云智慧 AIOps 社区是由云智慧发起,针对运维业务场景,提供算法、算力、数据集整体的服务体系及智能运维业务场景的解决方案交流社区。该社区致力于传播 AIOps 技术,旨在与各行业客户、用户、研究者和开发者们共同解决智能运维行业技术难题,推动 AIOps 技术在企业中落地,建设健康共赢的AIOps 开发者生态。
区间关联(Interval Join)
Flink支持常规Join(Regular Join)和区间Join(Interval Join) 关联,本章节将会对比说明常规关联和区间关联的技术差异和各自的适用场景。
常规Join
常规Join为保证数据完整性和准确性,需要持续不断的读取两个Source数据源,且很容易导致数据状态的无限增长,适合用于离线和小数据量场景。
常规数据关联(Regular Join)与RDB数据库中使用的join类似,左右两张表通过外键关联进行数据合并。但在实时数据处理中,由于数据持续不断的推送,上一秒未关联上的数据,可能会在这一秒新推送数据中找到可关联的数据,此时便需要将所有历史数据都保存在Flink状态中,以应对随时推送来的新数据,因此导致Flink状态的无限制增大。此外,由于实时计算对结果的要求是实时的,所以输出的数据结果也是在不断的变化的。以上因素均会导致实时的常规Join使用场景有限,一般仅限于离线数据处理和小数据量场景。
SELECT *
FROM Orders
LEFT JOIN Product
ON Orders.product_id = Product.id
区间Join
区间Join将数据按照时间分割成区块儿,对超过窗口期的数据进行清理,仅保留需要处理的数据,任务相对轻量化,有利于提高计算效率。
比如电商的订单与支付,各大电商平台在下单操作后都有支付时间限制,超过支付时间后,订单会自动取消。换句话说,订单数据流和支付数据流只有在一定时间内才可能关联上,那么对于超过这个期限没有获取到支付数据的订单,便会得知此订单是不可能再支付了,也就没有必要再保留在Flink状态中了。基于以上场景需求,Flink推出了区间关联(Interval Join),区间关联写法特征就是在join 的on语句中或者where语句中存在数据时间段限定。
