我们从两个方向讲解二叉树的前序遍历(递归+迭代)
一.递归
思想:
从根节点开始向其左孩子遍历每经过一个节点记录一下该节点的数值(只在第一次经过该节点时进行记录),当走到NULL时返回上一个节点,然后遍历其右孩子,如果右孩子存在记录其数值,再重复上面操作,如果不存在为NULL直接返回上一个节点再重复上面的操作.
代码如下:
void BTreePrevOrder(struct TreeNode* root,int* a,int* returnSize){//前序遍历if(NULL==root){//判出条件return;}a[(*returnSize)++]=root->val;BTreePrevOrder(root->left,a,returnSize);BTreePrevOrder(root->right,a,returnSize);
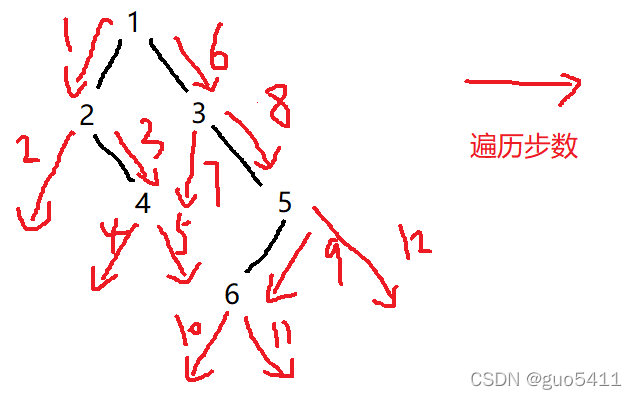
}具体运行过程:(如图)
二.迭代
思想:
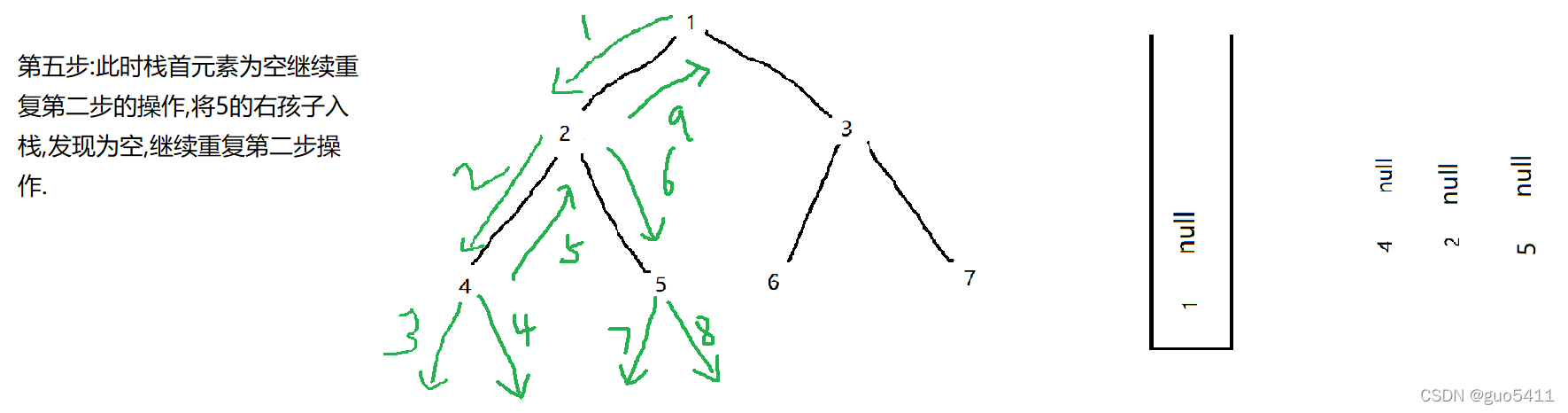
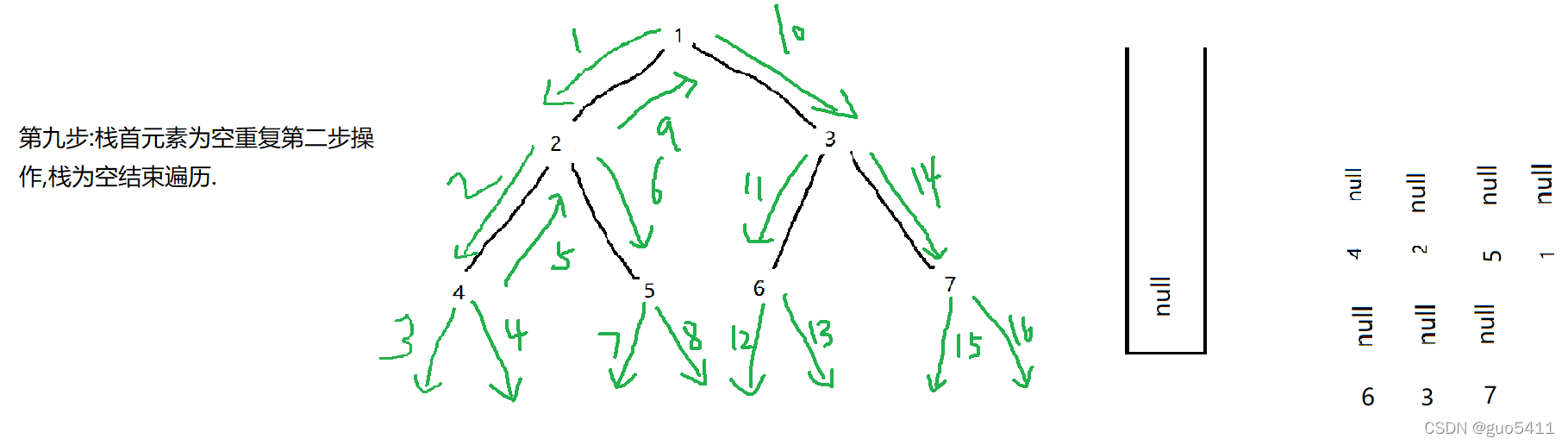
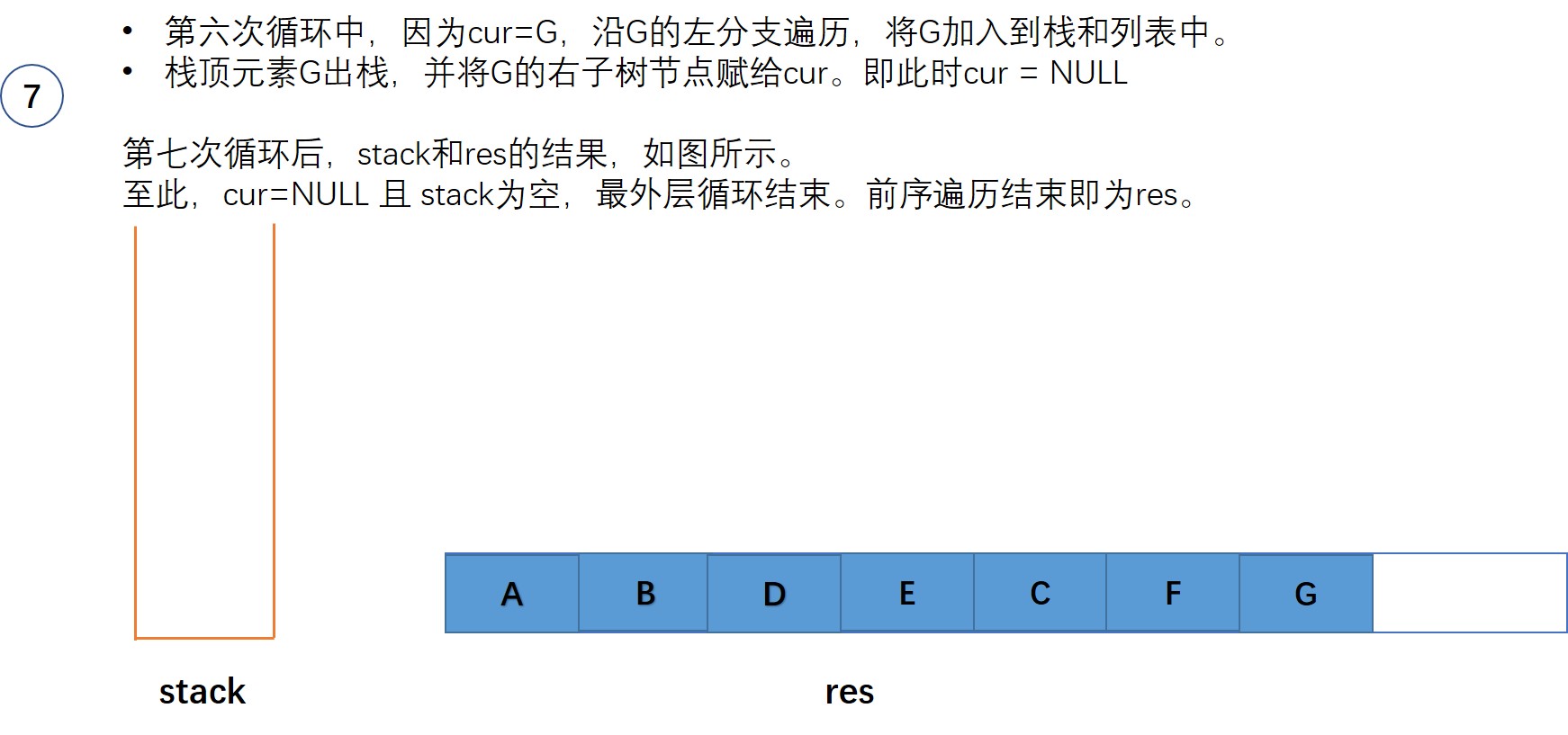
