1. 什么是TokuDB?
TokuDB 是一个支持事务的“新”引擎,有着出色的数据压缩功能,由美国 TokuTek 公司(现在已经被 Percona 公司收购)研发。拥有出色的数据压缩功能,如果您的数据写多读少,而且数据量比较大,强烈建议您使用TokuDB,以节省空间成本,并大幅度降低存储使用量和IOPS开销,不过相应的会增加 CPU 的压力。
1.1 TokuDB的特性
- 高压缩比,高写入性能
- 在线创建索引和字段
- 支持事务
- 支持主从同步
2. TokuDB安装步骤
2.1 准备两台mysql数据库
在之前的博客中单独安装过percona数据库,我们在这篇博客中不再重新安装数据库。安装Percona数据库教程链接在本篇博客中的数据归档也是主从复制的方式,所以准备好两台mysql服务器节点。
2.2 安装jemalloc库
yum install -y jemalloc
2.3 修改my.cnf
vi /etc/my.cnf
修改my.cnf文件添加以下内容
[mysqld_safe]
malloc-lib=/usr/lib64/libjemalloc.so.1
修改完之后重新启动mysql
systemctl restart mysqld
2.4 关闭 Transparent huge pages
为了保证TokuDB的写入性能,我们需要关闭linux系统的大页内存管理,默认情况下linux的大页内存管理是在系统启动时预先分配内存,系统运行时不再改变了。
echo never > /sys/kernel/mm/transparent_hugepage/enabled
echo never > /sys/kernel/mm/transparent_hugepage/defrag
2.5 安装tokudb
版本必须和Percona的版本一致,我们前面安装的是Percona5.7,所以此处也需要安装toku5.7,否则提示版本冲突。
yum install -y Percona-Server-tokudb-57.x86_64
3. TokuDB引擎启动
输入Mysql的root帐号密码,完成启动。
ps_tokudb_admin --enable -uroot -p
启动完成之后重启一下mysql
systemctl restart mysqld
重启之后再激活一次tokudb,重新执行一下命令
ps_tokudb_admin --enable -uroot -p
4. 查看TokuDB引擎是否安装成功
mysql -u root -p
进入mysql控制台,执行show engines;
show engines;

5. 使用TokuDB引擎
如果是sql语句建表,只需要在语句的结尾加上ENGINE = TokuDB就可以
CREATE TABLE student(.........
) ENGINE = TokuDB;
有些人习惯用navicat来创建表,这个对tokuDB引擎行不通的,通过navicat指定tokuDB引擎也不会好用
6. 归档库的双击热备
我们这篇博客选用两个Percona数据库节点组成Replication集群,这两个节点配置成双向同步,因为Replication集群的主从同步是单向的,如果配置成单向的主从同步,主库挂掉以后,我们可以像从库写入数据,但是主库恢复之后主库是不会像从库那同步数据的,所以两个节点的数据不一致,如果我们配置成双向同步,无论哪一个节点宕机了,在上线的时候他都会从其他的节点同步数据。这就可以保证每一个节点的数据是一致的。当然这个一致性是弱一致性,跟PXC集群的强一致性有本质区别的。
下边的图片是一个冷数据备份的数据库集群方案,但是我们由于资源有限,只搭建一台的Haproxy+2台的数据库节点,图中画蓝色线的模块。

7. 配置Replication集群
7.1 Replication集群同步原理
当我们在Master节点写入数据,Master会把这次操作会记录到binlog日志里边,Slave节点会有专门的线程去请求Master发送binlog日志,然后Slave节点上的线程会把收到的Master日志记录在本地realy_log日志文件中,slave节点通过执行realy_log日志来实现数据的同步,最后把执行过的操作写到本地的binlog日志里

通过图片我们能总结出Replication集群的数据同步是单向的,我们在Master上写入数据,在slave上可以同步到这些数据,但是反过来却不行,所以要实现双向同步,两个数据库节点互为主从关系才行

