oriented rcnn代码解析
文章目录
- rpn_head.forward_train
- roi_head.forward_train
class OrientedRCNN(RotatedTwoStageDetector)
类似rotated faster rcnn它们都继承两阶段检测器类。
所以训练的整体框架都如下: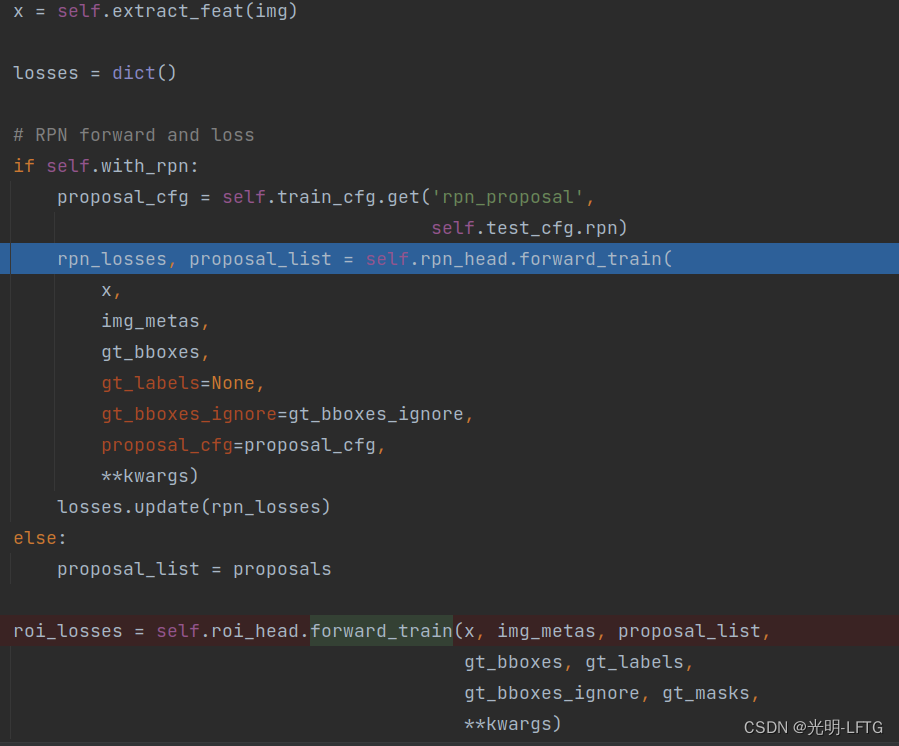
rpn_head.forward_train
代码主体👇
outs = self(x)
if gt_labels is None:loss_inputs = outs + (gt_bboxes, img_metas)
else:loss_inputs = outs + (gt_bboxes, gt_labels, img_metas)
losses = self.loss(*loss_inputs, gt_bboxes_ignore=gt_bboxes_ignore)
if proposal_cfg is None:return losses
else:proposal_list = self.get_bboxes(*outs, img_metas=img_metas, cfg=proposal_cfg)return losses, proposal_list
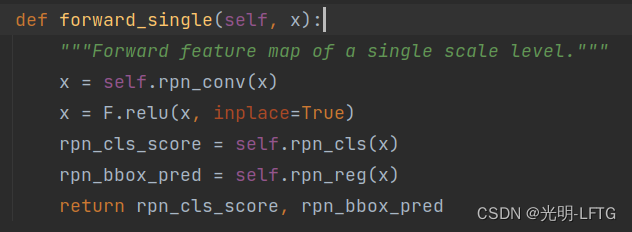
- forward部分:
这一部分可以看到和faster rcnn是一致的,只不过faster初始化的时候
rpn_cls=nn.Conv2d(256,anchorcls_out_channels,1)
rpn_reg=nn.Conv2d(256,anchor4,1)
而oriented rcnn中
rpn_reg=nn.Conv2d(256,6,1)
看过oriented_rcnn的论文的朋友知道,oriented rcnn预测的不是角度,而是offset,用于调整框,所以这里改成了6而不是4
对于oriented rcnn number_anhcors=3而不是faster中的5
还有一个值得注意的细节是这里的rpn_cls是预测出前景的概率而不是类别概率,所以实际上对于一个特征图的一个特征点,它是一个标量而不是向量。
- loss部分(以下为get_anchors和get_targets部分)
为了计算loss,参考上一个faster的文章:
下面三个函数共同组成了rpn_head.loss
self.get_anchors
self.get_targets
self.loss_single
其逻辑也很清晰:
get_anchors利用anchor_generator,xyxy格式
get_targets根据anchor来匹配对应的gt(cxcywha)(所以gt到这就利用好了,下面的loss只需要根据这一步的返回来计算,不再需要输入gt)
loss_single用于计算具体的loss。
get_anchors并不过多作介绍,这里介绍以下get_targets虽然继承的是同faster的rpn_head的部分,但是复写了_get_targets_single部分所以有必要说一下。
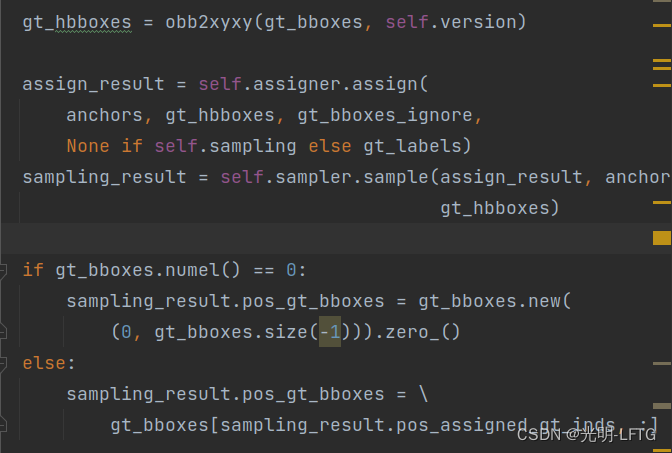
由于二者之间最大的区别就在于self.bbox_coder.encode这一部分,但是这里看到gt_hbboxes已经通过obb2xyxy转化成了没有角度信息的部分,用于assign和sample。
所以在
pos_bbox_targets = self.bbox_coder.encode( sampling_result.pos_bboxes, sampling_result.pos_gt_bboxes)需要修改pos_gt_bboxes的值,因为这里默认是gt_hbboxes中的信息。所以下面的代码中if判断语句中修改了pos_gt_bboxes的值。
这里anchors 和 gt_hbboxes都是xyxy形式。
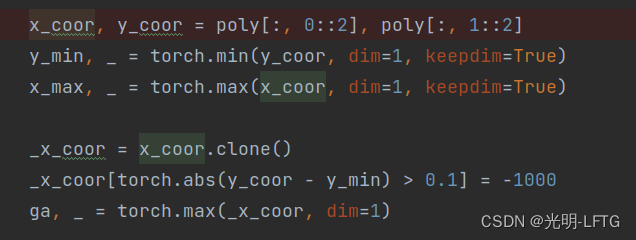
这里展示了da,db的定义方
gx,gy是外接矩形的中心点
gw,gh是外接矩形的宽高
ga是最下面点的x坐标
gb是最右边点的y坐标
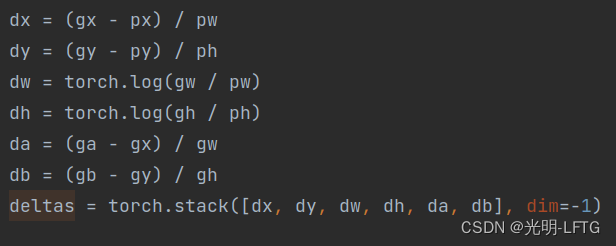
这一部分encoder的输出,作为bbox_targets的pos_id的部分得以保存。并且bbox_targets的neg_id的部分为0