SELECT *
FROM Orders o, Shipments s
WHERE o.id = s.order_id
AND o.order_time BETWEEN s.ship_time - INTERVAL '4' HOUR AND s.ship_time
下图为区间关联示例,详细描述了区间关联的过期数据流程。两条线是两条数据流,下面是右流,上面是左流,区间关联的限定条件是左流的时间最小不小于右流数据减2分钟,最大为右流数据加1分钟,下图黄色区域,如果右流当前数据时间是2分,那左流最旧保存0分数据,最新能关联到3分数据,也就是0分到3分之间这部分黄色区域。同样,当上面的左流数据已经到3分的数据时,下面的右流能关联到的数据区间是2分到5分之间。这样的话依照下面右流的数据,可以对上面左流晚于窗口期的数据进行过期清理,而下面右流的数据也可以根据上面左流数据的时间进行过期处理,最终Flink状态里只保存着有限、少量的数据,既保证了数据关联的完整性又减少了内存占用,任务始终以轻量化状态运行,保持高效数据计算。
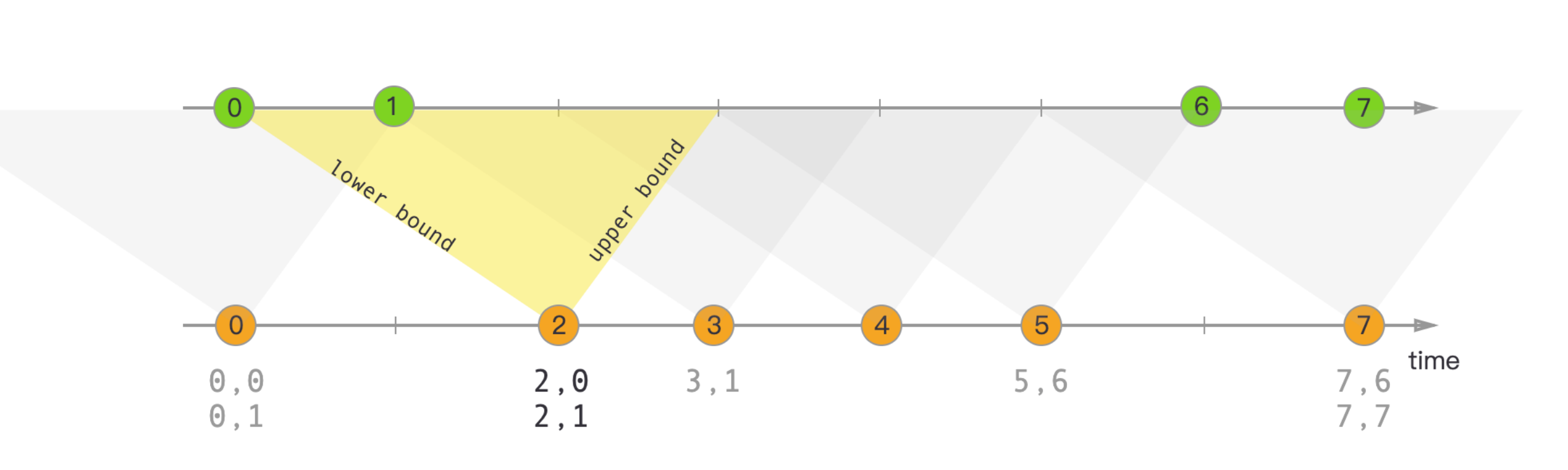
区间关联(Interval Join)包含以下谓词的Join语句,时间区间可以是秒、分钟、小时、天等。这里的BETWEEN是既包括下界又包括上界的,相当于大于等于且小于等于。Join语句支持Inner Join和Outer Join。
ltime = rtime
ltime >= rtime AND ltime < rtime + INTERVAL '10' MINUTE
ltime BETWEEN rtime - INTERVAL '10' SECOND AND rtime + INTERVAL '5' SECOND
维表关联(Temporal Join)
维表关联应用于传统数据处理中为应对名称修改问题等场景,操作数据中往往仅存储id数据,展示时通过id关联名称以获取到最新数据。而在实时数据处理领域,随着数字化进程的推进以及越来越多的终端用户,实时数据流往往可达到每天以亿计算的数据量级,因此对实时维表关联带来了不小的技术挑战。
