摘要
1.问题背景:传统的深度CNN在图像超分辨率任务中取得了显著的成功,但是大部分基于深度CNN的SR模型没有充分利用来自原始低分辨率(LR)图像的层次特征,导致相对较低的性能。
2.创新点:为了解决这个问题,论文提出了一种名为Residual Dense Network(RDN)的新型网络结构,并对层次特征进行了充分利用。主要创新点包括:
使用Residual Dense Block(RDB)来提取丰富的局部特征,通过密集连接的卷积层实现局部特征的提取。
RDB允许从前一个RDB的状态直接连接到当前RDB的所有层,从而形成了连续内存(CM)机制,增 强了局部 特征之间的信息流动。
使用局部特征融合来自适应地学习前面和当前局部特征之间的有效信息,稳定更宽网络的训练过程。
在充分提取局部特征之后,使用全局特征融合机制以整体的方式联合自适应地学习全局层次特征。
3.方法优势:通过以上创新点,论文的RDN在图像超分辨率任务中表现出色,与当前最先进的方法相比具有显著优势。
总体而言,摘要内容介绍了论文提出的RDN网络结构及其特点,突出了其在图像超分辨率任务中的优越性能。
1. Introduction
这部分介绍了单图超分辨率(Single Image Super-Resolution,SISR)的研究背景以及目前已有的方法的局限性。主要内容包括:
SISR问题的背景:SISR旨在从低分辨率(LR)图像生成具有高分辨率(HR)的视觉效果良好的图像。SISR在计算机视觉任务中被广泛应用,如安全和监控成像、医学成像和图像生成等。然而,由于SISR是一个不逆问题,对于任何LR输入都存在多种解决方案。为了解决这个问题,已经提出了许多图像SR算法,包括插值法、重建法和基于学习的方法。
已有方法的局限性:目前的深度学习(DL)方法在SISR任务中取得了显著进展,但大多数方法未充分利用每个卷积层的信息。虽然已经有一些方法使用了记忆块或密集块等模块,但它们仍然未能充分利用来自所有卷积层的信息,并且忽略了图像中不同尺度、角度和长宽比的物体。此外,一些方法需要对原始LR图像进行插值预处理,增加了计算复杂性并丢失了一些细节信息。
论文的创新:为了解决以上问题,论文提出了一种名为Residual Dense Network(RDN)的统一框架。
主要创新包括:
使用Residual Dense Block(RDB)作为RDN的构建模块,充分利用原始LR图像中的所有层次特征。
RDB支持连续内存机制,使得当前RDB的输出可以直接连接到下一个RDB的所有层次,从而实现信息的连续传递。
通过局部特征融合(LFF),RDB可以自适应地提取局部稠密特征,并支持更高的增长率,稳定了更宽的网络训练。
使用全局特征融合(GFF)在全局范围内自适应地保留层次特征。
论文的贡献:
提出了RDN框架,可以适用于不同的降质模型,充分利用原始LR图像的所有层次特征。
提出了RDB作为构建模块,通过连续内存机制和局部特征融合充分利用了所有层次的信息。
引入了全局特征融合,以自适应地融合来自所有RDB的层次特征。
综上所述,论文的创新点在于提出了RDN网络结构,充分利用了图像中所有层次的信息,并通过局部和全局特征融合来实现更高质量的图像超分辨率重建。
