目录
一.决策树模型
二.学习过程
三.纯度(熵)
四.选择拆分信息增益
一.决策树模型
现在以识别猫为例,有三个特征,分别是耳朵,脸和胡须,然后每个特征都有两种输出(等价于二元分类)
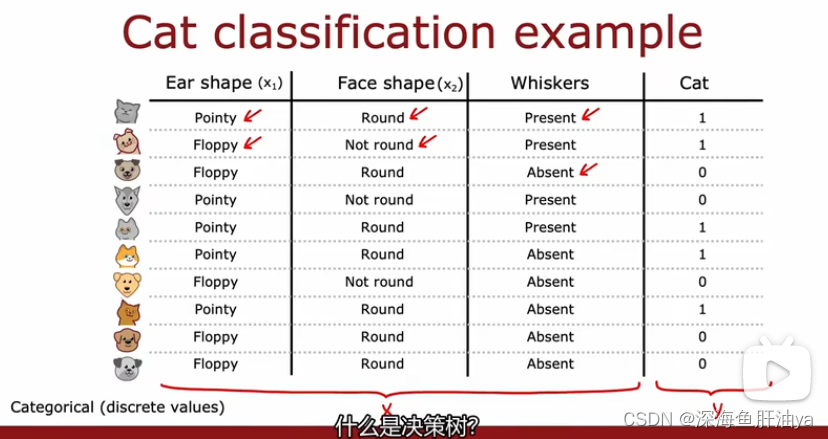
决策树模型:
椭圆的结点称为决策节点
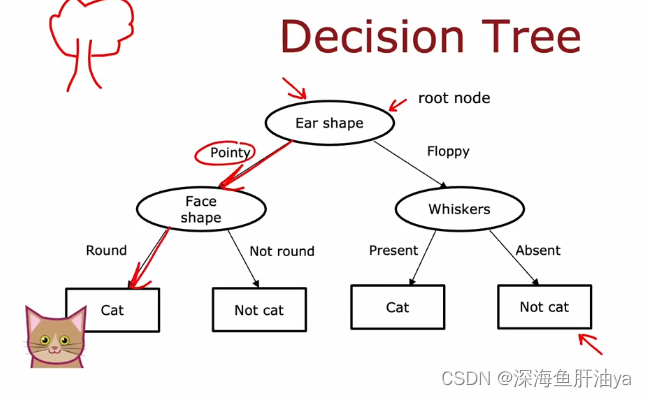
决策树也可以有多种不同的样子:
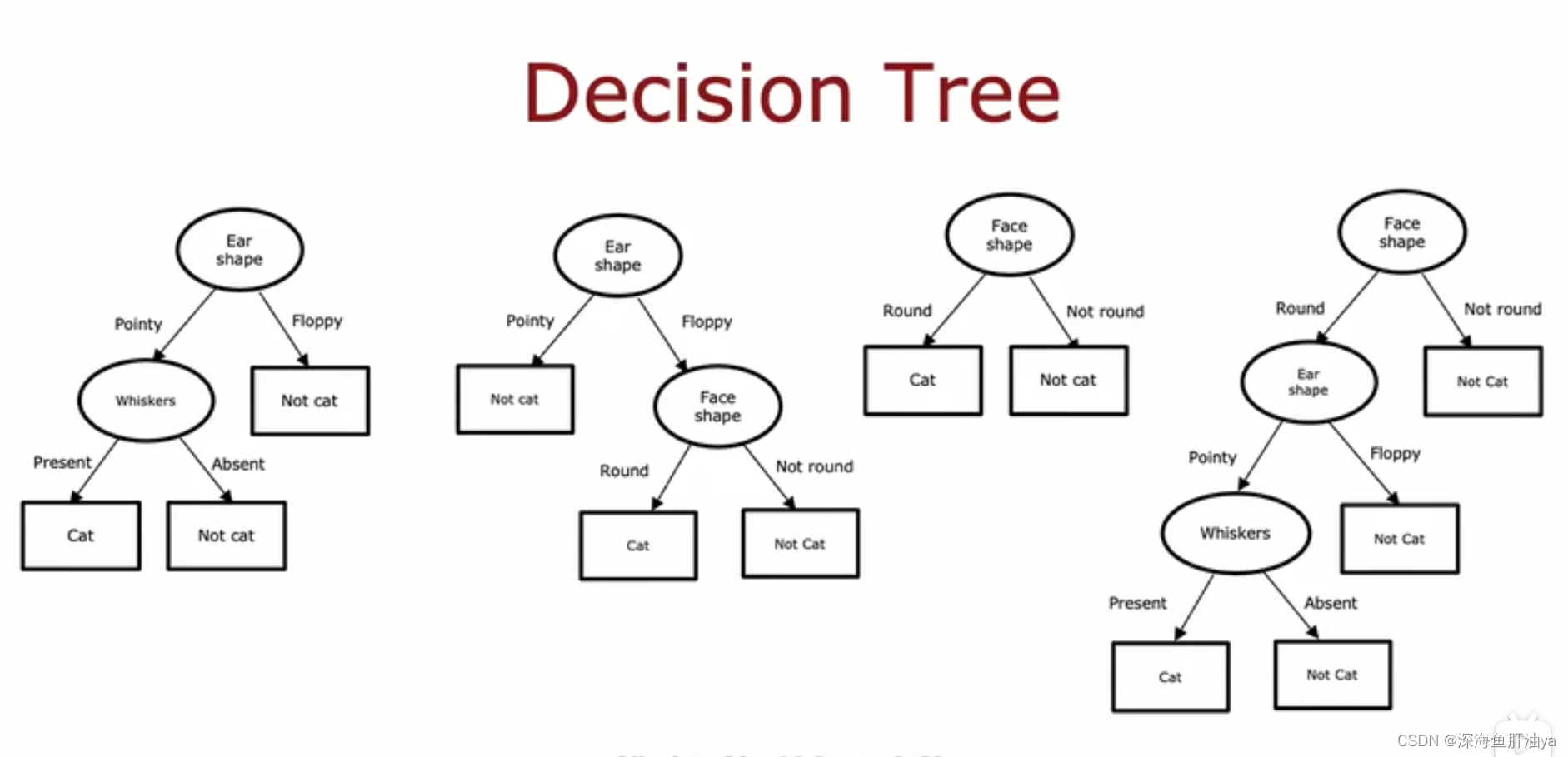
二.学习过程
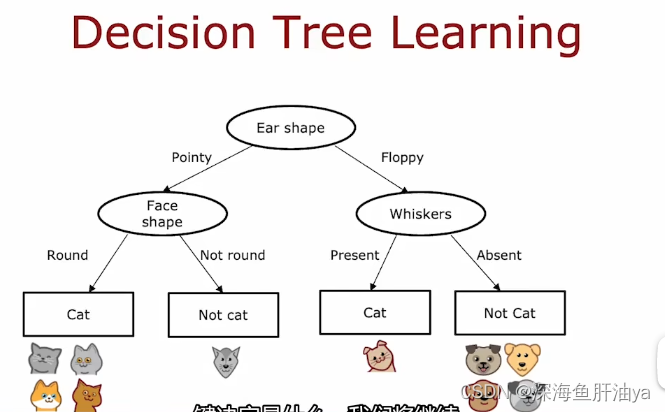
这图的形成过程是这样的:首先最开始有10个动物,我们开始构建根节点,选择一个特征在根节点上使用,比如耳朵,根据耳朵不同各自分到两边,然后以左边为例,再创建一个决策节点,然后在这个决策节点选择一个特征,比如脸的形状,又分到了两边,这时会发现刚刚分出来的这两侧已经一方都是猫,一方都是狗了,所以为这两方分别设置对应的叶子节点。
决策树学习过程:
Decision 1: How to choose what feature to split on at each node? (怎样为一个决策结点选择一个特征).
Maximize purity (or minimize impurity) 比如一个结点里猫的比例占多少,比例越高越纯,下面会详细讲到纯度的概念。
Decision 2: When do you stop splitting(何时停止分裂)?
●When a node is 100% one class(即这个结点里此时全是猫或全是狗)
●When splitting a node will result in the tree exceeding a maximum depth(设定一个最大的深度,当决策树的某个结点超过这个深度时就不会再分裂了),这样可以保证决策树不至于太大太笨重,而且可以降低过拟合的风险。
●When improvements in purity score are below a threshold(如果分裂节点对于纯度的改善低于某个阈值就停止分裂)
●When number of examples in a node is below a threshold(当一个节点里的训练示例的数量低于某个阈值时)
三.纯度(熵)
先看一下熵(entropy)的定义,熵是衡量一组数据纯不纯的指标。
p1是猫训练示例的比例,下图左侧图像横轴是p1,纵轴是熵。