当前Flink提供基于Hbase和MySQL的维表关联解决方案,MySQL以其完善的数据类型和数据查询语句,在小数据量场景下可满足维表关联的诉求,但无法支持大数据量的实时查询;Hbase底层基于hdfs文件系统,在面对海量数据高并发查询的情况下,也不能做到很快速的结果响应。Flink也可以使用内存表做数据关联,可以提供非常快的关联查询,但内存表存在无法跨任务复用和内存占用问题,过大的维表往往会导致内存无限制增长甚至内存溢出。基于以上问题,云智慧开发出了基于Redis的Flink维表存算系统,Redis数据基于内存存储,可以做到数据的快入快出,并提供持久化能力,集群和代理又可以很大程度的提高Redis的扩展能力,可以承载较大的数据实时读写压力,我们将Redis加入Flink SQL生态,可以很方便的使用SQL进行数据写入和关联,是一个很好的维表解决方案。
维表关联在Flink中又叫做时态关联,在传统维表之上又引入了时间的概念,为的是解决维表数据随时间变化,数据重刷时需要取得旧的维表数据。 以银行的外汇兑换业务为例,汇率在实时的变动,想要复盘一天内的汇率兑换记录,就需要知道每笔交易发生时的汇率情况,根据互换货币种类加上兑换时间才能准确计算得出兑换金额。 维表关联的写法固定为红色部分,指定一个时间字段,然后关联维表中的数据。
SELECT *
FROM Orders AS o
JOIN Rates FOR SYSTEM_TIME AS OF o.order_time AS r
ON r.currency = o.currency
下方为Redis维表建表语句,语句里面必须标识一个或多个数据主键以做数据关联使用,主键数据会配合主键前缀和间隔符拼接组成存储在Redis中的Key,这样在做关联的时候就可以根据主数据提供的关联外键组合成Key,读取到对应数据。 普通字段以HASH的格式存储在Redis Key中,并可以设置数据的过期时间或者永不过期。
CREATE TABLE redis_dim (
rk1 INT,
rk2 STRING,
rf1 STRING,
rf2 DOUBLE,
PRIMARY KEY (rk1,rk2) NOT ENFORCED