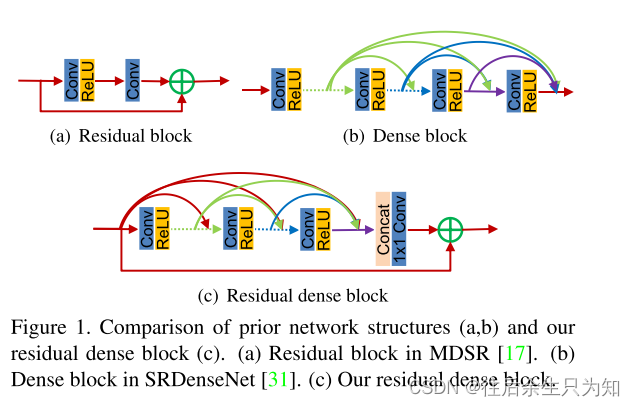
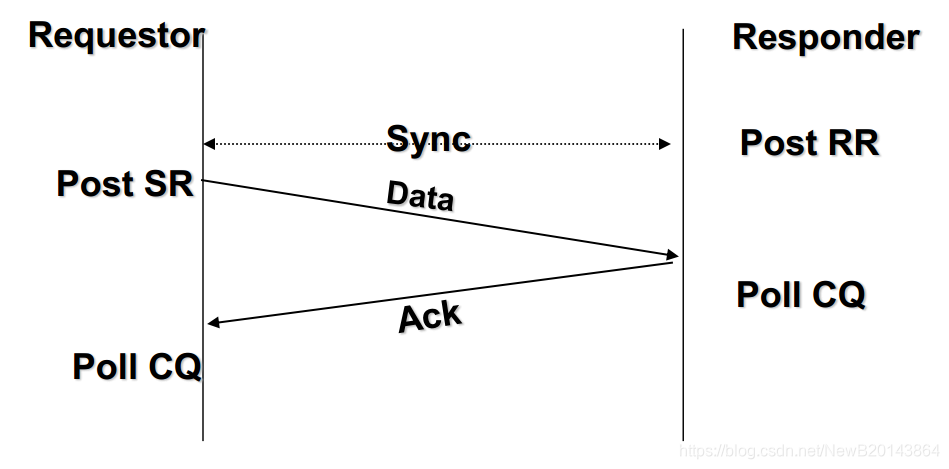
- MDSR中的残差块(Residual block):这是一个简单的残差块结构,用于构建MDSR网络。
- (b) SRDenseNet中的稠密块(Dense block):这是一个密集连接的块结构,用于构建SRDenseNet网络。
- (c) 论文提出的Residual Dense Block(RDB):这是论文中提出的创新块结构,用于构建RDN网络。
图中显示RDB结合了残差连接和密集连接的特点,具有连续内存机制和局部特征融合功能。这种结构的引入使得RDN能够充分利用所有层次的特征信息,进而提升图像超分辨率的性能。
2.Related Work
在这一部分中,论文首先回顾了图像超分辨率(Image Super-Resolution,SISR)领域的相关工作,特别是深度学习(Deep Learning,DL)方法在图像SR上取得的显著进展。他们介绍了一些早期的基于DL的SISR方法,如SRCNN、VDSR、IRCNN和DRCN等,这些方法通过增加网络深度或共享网络权重来提高性能。然后,他们指出这些方法中的一些缺点,即需要对原始LR图像进行插值处理,导致了计算复杂度增加和图像细节丢失的问题。
接着,论文提到了一些解决插值处理问题的方法,如SRResNet和EDSR,它们直接将原始LR图像作为输入,并通过转置卷积或子像素卷积层进行上采样。然而,这些方法仍然只使用最后一层卷积层的特征来进行上采样,没有充分利用每一层的信息。
随后,论文介绍了DenseNet的概念,它引入了密集连接结构,允许任意两个层之间的直接连接。密集连接使得每一层都能读取同一密集块内所有前面层的信息。然而,DenseNet/SRDenseNet/MemNet等方法仍然没有充分利用来自原始LR图像的所有层次特征。
鉴于以上问题,论文提出了一种新的网络结构,即Residual Dense Network(RDN),旨在高效地提取和融合来自LR图像的所有层次特征。RDN采用Residual Dense Block(RDB)作为基本模块,并引入局部特征融合和全局特征融合机制,以充分利用所有层次的特征信息。这使得RDN能够在图像超分辨率任务中取得更好的性能。
3.Residual Dense Network
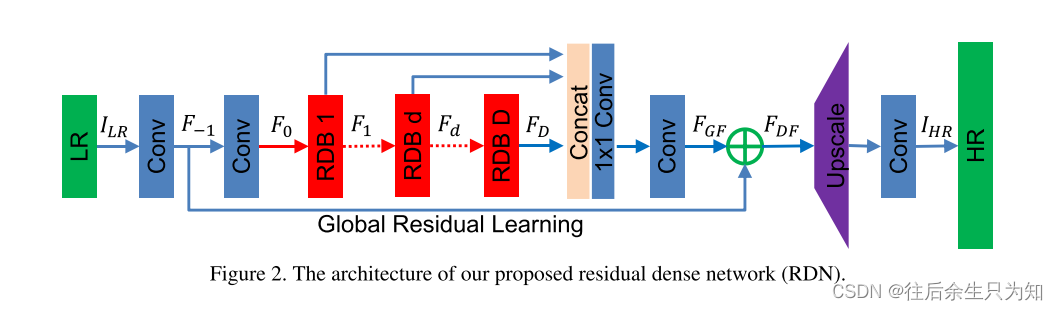
3.1SFENet:浅层特征提取,就是两个卷积操作。
3.2残差密集快(RDBs)
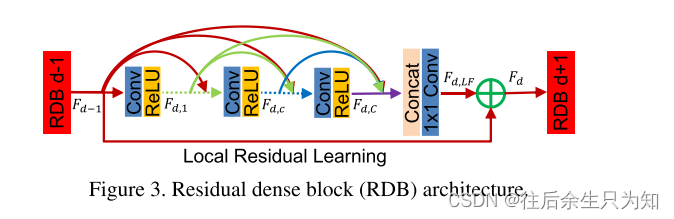
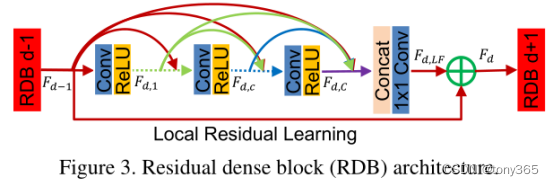
RDB包含了密集连接的层,局部特征融合(LFF)以及局部残差学习,从而实现了连续内存(CM)机制。【残差密集块RDB = 密集连接层 + 局部特征融合(LFF)+ 局部残差】
