背景
一亿用户量,平均每人每天10次的业务量,要求并发数在5000以上,峰值在5w到10w之间,QPS在25w以上
一、jmeter解决高并发的优化方案
1.1 优化监听(GUI模式,尽量不考虑)
1.2 优化监听(Non-GUI命令行模式)
1.3 结果文件优化(结果数据一定要保存为CSV格式)
1.4 如果要超高并发建议不要直接使用分布式压测(可以采用多master多slave模式)
1.5 可以选择用Jmeter + Grafana + InfluxDB的方式,来代替报告文件的生成
1.6 尽量在linux下执行
二、Jmeter超高并发实现方案
采用Jenkins+Jmeter + Grafana + InfluxDB方案,Jenkins,influxdb,Grafana部署到同一台机器(配置尽量往高了搞),Jmeter分别部署到其他服务器,便于Jenkins统一调度
注:服务器之间内网连接
带宽尽量高一些
三,部署
3.1 Jenkins部署
参考:http://www.360doc.com/content/21/1209/15/78048805_1007851779.shtml
3.2 influxDB 部署
3.2.1 下载安装包
【官网地址:https://www.influxdata.com/】
【百度云下载:https://pan.baidu.com/s/1BH8NvzXLd5rnaYUNtLIPng
提取码:nnp3】
3.2.2 安装
解压:tar zxvf influxdb-1.8.4_linux_amd64.tar.gz
将解压后的文件移动到/usr/local/influxdb 路径下
编辑/usr/local/influxdb/etc/influxdb/influxdb.conf配置文件
在[[graphite]] 标签下,去掉注释
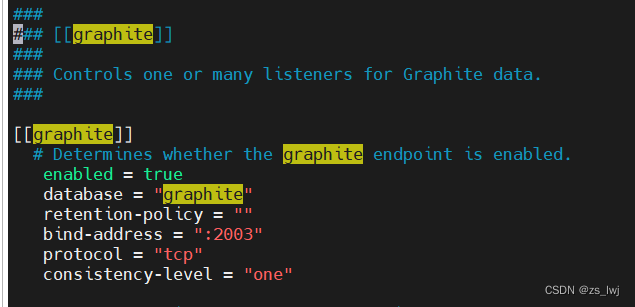
在[[http]] 标签下,去掉注释

切换到/usr/local/influxdb/usr/bin 目录下,将influxd 做成软链接放到/bin目录下
ln -s /usr/local/influxdb/usr/bin/influxd /bin