return (labels, label_weights, bbox_targets, bbox_weights, pos_inds, neg_inds, sampling_result)这是get_targets_single的输出
labels(261888,)
bbox_targets(261888.6)
248个负例框,8个正例框
- loss_single(当然本质上也属于loss部分)
loss_cls=dict( type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0),
loss_bbox=dict( type='SmoothL1Loss', beta=0.1111111111111111, loss_weight=1.0)),
讲到这里反而没什么好说的了,就如同配置一样。
下面的cls_socres,bbox_preds是forward得到的
all_anchor_list是AnchorGenerater生成的
下面的5个参数都是sampler中输出的
losses_cls, losses_bbox = multi_apply(self.loss_single,cls_scores,bbox_preds,all_anchor_list,labels_list,label_weights_list,bbox_targets_list,bbox_weights_list,num_total_samples=num_total_samples)
- get_bboxes
首先,把anchors,cls_scores变成单张图片对应的部分计算
比如cls_scores变为cls_scores_list : list 5 0=tensor(3,256,256), 1=(3,128,128) …
cls_score为前面forward得到的
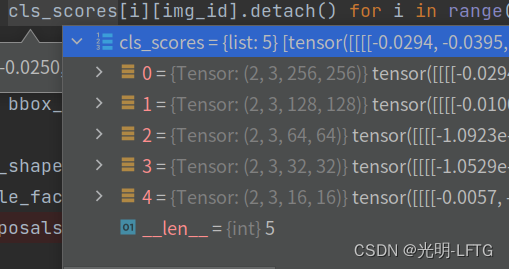
这里两个图片并在一个batch,但是每一个get_bboxes需要在单张图片上进行,所以无意外的,需要复写get_bboxes_single
然后送入get_bboxes_single
proposals = self._get_bboxes_single(cls_score_list, bbox_pred_list, mlvl_anchors, img_shape, scale_factor, cfg, rescale)
那么get_bboxes到底在做什么事情呢:同faster rcnn 就是把
- 层至多保留2000个,五个层加起来一共8000多个,按照得分排序
- decode
- nms一下(只剩不到一半了)
- 保留前cfg.max_per_img个
这里看到nms也是有点意思,并不是直接对旋转框nms而是把它们转为hbb再nms之后按照idx保留,绝了。
if proposals.numel() > 0:hproposals = obb2xyxy(proposals, self.version)_, keep = batched_nms(hproposals, scores, ids, cfg.nms)dets = torch.cat([proposals, scores[:, None]], dim=1)dets = dets[keep]
roi_head.forward_train
- assigner&sampler
在rpn中,这一部分没有做过多介绍,这里可以补充介绍一下。
通过一些代价损失函数和一些匹配策略,给框进行正负例匹配
常见的代价函数为MaxIoUAssigner,设置阈值0.7,0.3,中间的不做匹配。
roi_head.forward_train这个代码虽然是复写的,但与rotated faster rcnn不同的地方就在于assigner sampler
而faster这一部分只是简单的计算了hbb之间的iou
此刻我们需要注意,在rpn阶段,assigner和sampler可是实实在在的写在了get_targets里面,这里却写在了外面,
但是他们的逻辑是一样的,只不过一阶段时,bbox是生成出来的,而这里是前面rpn中get_bboxes筛出来。
回忆rpn中,先rpn_forward,再AnchorGenerator,就可以assigner&sampler+get_targets,然后计算loss。
这里顺序变了一下:
因为在rpn中,anchor是根据特征图的点逐点生成的,但是这里的box是筛选出来的,后面需要特地作roi_extractor,再forward得到scores bbox_preds