连续内存机制:在RDB中,前一个RDB的状态被传递给当前RDB的每一层。第d个RDB中第c个卷积层的输出,记为Fd,c,通过将(d-1)个RDB和当前RDB中第1到第(c-1)个卷积层的特征图进行加权求和,并应用ReLU激活函数得到。该机制建立了从前一个RDB和每一层到所有后续层的直接连接,保持了前馈的性质,同时提取了局部密集特征。
局部特征融合(LFF):为了自适应地融合前一个RDB和当前RDB中的所有卷积层的状态,引入了1×1卷积层。该层有助于控制输出信息并减少特征数量。局部特征融合的公式为Fd,LF = HdLFF([Fd−1, Fd,1, ..., Fd,c, ..., Fd,C]),其中HdLFF表示第d个RDB中1×1卷积层的函数。局部特征融合对于有效地训练具有更大增长率的非常深的密集网络至关重要。
局部残差学习(LRL):由于一个RDB中存在多个卷积层,引入局部残差学习来进一步改进信息传递。第d个RDB的最终输出通过Fd = Fd−1 + Fd,LF得到。局部残差学习增强了网络的表示能力,提高了性能。
3.3密集特征融合(DFF)
在这一部分中,作者介绍了他们提出的残差密集网络(RDN)的关键组成部分:残差密集块(RDB)和密集特征融合(DFF)。
首先,残差密集块(RDB)是RDN的基本构建模块。RDB包含了密集连接的卷积层,局部特征融合和局部残差学习。通过局部特征融合,RDB允许每个卷积层直接获取来自RDB前一层和当前RDB内所有卷积层的信息,从而生成密集的局部特征。这种特性被称为连续的内存机制(CM),有助于充分利用所有卷积层的信息。此外,局部残差学习进一步增强了信息流动,有助于提高网络的表征能力。
其次,密集特征融合(DFF)用于全局地融合从所有RDB中提取的局部密集特征。DFF包括全局特征融合(GFF)和全局残差学习。全局特征融合通过融合来自所有RDB的特征图来生成全局特征。通过全局残差学习,全局特征与浅层特征进行融合,形成密集的全局特征。
总的来说,RDN的创新在于它充分利用了所有卷积层生成的局部密集特征,而不仅仅使用最后一层的特征来进行上采样。同时,它还通过密集特征融合将这些局部特征融合成全局特征,进一步提高了网络的表现能力。这种设计使得RDN在图像超分辨率和其他图像恢复任务中取得了优异的性能。
DFF:把多个RDBs的输出concat在一起-----经过1*1的卷积将这一系列不同level的特征自适应地融合在一起------再经过3*3卷积,得到FGF
FDF =FGF+F-1
3.4上采样网络:亚像素卷积
4. Discussion
这段文字指出了RDN和DenseNet之间的主要区别,并解释了为什么在RDN中采用了局部密集连接(local dense connections),以及为什么去除了批标准化层(batch normalization,BN层)和池化层(pooling layers)。
主要区别如下:
目标任务不同:DenseNet通常用于高级计算机视觉任务(如目标识别),而RDN是为图像超分辨率(image SR)任务而设计的。
局部密集连接:受到DenseNet的启发,RDN采用了局部密集连接的思想,使得每个RDB中的每一层都可以直接访问前面所有的层。这样做的好处是在RDB内部充分利用了层之间的信息,有助于提高特征的表示能力。