) WITH (
'connector' = 'redis',
'mode' = 'single',
'redis.hosts' = '127.0.0.1:6379',
'key-prefix' = 'k_p',
'key-spacer' = '_',
'ttl-sec' = '86400'
)
窗口聚合计算
窗口是聚合处理无限数据流的核心,窗口将流数据分割成有限大小的数据区块,聚合计算逻辑在各数据区块上运行。
传统RDB数据库的数据聚合使用group by语句,对查询范围内的数据进行计数、加和或其它聚合运算,数据总是首先固定了一个范围,比如日常做全表的条目统计或者针对某个用户做消费总和的统计,都是有明确的一个数据范围。在实时数据处理场景下,我们往往需要看到最新的数据结果,数据源源不断的产生,最终的结果也在不断的变化。在实时计算中,结果的时效性也就是数据价值的所在,时间,也是实时计算的一个重要属性。比如我们希望看到上一分钟或者上一小时的数据结果,这其实已经给数据划分好了区块。Flink聚合充分利用了窗口的概念,时间窗口将源源不断的无限数据流分割成了一个个有限大小的数据区块,并以内存计算的速度,最快的完成提前设定好的逻辑运算,输出计算结果。
窗口聚合分类
- 全局窗口
全局窗口是flink窗口的一种特殊的模式,类似于传统RDB数据库。在统计已读取的所有数据时,这种模式下收到数据后会立刻计算得出结果,同时也会产生一个回撤数据,表示撤销之前的计算结果,然后输出最新的计算结果。由于全局窗口导致状态数据的无限制增长,故一般流式处理不这么使用。此外,如果数据源是Kafka,kafka数据会过期,任务重启就无法读取到完整的数据了,因此,一般会应用于批处理或者小数据量数据统计。

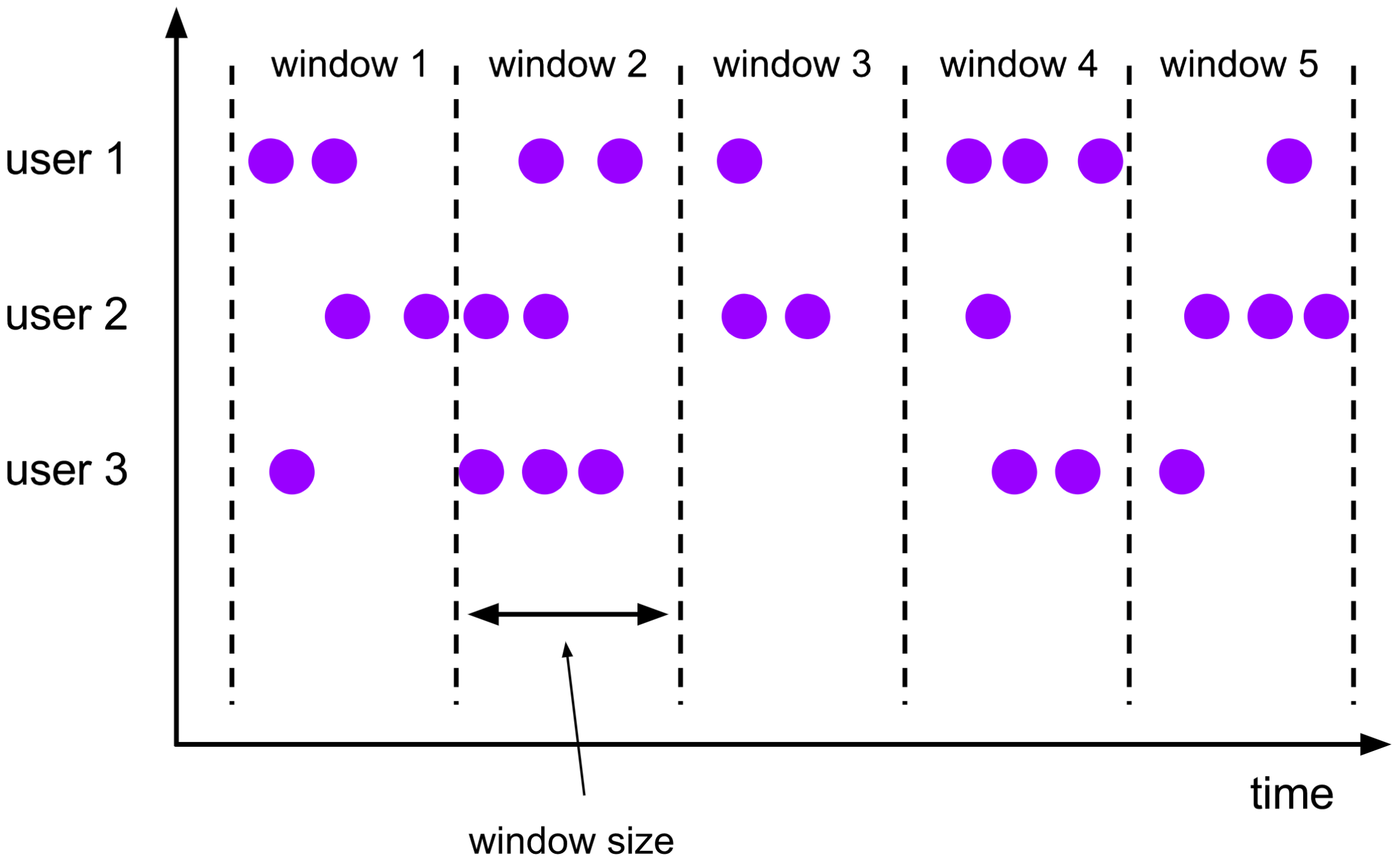
- Tumble 滚动窗口
滚动窗口是Flink窗口聚合最常用的一种。通过设置窗口大小,将数据均匀的分割成小块,各小块数据计算互不干涉,这种模式下不会产生回撤数据,统计结果会在窗口结束时计算得出。 需要注意的是窗口是左闭右开的,即如果一个数据刚好在窗口线上,那么它将被统计到后面的窗口中。 此外,对于窗口的分布,如果我们设置的是1分钟的窗口,那么毫无疑问窗口将是从每分钟的0秒到59秒;如果我们把窗口大小设置为59秒呢,其实窗口是根据时间戳计算的.时间戳是计算机最早开始时约定的一个时间计算方式,从1970年1月1日的凌晨开始计算的秒数。
