elasticsearch搜索分数自定义以及相关度计算相关
es通过其score字段对搜索结果进行排序 在进行业务开发时通常其默认的分数计算是不符合预期的。
最简单的方法是通过boost字段来对每一个字段进行权重设置,来体现该字段的重要性。
boost字段会导致分数的计算公式发生改变,boost默认为1 例如:
GET productinfo/_search
{"_source": ["spuTitle","classifyName"], "query": {"bool": {"should": [{"match": {"spuTitle": {"query": "服装","boost": 1}}},{"match": {"classifyName.text": {"query": "运动","boost": 1}}}]}}
}
这样的一段简单搜索,根据should匹配标题和分类,通常默认的权重两者都为1,但是我们的搜索结果为

很明显,我们可能需要将分类为运动的相关命中条目优先展示,但是结果是第二条便出现了服装鞋履分类,而后续的条目还有运动相关的条目,这并不符合我们的预期,我们需要将运动的权重设置更高,例如:
GET productinfo/_search
{"_source": ["spuTitle","classifyName"], "query": {"bool": {"should": [{"match": {"spuTitle": {"query": "服装","boost": 1}}},{"match": {"classifyName.text": {"query": "运动","boost": 5}}}]}}
}
此时将分类的boost设置为5之后,结果为:

看似达到了我们的预期,但是当需要考虑的字段过多时,boost这种简单的方式就显得不够灵活了,当然如果我们从多个索引中查询,也可以对索引进行boost的权重设置,例如:
GET /productinfo_*/_search
{"indices_boost": { "productinfo_1": 3,"productinfo_2": 2},"query": {"match": {"text": "运动鞋"}}
}
es为我们提供了一种有效的分数自定义方式,非常灵活,接下来我们将使用functionscore来重定义我们的分数
首先我们需要一个在索引mapping里自定义一个用于影响分数计算的字段myscore,type=long
我们通过权重设置来进行优先级的排序,而自定义分数更多的是用于在业务上的干预。例如通过热度来提升相应的优先度。
使用functionscore后的查询为:
GET productinfo/_search
{"explain": true,"query": {"function_score": {"query": {"bool": {"should": [{"match": {"spuTitle": {"query": "服装","boost": 1}}},{"match": {"classifyName.text": {"query": "服装","boost": 1}}}]}}, "functions": [{"field_value_factor": {"field": "score" ,"modifier": "log2p", "factor": 10}}], "score_mode": "sum", "boost_mode": "sum"}}
}
functionscore通常有以下几种方式:
- weight(权重,score*weight)
- field_value_factor(通过该值来加入自定义的因素进行考虑)
- random_score(对每一个用户使用一致的随机评分,即一个用户看到的始终是不变的,但每个用户不同)
- 衰减函数-linear、 exp 、 gauss(通常应用于经纬度的因素考虑)
- script_score(自定义分数脚本,上述无法实现需求时通过Groovy来编写)
上述使用第二种方式加入一个自定义分数字段来影响es的评分。
上述参数中,modifier参数用于平滑分数计算的方式,如果只定义field字段,不定义modifier,或者其他属性,分数计算公式为:
oldscore * myscore
上述分数计算方式是线性的,对结果影响较大,明显不符合我们的需求。
而引入modifier之后,在查询时加入 “explain”: true,可以看到解析本次查询,可以看到,
{"value" : 0.30103,"description" : "min of:","details" : [{"value" : 0.30103,"description" : "field value function: log2p(doc['score'].value * factor=1.0)","details" : [ ]},{"value" : 0.4,"description" : "maxBoost","details" : [ ]}]}
description字段列出了我们设置的functionscore,即:
log2p(doc[‘score’].value * factor=1.0)
即以10为底取我们自定义的myscore字段的值乘以factor2的对数
即log10(2),由于自定义score为0所以结果为

