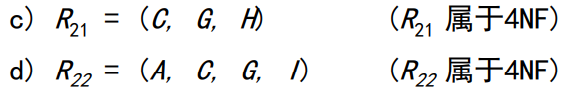目录
- 第一范式(1NF):原子性(存储的数据应该具有“不可再分性”)
- 第二范式(2NF):唯一性 (消除非主键部分依赖联合主键中的部分字段)(一定要在第一范式已经满足的情况下)
- 第三范式(3NF):独立性,消除传递依赖(非主键值不依赖于另一个非主键值)
- BC范式(BCNF)
- 第四范式(4NF):一个表的主键只对应一个多值
为了建立冗余较小、结构合理的数据库,设计数据库时必须遵循一定的规则。在关系型数据库中这种规则就称为范式。范式是符合某一种设计要求的总结。要想设计一个结构合理的关系型数据库,必须满足一定的范式。
第一范式(1NF):原子性(存储的数据应该具有“不可再分性”)
第一范式是最基本的范式。如果数据库表中的所有字段值都是不可分解的原子值,就说明该数据库表满足了第一范式。
第一范式的合理遵循需要根据系统的实际需求来定。比如某些数据库系统中需要用到“地址”这个属性,本来直接将“地址”属性设计成一个数据库表的字段就行。但是如果系统经常会访问“地址”属性中的“城市”部分,那么就非要将“地址”这个属性重新拆分为省份、城市、详细地址等多个部分进行存储,这样在对地址中某一部分操作的时候将非常方便。
第二范式(2NF):唯一性 (消除非主键部分依赖联合主键中的部分字段)(一定要在第一范式已经满足的情况下)
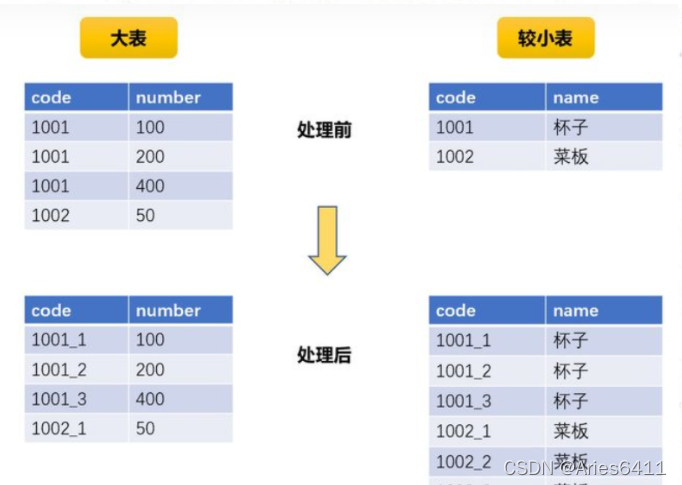
第二范式在第一范式的基础之上更进一层。第二范式需要确保数据库表中的每一列都和主键相关,而不能只与主键的某一部分相关(主要针对联合主键而言)。也就是说在一个数据库表中,一个表中只能保存一种数据,不可以把多种数据保存在同一张数据库表中。
比如要设计一个订单信息表,因为订单中可能会有多种商品,所以要将订单编号和商品编号作为数据库表的联合主键,如下表所示。
订单信息表
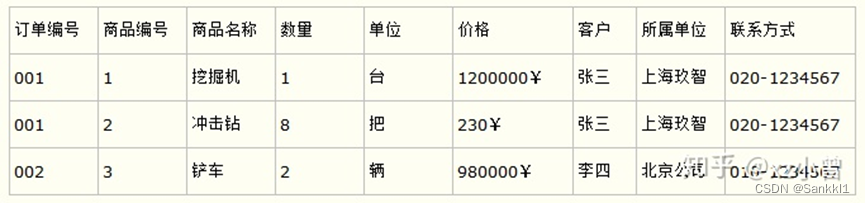
这样就产生一个问题:这个表中是以订单编号和商品编号作为联合主键。这样在该表中商品名称、单位、商品价格等信息不与该表的主键相关,而仅仅是与商品编号相关。所以在这里违反了第二范式的设计原则。
而如果把这个订单信息表进行拆分,把商品信息分离到另一个表中,把订单项目表也分离到另一个表中,就非常完美了。如下所示。
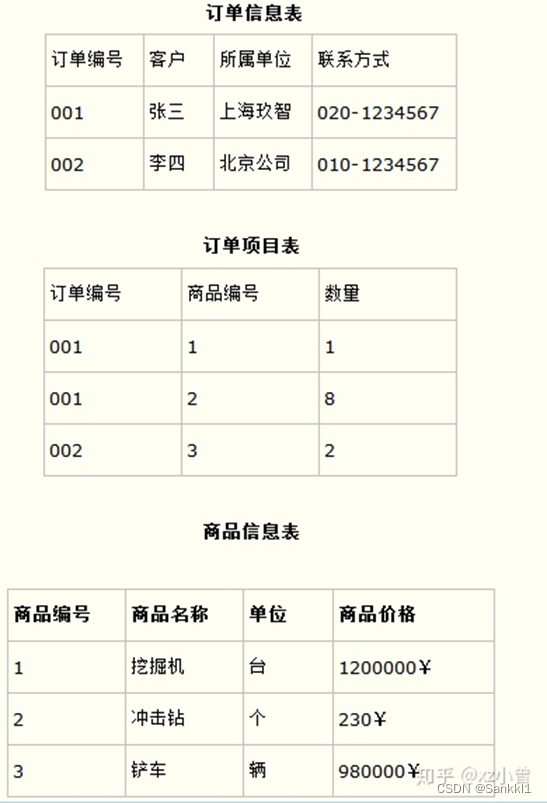
这样设计,在很大程度上减小了数据库的冗余。如果要获取订单的商品信息,使用商品编号到商品信息表中查询即可。
第三范式(3NF):独立性,消除传递依赖(非主键值不依赖于另一个非主键值)
在一个具有主键的表中,假设主键为A,其必然其他非主键都依赖于该主键,比如:B依赖于A,C依赖于A,D依赖于A。。。。。。
但同时:如果该表中的某个字段B的值一确定,就能够确定另一个字段的值C,则我们称为C依赖于B。
那么,就出现了:
C依赖B,B依赖A——这就是传递依赖。
则消除该传递依赖的的通常做法,就是将C依赖于B的数据,分离到另一个表中。
好了,还是蒙蒙的吧,上例子:
不良例子:
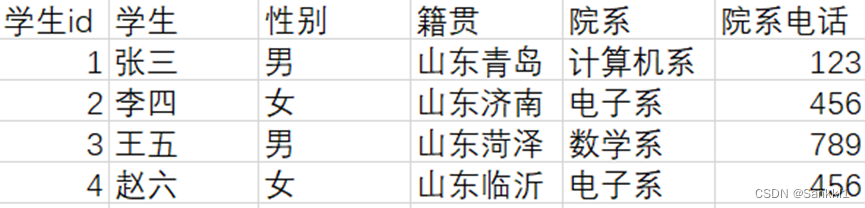