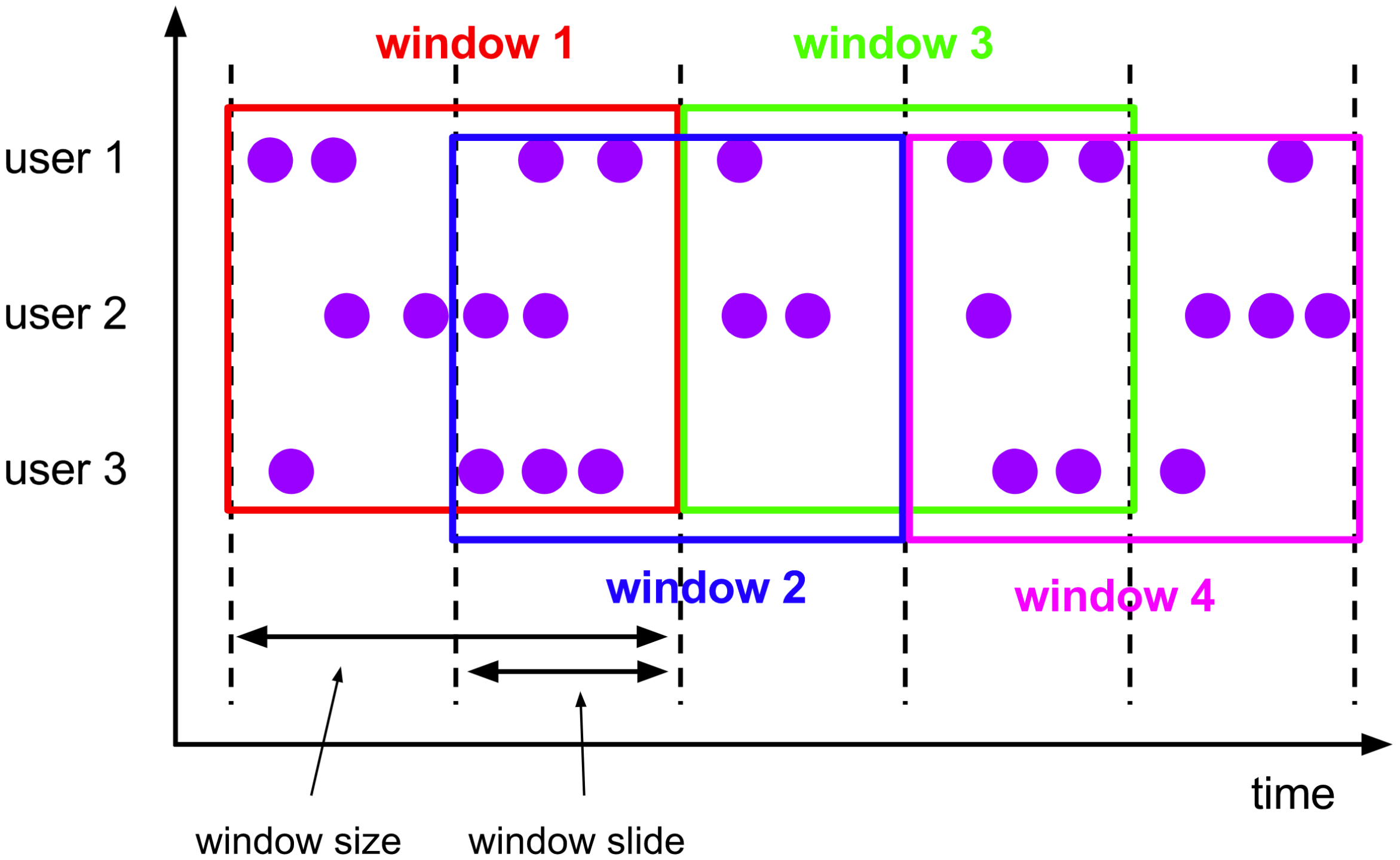
- Hop滑动窗口
滑动窗口由两个时间概念组成,一个是窗口大小,一个是滑动步长。举个例子,比如我们需要每分钟看一下最近30分钟内的统计数据,现在是31分,那我们需要看到0到30分的数据;到了32分,我们需要看1分到31分这半个小时的数据,这就是滑动窗口。 滑动窗口每次根据步长进行向前滑动,但统计的数据是窗口长度内的数据。
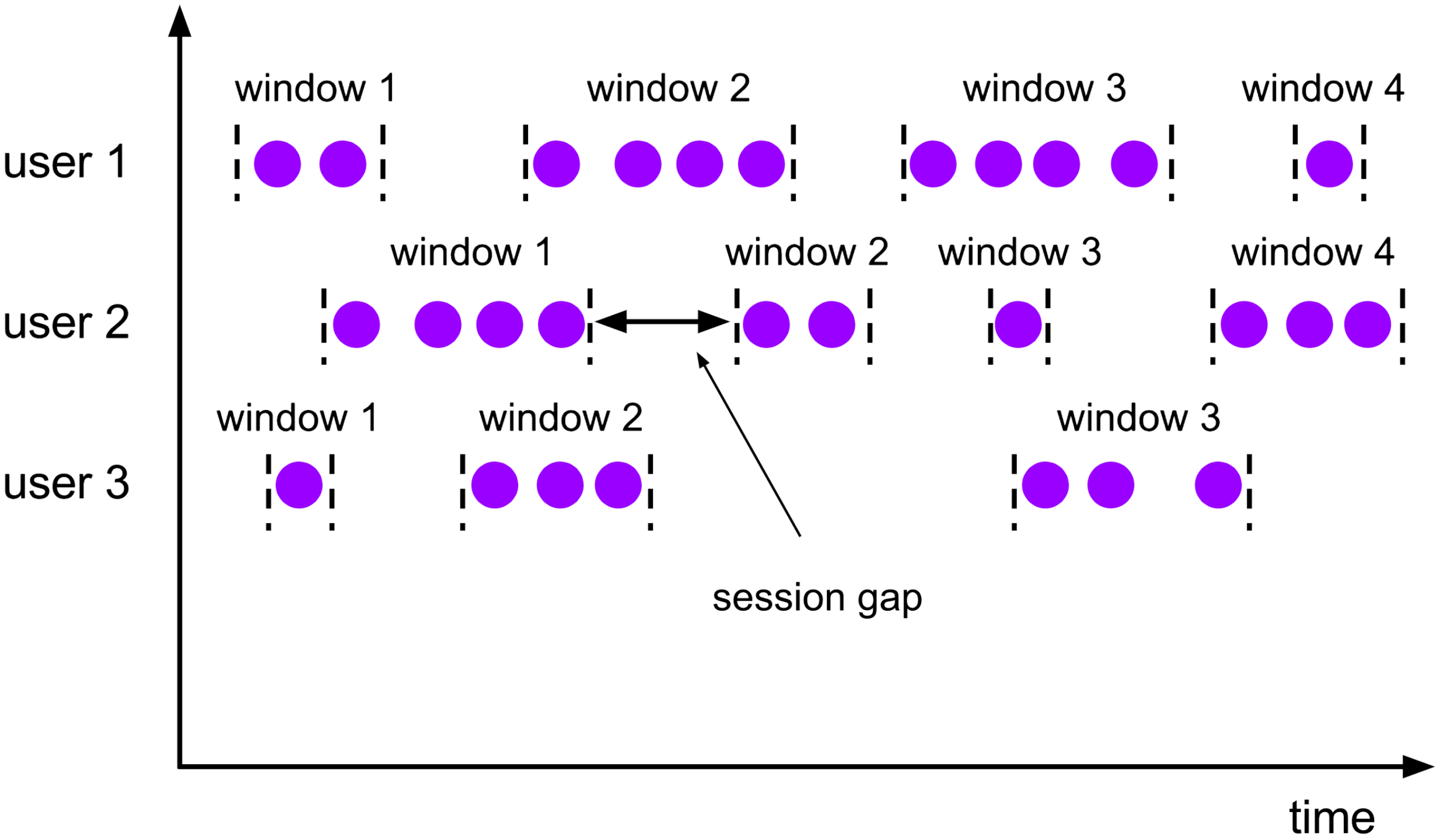
- Session窗口
当登录网站或app时,操作记录总是在一段时间内,退出app后就没有数据了,这时候当我们需要分析用户在登录app期间的行为时,就可以用到session窗口。session窗口设定了一个最大空闲时长,超过这个时长即可认为用户已退出app,这个时候开始进行用户全程操作计算,这个一般使用的不多。
水位线 (WaterMark)
窗口计算中最重要的一项数据是时间,数据发送的延迟和无序会导致窗口数据的缺失和统计结果的错误,水位线是容许数据延迟的技术解决方案。
在上述讲到的数据关联和数据聚合中,如果上游有一条数据推送的晚了,超过了我们设定的时间窗口期,是不是就无法统计到了。Kafka中的数据是无序的,很容易造成时间靠后的数据会比靠前的数据早消费到,这确实会导致窗口关闭后还有一定量的数据未处理。为解决这个问题,Flink引入了WaterMark概念,WaterMark直译是水印,但是翻译成水位线是更贴切的,水位线是Flink用来标识数据可以延迟的最大时间。比如水位线设置的是5分钟,最新的数据时间是1点10分,Flink依然接受1点5分的数据。水位线的引入也导致了窗口计算的延迟,窗口的关闭时间是窗口结束时间加上水位线时间。
批处理
Flink也可应用于批处理,常见的数据迁移 + 数据同步的组合,是最基本、最有效的一种数据集成方式 。