成功后,可直接influxd启动influxd服务。出现如下信息表示启动influxd服务成功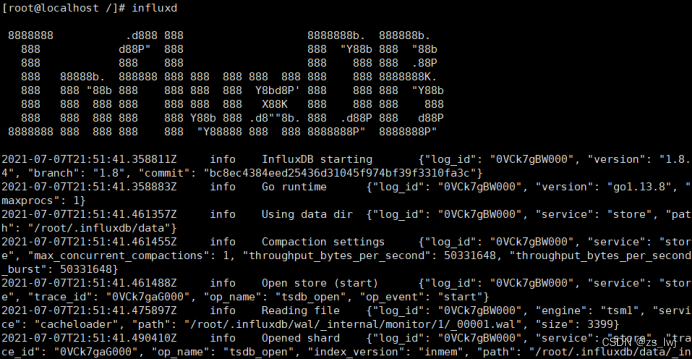
如果启动不成功,编辑/usr/local/influxdb/etc/influxdb/influxdb.conf中
bind- address = "127.0.0.1:8088",重新启动即可
将/usr/local/influxdb/usr/bin 目录下的influx 也做成软链接放到/bin 目录下。
ln -s /usr/local/influxdb/usr/bin/influx /bin
现在可以通过influx 命令直接访问influxdb数据库。

下面去创建一个jmeter数据库
create database jmeter
具体influxdb的使用命令,可参考: https://blog.csdn.net/qq_32014795/article/details/116518364
3.3 Grafana部署
3.3.1 下载安装包
官网下载:Grafana: The open observability platform | Grafana Labs
