pycharm代码如下:
driver.find_element(By.ID, "sb1").click()
2.2 课程网站登录后的操作
2.2.1 课程作业模块定位
一般我们登陆教务系统后,它不会直接跳转到课程作业模块,我们要用selenium使网页跳转到作业模块,具体编程的方法和前述登陆按钮定位然后点击是一致的,可以百度selenium控制网页的具体操作多学习学习,比如登陆后,我想跳转到课程模块,需要通过以下代码(这里是通过XPATH元素定位的方法):
driver.find_element(By.XPATH,'//a[@title="作业"]').click()
time.sleep(2) # 跳转后停留一些时间
2.2.2 作业爬取思路
大学的课程不止一门,例如我可能有{《高等数学》、《线性代数》、《概率论》}三门课程,我需要先跳转到《高等数学》作业页面,然后爬取《高等数学》的n个作业的开始时间、截止时间等信息放到python的一个list中,然后操作selenium后退到主页面,再次跳转到《线性代数》页面进行爬取n个作业的开始时间、截止时间等信息添加到list中,以此类推。如果这三门课程网站的属性元素是相同的(考验网站开发程序员的代码规范能力),完全可以写一个for循环,总结爬取思路如下:
- 爬取所有的课程名字,放到 Course_Name 列表中
- 写for循环遍历Course_Name 列表
- 在for循环内部
先跳转到《高等数学》,返回《高等数学》页面的源代码,从源代码中获取《高等数学》作业信息- …
2.2.3 作业爬取补充说明
selenium返回对应页面源代码:
page_text_branch = driver.page_source # 返回当前页面的源代码
tree_branch = etree.HTML(page_text_branch) # 对源代码进行html解析
返回《高等数学》页面的作业开始时间等信息:
opendata = tree_branch.xpath('//td[@headers="openDate"]/text()') # 返回作业开始时间
status = tree_branch.xpath('//td[@headers="status"]/text()') # 返回作业标题
对返回的数据进行\n和\t的处理:
def clear(list_):for i in range(0, len(list_)):list_[i] = list_[i].replace('\n','').replace('\t','')return list_
selenium操作浏览器后退:
driver.back() # 浏览器后退
数据列表后续操作:
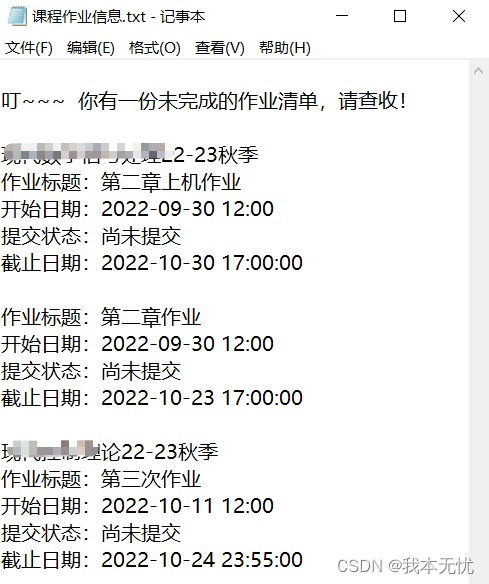
拿到课程作业信息的list后,可以对作业截止时间和当前时间做比较,如果截止时间在当前时间之前,就可以考虑不返回;同样也可以考虑把你想输出的列表放到一个txt文件夹中,类似于这样:
3 后续进一步处理
3.1 邮箱发送清单
当我们通过程序爬取到未完成作业的清单后,最基本的思路是把课程作业信息.txt文件放到程序同级目录下,博主就想能不能让它自己发送给我呢,毕竟每次想用,都要去电脑文件夹寻找,好像有点枯燥(鸡肋 )
于是乎,博主就通过一个程序将课程作业信息.txt发送到博主自己的qq邮箱
小伙伴们可以百度搜索:python发送邮件(思路是:用你自己的一个邮箱发送到另外一个邮箱)
博主在进行实验的时候,遇到了或多或少的问题,贴个代码(以发送邮箱为163邮箱为例,qq邮箱要修改):
def mail_post():mail = MIMEMultipart()mail['To'] = email.utils.formataddr(('Henry', '接受的邮箱'))mail['From'] = email.utils.formataddr(('Henry', '发送的邮箱'))mail['Subject'] = '你的未完成的作业清单~'# 需要发送的附件txtAnnex = MIMEBase("application", "octet-stream")txtAnnex = MIMEText(open('课程作业信息.txt', "rb").read(), "base64", "gb2312")txtAnnex['Content-Type'] = 