7.2 创建同步账户
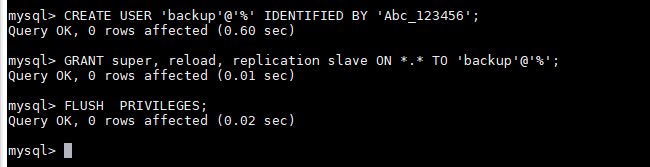
因为slave节点要从master节点同步数据,必须要登录Master节点,之前我们创建的admin账户和root账户的权限过大,由于我们只做同步数据,我们再给两个节点的数据库都创建上一个同步数据的账户
CREATE USER 'backup'@'%' IDENTIFIED BY 'Abc_123456';
GRANT super, reload, replication slave ON *.* TO 'backup'@'%';
FLUSH PRIVILEGES;
7.3 修改配置文件
由于mysql数据库默认没有开启binlog日志,我们需要设置一下开启binlog
vi /etc/my.cnf
两个节点的serverid需要不一样
server_id = 111
log_bin = mysql_bin
relay_log = relay_bin
server_id = 113
log_bin = mysql_bin
relay_log = relay_bin
修改完之后重启mysql
systemctl restart mysqld
7.4 配置主从同步
因为我们要配置双向同步,我们要配置两变主从同步
7.4.1 A节点为MasterB节点为Slave

我们在B节点的mysql上关闭主从同步的服务
stop slave;
然后再指定要同步的Master节点
change master to master_host="192.168.1.111",master_port=3306,master_user="backup",master_password="Abc_123456";
启动同步服务
start slave;
查看主从同步状态信息
show slave status;
Slave_IO_Running和Slave_SQL_RUNNING都是YES时配置成功

7.4.3 B节点为MasterA节点为Slave
因为是双向同步,接下里我们要以B节点为Master,A节点作为slave设置主从同步,我们需要在A节点上执行刚才的所有操作,具体步骤就不在下边描述

7.5 创建归档表
因为是双向同步,我们在哪一个节点创建归档表,另一个节点都会同步到数据
CREATE DATABASE test;
USE test;
CREATE TABLE t_purchase_201907 (id INT UNSIGNED PRIMARY KEY,purchase_price DECIMAL(10,2) NOT NULL,purchase_num INT UNSIGNED NOT NULL,purchase_sum DECIMAL (10,2) NOT NULL,purchase_buyer INT UNSIGNED NOT NULL,purchase_date TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP,company_id INT UNSIGNED NOT NULL,goods_id INT UNSIGNED NOT NULL,KEY idx_company_id(company_id),KEY idx_goods_id(goods_id)
)engine=TokuDB;
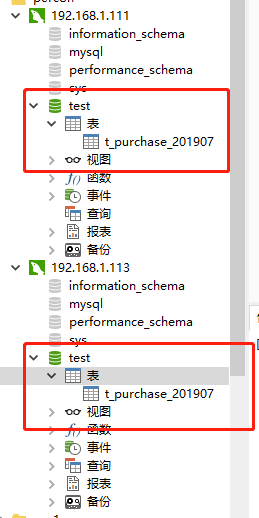

这样我们就创建好了两个mysql节点相互同步
7.6 搭建haproxy
在之前的博客中博主搭建过haproxy,在这篇文章就不再重复搭建,不会搭建的伙伴可以看博主往期博客,这篇博客只贴出haproxy的配置文件
globallog 127.0.0.1 local2chroot /var/lib/haproxypidfile /var/run/haproxy.pidmaxconn 4000user haproxygroup haproxydaemon# turn on stats unix socketstats socket /var/lib/haproxy/statsdefaultsmode httplog globaloption httplogoption dontlognulloption http-server-closeoption forwardfor except 127.0.0.0/8option redispatchretries 3timeout http-request 10stimeout queue 1mtimeout connect 10stimeout client 1mtimeout server 1mtimeout http-keep-alive 10stimeout check 10smaxconn 3000listen admin_statsbind 0.0.0.0:4001 #监控界面访问的ip和端口mode http #访问协议stats uri /dbs #URI相对地址stats realm Global\ statistics #统计报告格式stats auth admin:abc123456 #登录账号信息listen proxy-mysqlbind 0.0.0.0:3306mode tcpbalance roundrobinoption tcplog #日志格式server backup111 192.168.1.111:3306 check port 3306 weight 1 maxconn 2000server backup113 192.168.1.113:3306 check port 3306 weight 1 maxconn 2000
修改完haproxy.cfg文件启动haproxy
service haproxy start
我们登陆haproxy的监控画面,说明搭建成功