百度云下载:链接:https://pan.baidu.com/s/173m-d735gLmldGPpvRX4hg
提取码:ncwe
注:不要下载最新版本,尽量下载8.4.7这个版本,目前8.5.*版本无法导入模板
3.3.2 安装
yum install grafana-8.4.7-1.x86_64.rpm
注:rpm安装需要安装依赖包,尽量使用yum命令安装
通过rpm -qa | grep grafan查看是否安装成功

3.3.3 启动服务
systemctl daemon-reload
启动grafana 服务:systemctl start grafana-server
查看grafana 状态:systemctl status grafana-server
停止grafana 服务:systemctl stop grafana-server
服务启动好之后,可以通过localhost:3000/login地址访问,如果是要远程访问则需要开启3000的防火墙访问权限,如下:firewall-cmd --zone=public --add-port=3000/tcp --permanent
firewall-cmd --reload
3.3.4 登录
浏览器输入:ip:3000访问,初始账号密码是admin,admin

登陆后可修改密码
3.3.5配置
在设置-> Data Sources
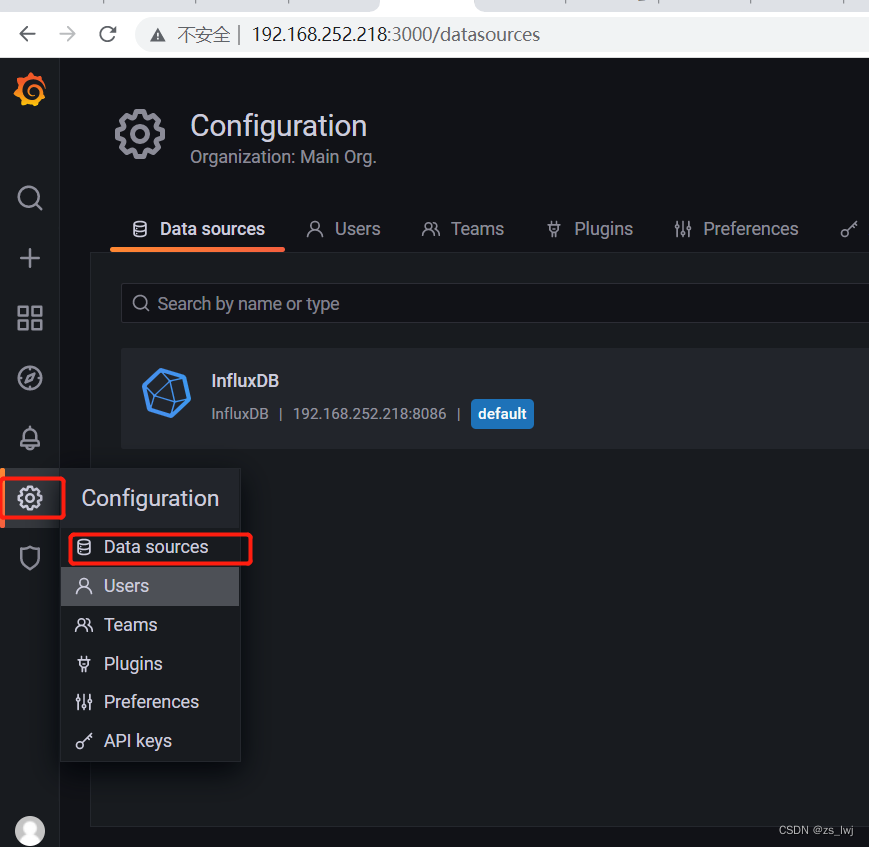
Add data source

搜索influxdb

配置influxdb

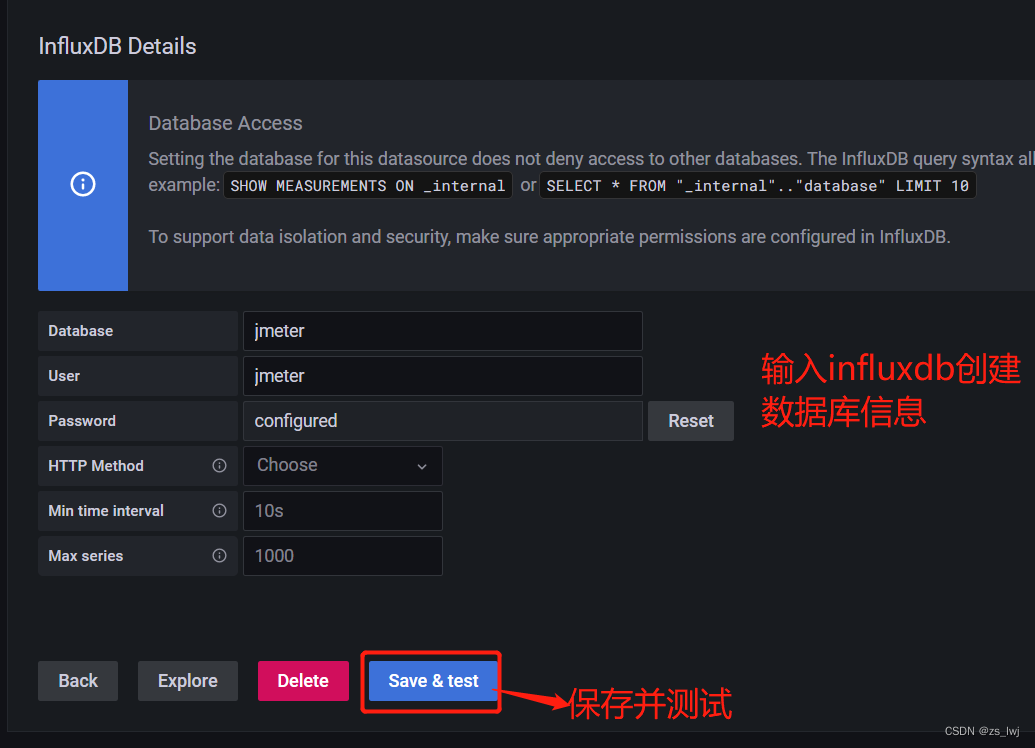
接下来是选择仪器表模板,在新建 --> import 中,如下图:
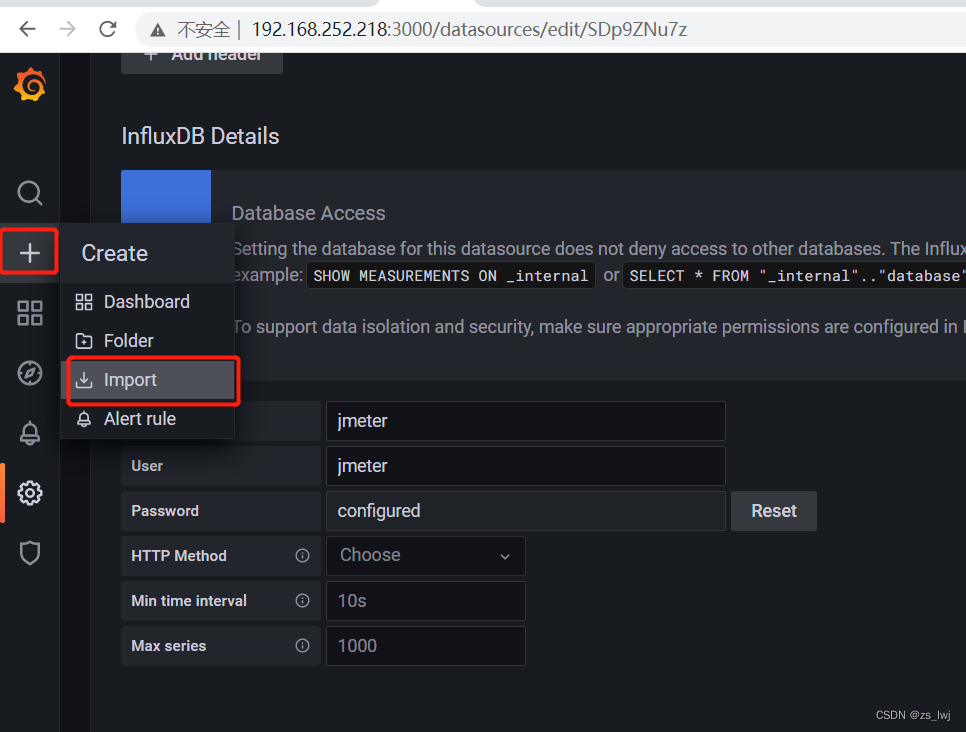
导入模板目前有两种方式,一种是直接通过url 或 模板id进行搜索,一种是通过在grafana官网下载好json格式的模板,手动导入。

下面是通过输入模板url地址进行导入模板,如下

 模板导入成功后,大致如下:
模板导入成功后,大致如下:
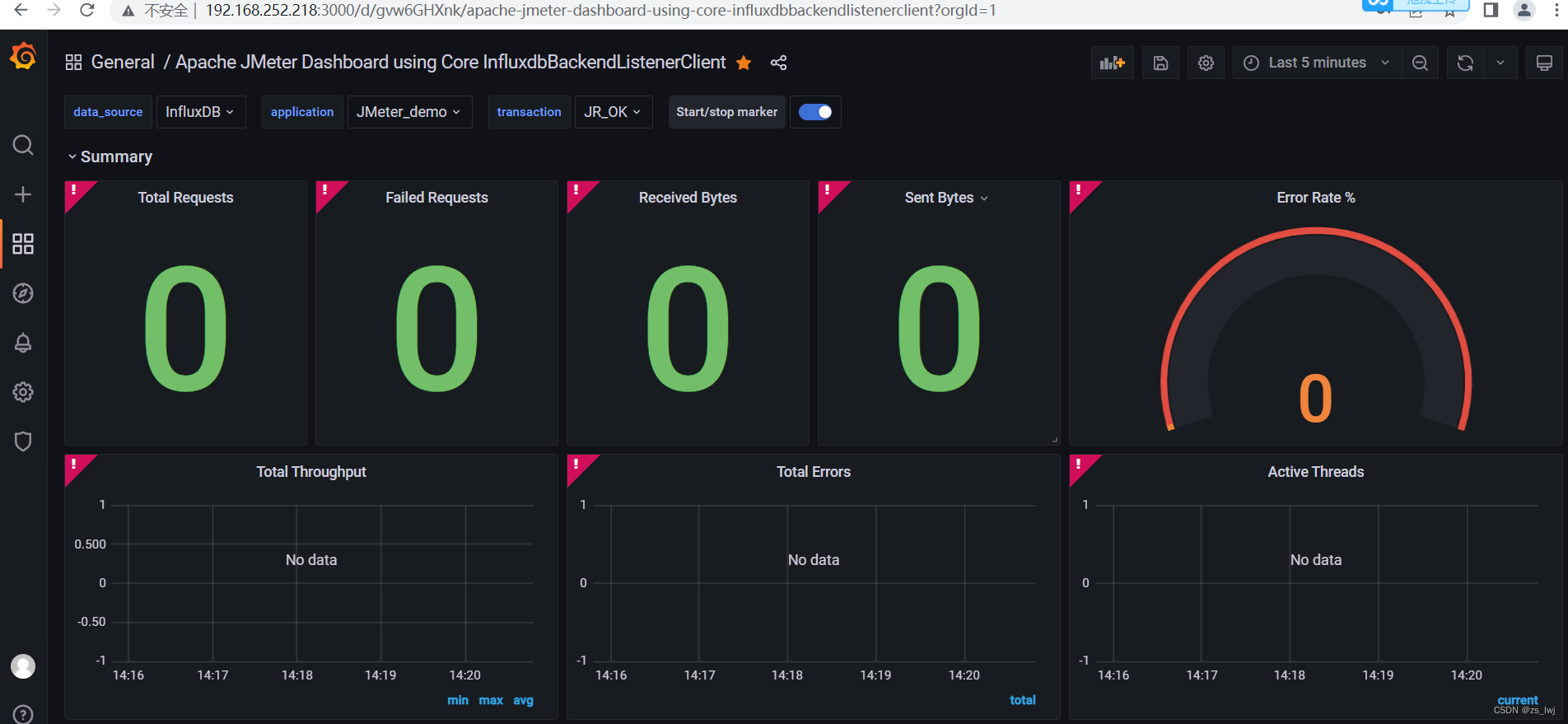
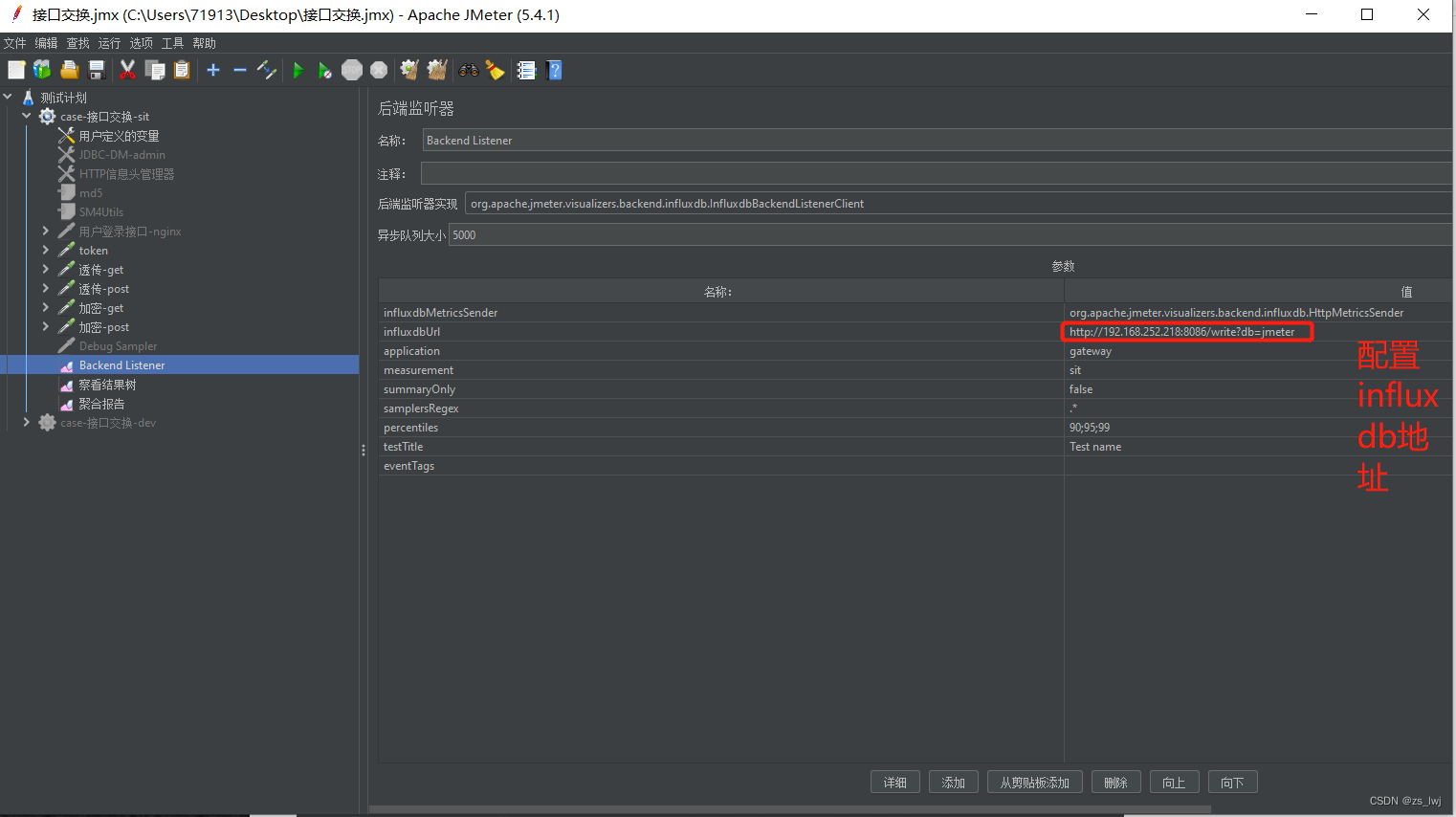