可以看到并不是猫的比例占的越大熵就越小,有2个猫时的H是0.92,有3个猫时H是1,这是为啥呢???而且猫的数量是0时,H是0时,这就涉及到数学中熵的定义了,熵的本质是一个系统“内在的混乱程度”。突然想起了大学的时候被信息论支配的恐惧。
现在就明白了,虽然p1是猫的比例,但是混乱程度不是只由猫决定的,还由狗决定,所以当没有猫时,就是纯狗了,所以很纯净,不混乱,所以熵为0。这也是为什么两只猫时比三只猫时的熵要小 。熵越大代表越混乱。
来看一下熵的计算公式,如下,如果p1代表的是猫的比例,那么p0代表的就不是猫的比例,然后再看下面的这个公式

注:“0log(0)”=0 是因为当x趋近于0的时候,xlogx的极限就是0
四.选择拆分信息增益
前面提到过的在决策节点上选择哪个特征来进行决策,这要看用哪个特征能最大化减少熵。
熵的减少称为信息增益。下面来看一下如何计算熵的减小。
起初我们有三个特征,要在根节点选择使用哪个特征来进行第一步决策,然后每个特征都要试一试,以选择耳朵特征来决策举例说明,本来分类之前是10个动物(五只猫五只狗),用耳朵分类之后。左侧是五个动物(其中4猫1狗),右侧是五个动物(其中1猫4狗),所以左侧的p1(猫的比例)是4/5,右侧的p1是1/5,然后带入熵计算公式中计算出左右两侧的熵分别是H(0.8)=0.72和H(0.8)=0.72,然后咱们需要计算加权平均熵,各侧的权值就是各侧的动物数除动物总数(注意下图的每个右侧都有一个狗头没显出来,那块阴影就是),所以咱们这个例子的加权平均熵就是
5/10*H(0.8)+5/10*H(0.8),然后我们要知道用这个特征来分类让熵减少了多少,就要知道根结点最初状态的熵是多少,初始状态是十个动物(5猫5狗),所以p1=5/10=0.5,熵是H(0.5)=1然年后用最初始状态的熵减去分类一次之后的加权平均熵得到信息增益(即熵减少了多少),然后另外两个特征也是如法炮制,可以得到三个特征如果被选择进行分类那么各自会得到的信息增益是0.28,0.03,0.12,咱们要选信息增益最大的(即熵减少最多的),即耳朵形状特征。
选熵减少最多的可以降低决策树深度超过设定的最大深度和过拟合的风险。

获取信息增益的普适性计算公式:
w就是上面每侧的动物数占父节点内的动物数的比例,比如脸特征,w^left=7/10,w^right=3/10