7.7 创建进货表
我们在以前搭建的haproxy+pxc三节点集群的数据库集群中创建进货表,注意这里是三节点的pxc集群,不是在上边创建的haproxy+2个节点的mysql,这个集群是在以前的博客中创建的,不懂的同学可以看往期博客。
我们在系统表中创建一个test数据库,创建一个进货表,注意这里创建进货表时没指定tokuDB引擎。这个进货表不是按照时间分表的,所以不用像上边创建的归档表一样表名称还要包含年份和月份
CREATE DATABASE test;
USE test;
CREATE TABLE t_purchase (id INT UNSIGNED PRIMARY KEY,purchase_price DECIMAL(10,2) NOT NULL,purchase_num INT UNSIGNED NOT NULL,purchase_sum DECIMAL (10,2) NOT NULL,purchase_buyer INT UNSIGNED NOT NULL,purchase_date TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP,company_id INT UNSIGNED NOT NULL,goods_id INT UNSIGNED NOT NULL,KEY idx_company_id(company_id),KEY idx_goods_id(goods_id))
7.8 准备测试数据
在haproxy+pxc三节点的mysql集群中创建归档数据,可以使用函数或者存储过程批量创建,创建方法自行百度。
我创建了140000条的数据

7.9 安装归档工具
Percona公司为我们提供了一套非常便捷的工具包Percona-Toolkit,这个工具包包含了用于数据归档的pt-archiver,用这个归档工具我们可以轻松的完成数据的归档。
pt-archiver的用途
- 导出线上数据,到线下数据作处理
- 清理过期数据,并把数据归档到本地归档表中,或者远端归档服务器
7.9.1 安装依赖包
yum install perl-DBIyum install perl-DBD-MySQLyum install perl-Time-HiResyum install perl-IO-Socket-SSL
7.9.2 安装percona toolkit的包
yum install http://www.percona.com/downloads/percona-release/redhat/0.1-4/percona-release-0.1-4.noarch.rpm
7.9.3 查看可以安装的包
yum list | grep percona-toolkit

7.9.4 安装percona-toolkit工具包
yum install percona-toolkit
查看pt-archiver的版本,如下图所示,安装成功
pt-archiver --version

7.10 归档数据
pt-archiver
--source h=192.168.1.27,P=3306,u=admin,p=Abc_123456,D=test,t=t_purchase
--dest h=192.168.1.114,P=3306,u=admin,p=Abc_123456,D=test,t=t_purchase_201907
--no-check-charset --where 'purchase_date<"2019-08-01 0:0:0"'
--progress 5000 --bulk-delete --bulk-insert --limit=10000 --statistics
–source h=192.168.1.27, P=3306, u=admin, p=Abc_123456, D=test, t=t_purchase 代表的是取哪个服务器的哪个数据库的哪张表的
–dest h=192.168.1.114, P=3306, u=admin, p=Abc_123456, D=test, t=t_purchase_201907 代表的是归档库的连接信息
–no-check-charset 代表的是归档过程中我们不检查数据的字符集
–where ‘purchase_date<“2019-08-01 0:0:0”’ 归档数据的判断条件
–progress 5000 每归档5000条数据往控制台打印一下状态信息
–bulk-delete 批量的删除归档数据
–bulk-insert 批量的新增归档数据
–limit=10000 批量一万条数据进行一次归档
–statistics 打印归档的统计信息

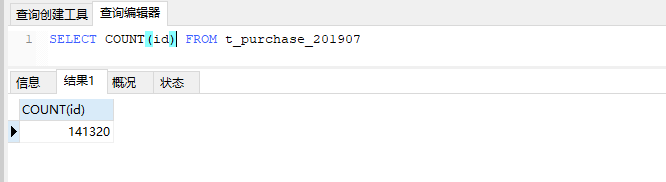
7.11 验证归档数据
我们先查看以下192.168.1.27这个节点是不是已经没有了数据
我们看到这个节点已经没有了数据

再看看192.168.1.114这个节点,数据归档成功
7.12 总结
使用TokuDB引擎保存归档数据,拥有高速写入特性
使用双机热备方案搭建归档库,具备高可用性
使用pt-archiver执行归档数据,简便易行