3.4 Jmeter配置
监听器增加后端监听器
3.6 服务器配置java+Jmeter环境
多台服务器,尽量配置同样的java及jmeter环境,另外Jmeter所需要的jmx及依赖文件尽量配置相同的路径
jmeter启动尽量使用shell脚本启动
如:#!/bin/bash
cd /data/testinterface/apache-jmeter-5.4.1/bin
./jmeter -n -t /data/testinterface/health-code/luohe-test/luohetest.jmx -l report.jtl
3.7 Jenkins同时调度多台服务器执行Jmeter脚本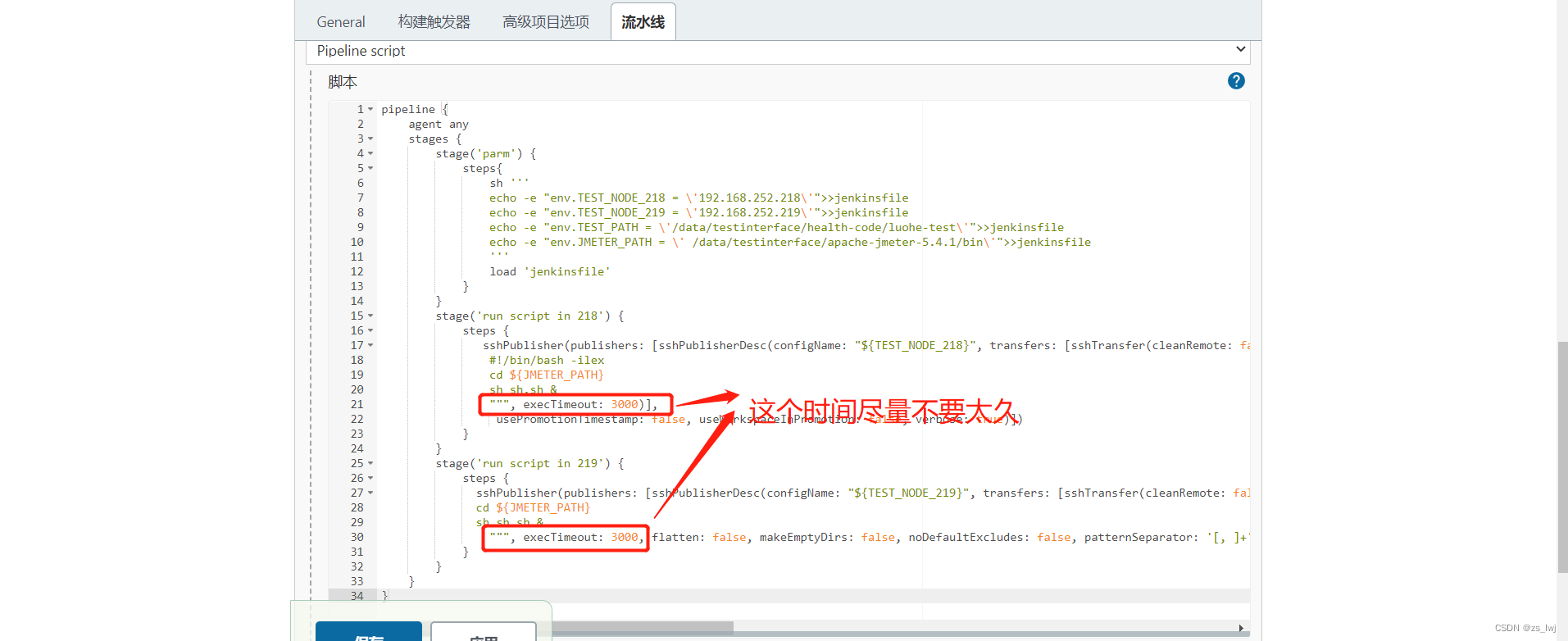
通过Jenkins执行后,结果如下:
 四:总结
四:总结
以上是针对多slave的模式进行,这样有个弊端,就是当并发量特别高的时候,需要更高的带宽来向influxdb写入数据,当然也可以考虑influxdb的集群模式进行
这种模式也可配合分布式使用,配置多master分布式和多influxdb的模式。