首先我们要知道递归的过程就是一个入栈和出栈的过程,所以我们可以使用迭代来模仿这个入栈和出栈的过程从而实现二叉树的前序遍历,首先判断该二叉树是否为空是空直接返回,不是空则进行前序遍历,将根节点入栈,一直将栈首元素的数值记录然后再将其左孩子入栈,当某个时刻栈首元素为空时,进入循环先将该空的节点出栈,然后记录新的栈首元素后将其出栈,此时的栈首元素为其上一层元素,方便其返回上一层,然后将记录的节点的右孩子入栈,为空继续循环,不为空退出循环重复上述操作.(具体过程看下图)
代码如下:
typedef struct TreeNode BTNode;typedef struct Stack{//构建栈的结构体BTNode* root_a[100];//存二叉树的节点的数组int size;//表示存储个数
}Stack;void PushStack(Stack* b,BTNode* root){//入栈b->root_a[b->size++]=root;
}void PopStack(Stack* b){//出栈b->size--;
}int* preorderTraversal(struct TreeNode* root, int* returnSize){int* a=(int*)malloc(sizeof(int)*100);//创建数组用来存储二叉树前序遍历的值if(NULL==a){printf("申请节点失败!\n");return NULL;}Stack b;//创建栈BTNode* pop_temp;//用来记录将要出栈的节点b.size=0;int i=0;PushStack(&b,root);//先把根节点入栈while(NULL != b.root_a[b.size-1]){a[i++]=b.root_a[b.size-1]->val;//第一次访问该节点时记录其值PushStack(&b,b.root_a[b.size-1]->left);//将该节点的左孩子入栈如果为NULL进入下一个
//循环while(NULL == b.root_a[b.size-1]){PopStack(&b);//先把这个为NULL的节点出栈if(0==b.size){//如果栈为空则遍历结束退出循环(*returnSize)=i;return a; }pop_temp=b.root_a[b.size-1];//记录上一个节点PopStack(&b);//将其出栈,使其返回时可以直接进入上一层的节点PushStack(&b,pop_temp->right);//将该节点的右孩子入栈}}(*returnSize)=i;return a;
}具体运行过程:(如图)