去除BN层:为了降低网络的计算复杂度并提高性能,RDN去除了批标准化层。BN层需要额外的计算,并且与卷积层一样占用显存,因此去除BN层可以使网络更加高效。
去除池化层:池化层通常会丢弃一些像素级的信息,而在图像超分辨率任务中,保留尽可能多的细节信息是很重要的。因此,RDN去除了池化层,以避免丢失有用的信息。
全局特征融合:RDN引入了全局特征融合,以充分利用来自不同RDB的层级特征。这些层级特征在DenseNet中被忽略了。全局特征融合的过程允许RDN从全局的角度提取特征,从而进一步提高了性能。
RDN与SRDenseNet的主要区别:
基本构建块设计:SRDenseNet引入了DenseNet中的基本密集块。而RDN引入了自己的改进版本,即RDB,增加了连续内存(CM)机制、允许更大的增长率以及使用局部残差学习(LRL),从而提高了网络性能和训练稳定性。
稠密连接:SRDenseNet使用了密集连接,但RDN中的RDB已经在局部完全提取了特征,因此RDN采用了全局特征融合(GFF)和全局残差学习来提取全局特征。
损失函数:SRDenseNet使用L2损失函数,而RDN使用L1损失函数,后者在性能和收敛性方面更有效。
RDN与MemNet的主要区别:
损失函数:MemNet使用L2损失函数,而RDN使用L1损失函数。
上采样过程:MemNet需要使用双三次插值将原始LR图像上采样到所需尺寸。而RDN直接从原始LR图像中提取层次特征,大大减少了计算复杂度并提高了性能。
记忆块内连接:MemNet中的记忆块包含递归单元和门单元,大多数递归单元内的层不接收其前面层或记忆块的信息。然而,在RDN中,RDB的输出直接连接到下一个RDB的每一层,并且RDB内的每个卷积层的信息在RDB内的所有后续层之间流动。此外,RDB中的局部残差学习改进了信息和梯度的传递,从而提高了性能。
全局特征融合:MemNet虽然在HR空间中采用了记忆块之间的密集连接,但未能充分从原始LR输入中提取层次特征。而RDN在使用RDB提取了局部密集特征后,还使用全局特征融合在LR空间中进一步融合来自整个前面层的层次特征。
5 数据集
训练:
采用的数据集为2K的高清RGB图像数据集——DIV2K,该数据集的训练集有800张图片,验证集有100张图片,测试集有100张图片。
测试: 使用了5组标准benchmark数据集:Set5,Set14,B100,Urban100,Manga109。
Degradation Models 分别使用了3种降阶模型对HR的DIV2K进行处理,来模拟LR图片。
BI: 用Matlab的imresize函数进行bicubic下采样,缩小比例为x2,x3,x4;
BD: 采用高斯核大小为7*7、标准差为1.6的高斯滤波处理,下采样的比例为x3;
BN: 先bicubic下采样,再加30%的高斯噪声。
6.Conclusions
本文提出了一种非常深的残差密集网络(RDN)用于图像超分辨率,其中残差密集块(RDB)作为基本的构建模块。通过局部和全局特征的充分利用,RDN实现了密集特征融合和深度监督,在多个评估基准上取得了优越性能