以上表既满足第一范式也满足第二范式,非主键字段也完全依赖于主键字段。
但是,院系电话字段,其实是依赖院系字段的。也就是说,院系电话字段是非主键值,而依赖了另一个非主键值-院系。所以就不符合第三范式。
改良:
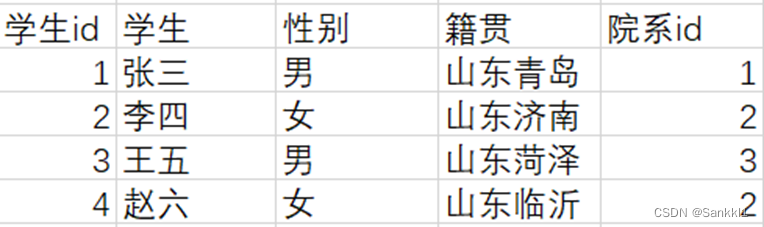
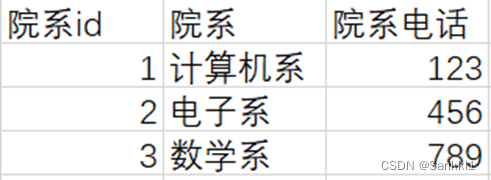
一个学生表,一个院系表,一目了然。
如果修改了院系信息,对应着也不需要修改学生信息表。但是如果还是使用以上不良例子的话,修改其中一个院系信息,得对应修改所有所属该院系的学生。
BC范式(BCNF)
数据库的三大范式只是最基本的,而BC范式也常与他们放到一起讨论,因为BCNF也被称为修正的第三范式,又或者说是扩充的第三范式。
为什么叫修正的第三范式?那么表示第三范式肯定有所缺漏,那么缺漏是什么呢?又如何补救呢?
我们看到第三范式的要求是每一个非主属性都要直接依赖于主属性,看似完美,可是如果除了主属性外,还有一个候选码呢?
显然从定义可以知道,这个主属性肯定能和候选码一一对应的,那这样岂不是又会造成冗余?
觉得很抽象吗?举个例子:
仓库(仓库编号,货物编号,仓库管理员编号)
其中每一个仓库管理员只管理一个仓库。
那么我们可以发现这里其实主码可以有两种,分别是:
(仓库编号) 可唯一确定 (仓库管理员编号,货物编号)
(仓库管理员编号) 可唯一确定 (仓库编号,货物编号)
必须要承认上述关系是符合第三范式的吧,但是有没有觉得这样仓库管理员编号会出现大量的没必要的冗余啊,因此BC范式就是解决这个问题的,需要将其改为两个表,顺便可以将货物的数量加进来。
至于为什么上面关系中我不将货物数量加进来,是因为一旦加进来后那个关系就不符合第二范式了,想想看,如果加入货物数量,那么主键就变成了(仓库编号,货物编号),可是仓库管理员只与仓库编号有关,不依赖于货物编号了呀,就不构成对主键的完全依赖关系了。
下面放上BC范式的修改版:
仓库与管理员表(仓库编号,仓库管理员编号)
仓库货物表(仓库编号,货物编号,货物数量)
第四范式(4NF):一个表的主键只对应一个多值
对于每一个X->Y,X都能找到一个候选码( 若关系中的某一属性组的值能唯一地表示一个元组,而其真子集不行,则称该属性组为候选码)。
设R是一个关系模型,D是R上的多值依赖集合。如果D中存在凡多值依赖X->Y时,X必是R的超键,那么称R是第四范式的模式。
例如,职工表(职工编号,职工孩子姓名,职工选修课程),在这个表中,同一个职工可能会有多个职工孩子姓名,同样,同一个职工也可能会有多个职工选修课程,即这里存在着多值事实,不符合第四范式。如果要符合第四范式,只需要将上表分为两个表,使它们只有一个多值事实,例如职工表一(职工编号,职工孩子姓名),职工表二(职工编号,职工选修课程),两个表都只有一个多值事实,所以符合第四范式。
参考资料
https://www.cnblogs.com/yinyoupoet/p/13287430.html
https://blog.csdn.net/A_art_xiang/article/details/113880638
https://www.jianshu.com/p/71563d6b121d