- 数据同步
以增量的方式周期性同步数据如:将mysql中的业务数据按照update_time每分钟同步一次到clickhouse
- 数据迁移
多个数据源之间的数据迁移 比如:mysql数据全表迁移到clickhouse
数据处理
周期性运行sql进行数据处理作业是数仓领域的基本方式 在数据仓库各层之间的sql可以是join类型的sql,group类型的sql,topN类型的sql。
- ODS DIM DWD DWS ADS 等分层数据的生产
- 按照T+1的方式将ODS层数据处理为 DWD或DWS 层数据
- 按照T+1的方式生成ADS层数据,供上层应用使用
Cloudwise flink jdbc Connector
我们在官方jdbc连接器的基础之上新增了以下特性,扩展了数据处理能力:
- 扩展了对clickhouse的支持,可以按需扩展更多的jdbc数据源
- 支持极限下推,可以将过滤条件下推到外部存储,只读取需要的数据,降低外部存储的io压力,同时缩短flink作业时间
- 支持读取分布式表,轮询写入本地表,以最优的读写方式契合clickhouse的读写特性
写在最后
近年来,在AIOps领域快速发展的背景下,IT工具、平台能力、解决方案、AI场景及可用数据集的迫切需求在各行业迸发。基于此,云智慧在2021年8月发布了AIOps社区, 旨在树起一面开源旗帜,为各行业客户、用户、研究者和开发者们构建活跃的用户及开发者社区,共同贡献及解决行业难题、促进该领域技术发展。
社区先后 开源 了数据可视化编排平台-FlyFish、运维管理平台 OMP 、云服务管理平台-摩尔平台、 Hours 算法等产品。
可视化编排平台-FlyFish:
项目介绍:https://www.cloudwise.ai/flyFish.html
Github地址: https://github.com/CloudWise-OpenSource/FlyFish
Gitee地址: https://gitee.com/CloudWise/fly-fish
行业案例:https://www.bilibili.com/video/BV1z44y1n77Y/
部分大屏案例: