目前深度学习已经越来越受到重视,深度学习的框架也是层出不穷,例如谷歌的TensorFlow,它是基于Python进行开发的,对于许多对Python不够了解的程序员来说用起来可能没有那么的方便,这里说一下一个基于Java的深度学习框架——DL4J。本博客主要介绍在代码层面基于DL4J模型实现训练Word2Vec,一起来看一下吧~
【代码】
package com.xzw.dl4j;import java.io.File;
import java.io.IOException;
import java.util.Collection;
import org.deeplearning4j.models.embeddings.loader.WordVectorSerializer;
import org.deeplearning4j.models.word2vec.Word2Vec;
import org.deeplearning4j.text.sentenceiterator.LineSentenceIterator;
import org.deeplearning4j.text.sentenceiterator.SentenceIterator;
import org.deeplearning4j.text.sentenceiterator.SentencePreProcessor;
import org.deeplearning4j.text.tokenization.tokenizer.TokenPreProcess;
import org.deeplearning4j.text.tokenization.tokenizer.preprocessor.EndingPreProcessor;
import org.deeplearning4j.text.tokenization.tokenizerfactory.DefaultTokenizerFactory;
import org.deeplearning4j.text.tokenization.tokenizerfactory.TokenizerFactory;
/*** * @author xzw**/
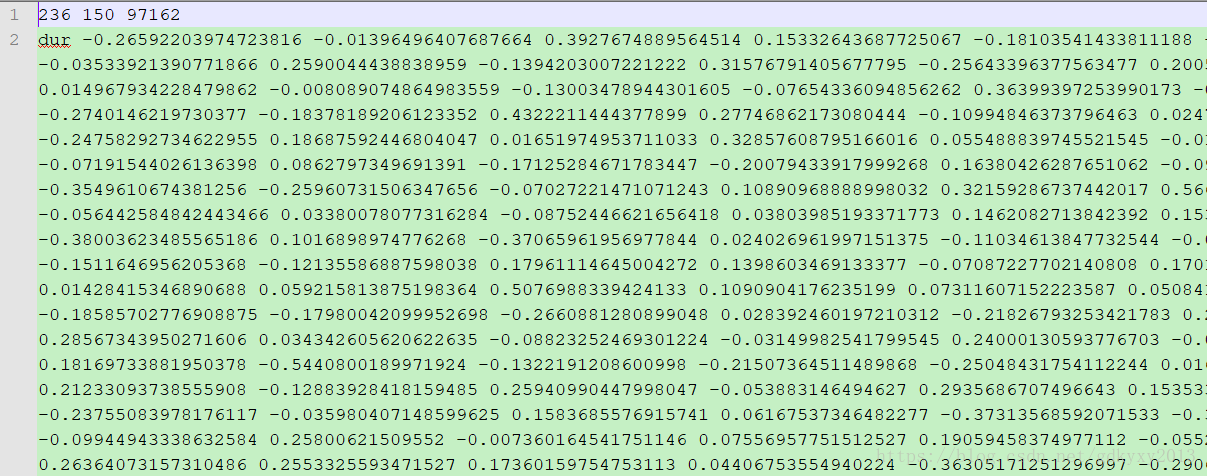
public class Word2VecTest {@SuppressWarnings("deprecation")public static void main(String[] args) throws IOException {System.out.println("Load data...");File file = new File("C://Users//Machenike//Desktop//zzz//raw_sentences.txt");SentenceIterator iterator = new LineSentenceIterator(file);iterator.setPreProcessor(new SentencePreProcessor() {private static final long serialVersionUID = 1L;@Overridepublic String preProcess(String sentence) {// TODO Auto-generated method stubreturn sentence.toLowerCase();}});System.out.println("Tokenize data...");final EndingPreProcessor preProcessor = new EndingPreProcessor();TokenizerFactory tokenizer = new DefaultTokenizerFactory();tokenizer.setTokenPreProcessor(new TokenPreProcess() {@Overridepublic String preProcess(String token) {// TODO Auto-generated method stubtoken = token.toLowerCase();String base = preProcessor.preProcess(token);base = base.replaceAll("\\d", "d");return base;}});System.out.println("Build model...");int batchSize = 1000;int iterations = 3;int layerSize = 150;Word2Vec vec = new Word2Vec.Builder().batchSize(batchSize).minWordFrequency(5).useAdaGrad(false).layerSize(layerSize).iterations(iterations).learningRate(0.025).minLearningRate(1e-3).negativeSample(10).iterate(iterator).tokenizerFactory(tokenizer).build();//trainSystem.out.println("Learning...");vec.fit();//model saveSystem.out.println("Save model...");WordVectorSerializer.writeWordVectors(vec, "C://Users//Machenike//Desktop//zzz//words.txt");System.out.println("Evaluate model...");String word1 = "people";String word2 = "money";double similarity = vec.similarity(word1, word2);System.out.println(String.format("The similarity between %s and %s is %f", word1, word2, similarity));String word = "day";int ranking = 10;Collection<String> similarTop10 = vec.wordsNearest(word, ranking);System.out.println(String.format("Similar word to %s is %s", word, similarTop10));}}【用到的数据集】

【保存的Word2Vec模型】
【运行结果】

![[Deeplearning4j应用教程03]_快速完成在自己的Maven项目中使用DL4J](https://img-blog.csdnimg.cn/20210107095557638.jpeg?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl8zMzk4MDQ4NA==,size_16,color_FFFFFF,t_70)
![[Deeplearning4j应用教程00]_DL4J技术介绍](https://img-blog.csdnimg.cn/2020122114355010.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl8zMzk4MDQ4NA==,size_16,color_FFFFFF,t_70)
![[Deeplearning4j应用教程04]_基于DL4J的神经网络实现](https://img-blog.csdnimg.cn/20210111154905659.jpg?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl8zMzk4MDQ4NA==,size_16,color_FFFFFF,t_70)





![[Deeplearning4j应用教程02]_DL4J环境搭建教程-Windows版](https://img-blog.csdnimg.cn/20210105162407912.jpeg?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl8zMzk4MDQ4NA==,size_16,color_FFFFFF,t_70)