'application/octet-stream'txtAnnex.add_header("Content-Disposition", "attachment", filename=("gb2312", "", "课程作业信息.txt"))mail.attach(txtAnnex)server = smtplib.SMTP_SSL('smtp.163.com', 465)server.login('发送的邮箱', '163邮箱生成的授权码')server.set_debuglevel(True)try:server.sendmail('发送的邮箱', ['接收的邮箱'], msg=mail.as_string())print('邮件已发送成功,请查收!')finally:server.quit()
163邮箱POP3/STMP设置链接(引用其他博主的链接):
https://blog.csdn.net/liuyuinsdu/article/details/113878840
其他的python发送邮件的教程(引用其他博主的链接):
https://blog.csdn.net/qq_20417499/article/details/80566265
3.2 云服务器定时
每次运行我们的.py程序后,python会自动发送课程作业信息.txt到我们自己的邮箱,但是还有一个问题是:我们需要自己打开PC电脑去运行程序,才能得到这个清单,这就又有点枯燥(鸡肋 )。So,博主的解决办法是把自己写的程序丢到云服务器上,然后给它安排一个定时,这样就可以每周固定时间收到一个课程作业信息.txt。这里需要注意两个问题:
- 云服务器上用edge驱动比较麻烦,所以博主首先在服务器上安装了火狐浏览器(没页面的那种),进而安装火狐浏览器驱动,放到云服务器/usr/bin下,驱动火狐浏览器的代码和前述edge的有所不同,贴在这里啦~
from selenium import webdriverfrom selenium.webdriver import Firefoxfrom selenium.webdriver.common.by import Byoptions = webdriver.FirefoxOptions()options.add_argument('--headless')options.add_argument('--no-sandbox')options.add_argument('--disable-dev-shm-usage')driver = webdriver.Firefox(options=options,executable_path='/usr/bin/geckodriver')
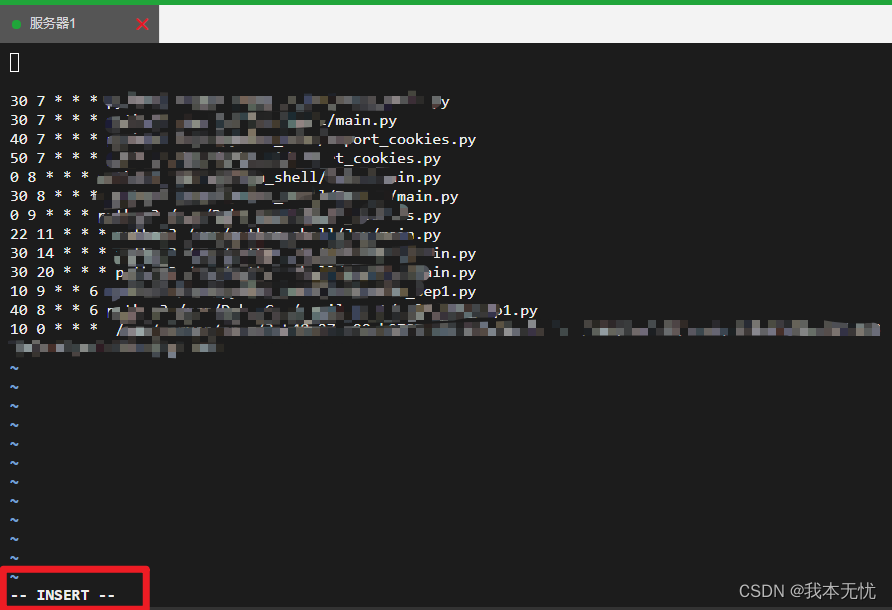
- 定时任务使用crontab即可,即在云服务器上安装crontab,
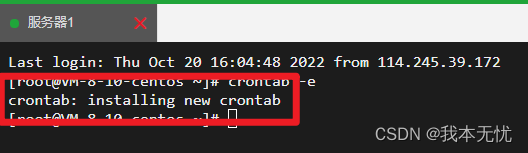
pip install crontab,然后在命令行输入crontab -e,进入vim编辑页面,首先键入i,进入INSERT模式,类似于这样:
然后键入10 9 * * 6 python3 /usr/python_shell/selenium_sep1.py,其中10 9 * * 6代表每周六的早上9:10分运行后面的指令,指令是python3 /usr/selenium_1.py,这个含义是运行在usr文件夹下的selenium_1.py,当然一些外部依赖文件(比如chaoying.py)也要放到/usr目录下
键入完成后,键入Esc,然后输入:wq即可退出vim模式,看到installing new crontab代表定时任务设置成功。
要是有小伙伴仍然不懂crontab的相关内容,可以评论区见或者百度即可(教程很多)。
4 结语
至此,《使用selenium + 简易爬虫 爬取课程网站未完成作业的清单》的相关思路教程就撰写完毕了。可能会有小伙伴找我要源码,但是博主想说的是,关键的思路节点都已经写在上文,爬取的教务系统网址和html网页等都不一样,给源码的参考意义不大,So,有有学习交流的请私信或者评论区噢~
创作不易,如果对你们有帮助,请不要吝啬一键三连噢!
最后,在文中参考了不少博主的解决办法,如果有侵权内容,请联系我删除。