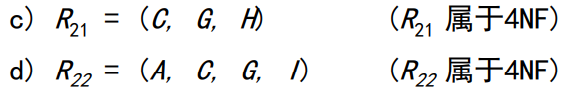范式:是符合某一种级别的关系模式的集合。
说白了,就是对关系模式的一种规范化。
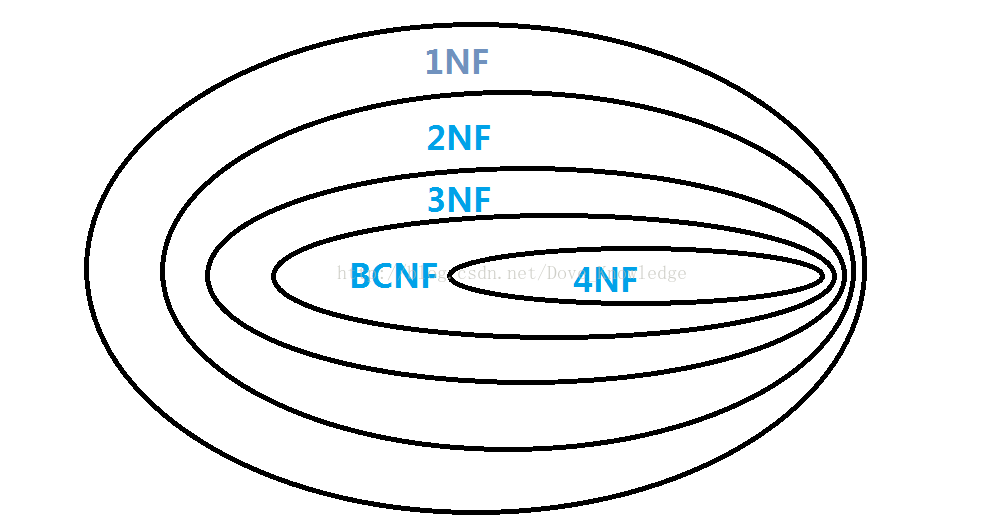
范式分为:第一范式、第二范式、第三范式、BC范式、第四范式、第五范式。后面两种在这里不讨论。
1、第一范式(1NF):关系模式S中的所有属性都是不可再分的基本数据项
人话解释:就是不允许表中还有表

数据库函数依赖
数据库码、属性的概念
2、第二范式(2NF):在第一范式的基础上,消除了非主属性对码的部分函数依赖
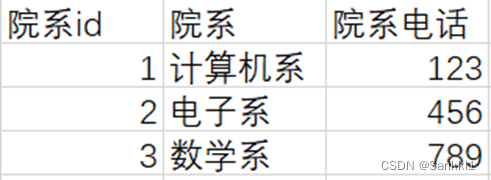
举个🌰:关系模式S(Sno,Cno,Sname,Grade)
很明显,属性Sname部分依赖于码[Sno,Cno],也就是说关系模式S不符合第二范式。
为了满足第二范式,可以把它拆成两个关系模式:
S1(Sno,Sname);S2(Sno,Cno,Grade)
3、第三范式(3NF):在第二范式的基础上,进一步消除了非主属性对码的传递函数依赖
举个🌰:关系模式S(Sno,Sname,Sdept,Mname)
(其中,属性Sdept表示学生所在的系,属性Mname表示系主任的姓名)
很明显,属性Mname传递依赖于码[Sno],也就是说关系模式S不符合第三范式。
为了满足第三范式,可以把它拆成两个关系模式:
S1(Sno,Sname,Sdept);S2(Sdept,Mname)
4、BC范式(BCNF):在第三范式的基础上,进一步消除了主属性对码的部分函数依赖和传递函数依赖
注意:是“主属性”对码的部分函数依赖和传递函数依赖