所以这里就先作了一次assigner&sampler,其实放到后面做好像也可以,不过这里还有一个小作用就是把2000个框匹配一次之后筛到512个。后面的get_targets也就不用在
assigner=dict(type='MaxIoUAssigner',pos_iou_thr=0.5,neg_iou_thr=0.5,min_pos_iou=0.5,match_low_quality=False,iou_calculator=dict(type='RBboxOverlaps2D'),ignore_iof_thr=-1),
sampler=dict(type='RRandomSampler',num=512,pos_fraction=0.25,neg_pos_ub=-1,add_gt_as_proposals=True),
- _bbox_forward_train
# _bbox_forward_train
rois = rbbox2roi([res.bboxes for res in sampling_results])
bbox_results = self._bbox_forward(x, rois)bbox_targets = self.bbox_head.get_targets(sampling_results, gt_bboxes,gt_labels, self.train_cfg)
loss_bbox = self.bbox_head.loss(bbox_results['cls_score'],bbox_results['bbox_pred'], rois,*bbox_targets)bbox_results.update(loss_bbox=loss_bbox)
return bbox_results
这里rbbox2roi就是给图片加上了序号从1024,5 变成了1024,6(序号加在第一个维度)
于是进入了最重要的函数_bbox_forward(x,rois)
- _bbox_forward(x,rois)
bbox_feats = self.bbox_roi_extractor(x[:self.bbox_roi_extractor.num_inputs], rois)
if self.with_shared_head:bbox_feats = self.shared_head(bbox_feats)
cls_score, bbox_pred = self.bbox_head(bbox_feats)bbox_results = dict(cls_score=cls_score, bbox_pred=bbox_pred, bbox_feats=bbox_feats)
return bbox_results
roi_extractor这里是RotatedSingleRoIExtractor而不是rotated faster rcnn中的SingleRoIExtractor
(毫无疑问,这个函数对于p2rb来说起到至关重要的作用)
经过roi_extractor, 这里的bbox_feats ={Tensor:(1024,256,7,7)}
cls_score, bbox_pred = self.bbox_head(bbox_feats)
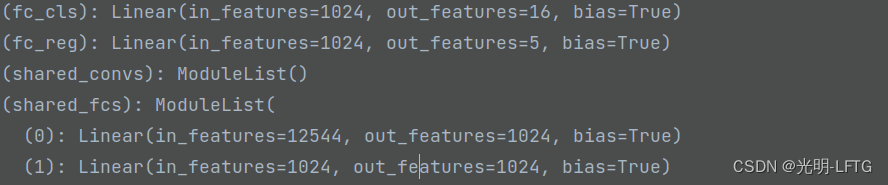
这里可以看到,最重要的东西往往最简单。是这样的。
- self.bbox_head.get_targets
可以看到,由于前面已经作了sampler,这里gt的信息都不需要再利用了。
至于get_targets_single,由于不需要assigner和sampler,只需要做一个啥呢??来得到那一套返回👇
return labels, label_weights, bbox_targets, bbox_weights
答案揭晓,就是encoder操作,获取bbox_targets,至于label_weights,bbox_weights,通过自定义+切片赋值
但是对于labels这一部分看似需要gt,实则当然需要,只不过sampling 中同样已经提取过一次信息。只需要从sampling中读取即可。
好了说到这里又水了一个函数,(不过前面大家看着理解就发现,已经很清晰了)
- loss
分析完这么多,觉得这反而是最不需要介绍的部分了。突然发现,很多时候,代码本身的核心思想所需要的部分,并不多,反而是搭建框架必须的细节很多。
其实forward经常就是几个卷积层 就写完了。
20220720加油,多看看代码,明显感觉自己学到了很多,也知道怎么去操作了,加油!!!毛毛