与上述分数结果一致。
score_mode:
score_mode参数是functionscore内的一组设置的打分方式,默认为multiply也就是相乘,即一组funtionscore内的几项设置打分结果相乘,为了避免系数威力过大,建议设置为sum
boost_mode:
score_mode是设置查询外部打分与functionscore之间的模式,默认也为multiply,设置为sum
max_boost
除上述两种模式可以设置之外,还可以设置max_boost参数,该参数用来限制functionscore的打分结果,最大不超过指定值,如果超过指定值,将使用指定值作为计算结果
weight的作用
weight作为functionscore的一种方式,类似于boost,例如当我们有两个自定义分数条件,一个为热度分数,一个为店铺评分,我们想要店铺的评分更加重要,就可以适当调整weight参数使得店铺评分比weight评分更高
衰减函数(一般用于经纬度位置计算,越近距离优先度越高)
高斯衰减曲线
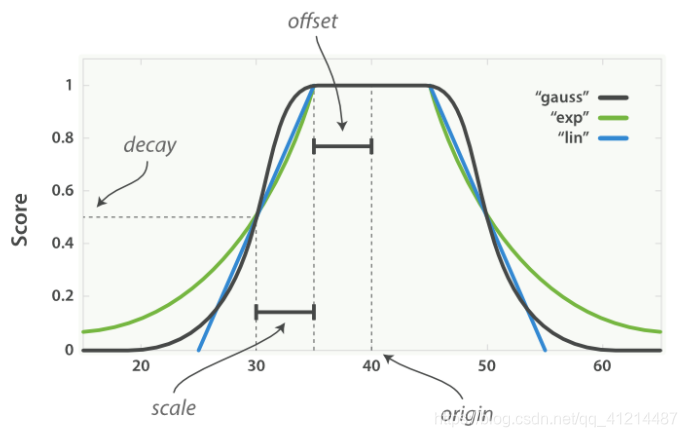
曲线解释(黑线):
offset:衰减的起始点,在该点时打分为1,实际应用中,例如offset为2km则在2km内高斯函数的打分情况都为1
origin:入参
decay:拐点打分值
scale:设置的衰减拐点值,例如设置scale为20km,则到20km时的打分为decay,大于20km之后则开始快速衰减分数。
查询dsl
, "functions": [{"gauss": {"location": {"origin": "30.25641125.122.15246253","scale": "8km","offset": "0", "decay": 0.5}}},{"field_value_factor": {"field": "score" ,"modifier": "log2p" }, "weight": 2}]
上述gauss设置的意思为当入参的经纬度经计算后如果距离为0,即在offset范围内,打分为1,如果距离为8km,分数为0.5,距离8km内分数衰减缓慢,8km外衰减迅速
相关度计算
影响相关度算分的参数:
1、TF(Term Frequency):词频,即单词在文档中出现的次数,词频越高,相关度越高
2、Document Frequency(DF):文档词频,即单词出现的文档数
3、IDF(Inverse Document Frequency):逆向文档词频,与文档词频相反,即1/DF。即单词出现的文档数越少,相关度越高(如果一个单词在文档集出现越少,算为越重要单词)
4、Field-length Norm:文档越短,相关度越高
"settings": {"similarity": {"my_bm25": { "type": "BM25","b": 0 }}}
在创建索引时自定义一个bm25相关度计算模型,bm25有有两个参数
1、b:默认值0.75,该值控制字段长度归一化,es底层Lucene 认为较短字段比较长字段重要性高,该参数控制长度归一化所起的作用,值越高作用越大。0完全禁用归一化
2、k1:这个参数控制着词频结果在词频饱和度中的上升速度。默认值为 1.2 。值越小饱和度变化越快,值越大饱和度变化越慢。
如果对查询的结果集感到并不满意,可以考虑以下几种方式来进行相关度的控制:
- boost参数调整索引或字段的权重
- 改变查询方式
1、bool查询
2、dis_max查询(单个最佳匹配查询)
3、function score查询
4、constant score查询(常量分值查询,一般嵌套filter使用,由于filter不进行算分,可以使用此模式指定一个固定分值)
5、boosting 查询(给不良词汇降分等)
- 对结果集进行rescore
- 更改相关度模型,使用bm25,修改k1和b的值