文章首发于微信公众号《有三AI》
【DL4J速成】Deeplearning4j图像分类从模型自定义到测试
欢迎来到专栏《2小时玩转开源框架系列》,这是我们第九篇,前面已经说过了caffe,tensorflow,pytorch,mxnet,keras,paddlepaddle,cntk,chainer。
今天说Deeplearning4j(DL4J),本文所用到的数据,代码请参考我们官方git
https://github.com/longpeng2008/LongPeng_ML_Course
作者&编辑 | 胡郡郡 言有三
1 Deeplearning4j(DL4J)是什么
不同于深度学习广泛应用的语言Python,DL4J是为java和jvm编写的开源深度学习库,支持各种深度学习模型。
DL4J最重要的特点是支持分布式,可以在Spark和Hadoop上运行,支持分布式CPU和GPU运行。DL4J是为商业环境,而非研究所设计的,因此更加贴近某些生产环境。
2 DL4J训练准备
2.1 DL4J安装
系统要求:
-
Java:开发者版7或更新版本(仅支持64位版本)
-
Apache Maven:Maven是针对Java的项目管理工具,兼容IntelliJ等IDE,可以让我们轻松安装DL4J项目库
-
IntelliJ IDEA (建议)或 Eclipse
-
Git
官方提供了很多DL4J的示例。可以通过以下命令下载安装:
$ git clone https://github.com/deeplearning4j/dl4j-examples.git
$ cd dl4j-examples/$ mvn clean installmvn clean install 目的是为了安装所依赖的相关包。
然后将下载的dl4j-examples导入到IntelliJ IDEA中,点击自己想要试的例子进行运行。
2.2 数据准备
DL4J有自己的特殊的数据结构DataVec,所有的输入数据在进入神经网络之前要先经过向量化。向量化后的结果就是一个行数不限的单列矩阵。
熟悉Hadoop/MapReduce的朋友肯定知道它的输入用InputFormat来确定具体的InputSplit和RecordReader。DataVec也有自己FileSplit和RecordReader,并且对于不同的数据类型(文本、CSV、音频、图像、视频等),有不同的RecordReader,下面是一个图像的例子。
int height = 48; // 输入图像高度
int width = 48; // 输入图像宽度
int channels = 3; // 输入图像通道数
int outputNum = 2; // 2分类
int batchSize = 64;
int nEpochs = 100;
int seed = 1234;
Random randNumGen = new Random(seed);// 训练数据的向量化
File trainData = new File(inputDataDir + "/train");
FileSplit trainSplit = new FileSplit(trainData, NativeImageLoader.ALLOWED_FORMATS, randNumGen);
ParentPathLabelGenerator labelMaker = new ParentPathLabelGenerator(); // parent path as the image label
ImageRecordReader trainRR = new ImageRecordReader(height, width, channels, labelMaker);
trainRR.initialize(trainSplit);
DataSetIterator trainIter = new RecordReaderDataSetIterator(trainRR, batchSize, 1, outputNum);// 将像素从0-255缩放到0-1 (用min-max的方式进行缩放)
DataNormalization scaler = new ImagePreProcessingScaler(0, 1);
scaler.fit(trainIter);
trainIter.setPreProcessor(scaler);// 测试数据的向量化
File testData = new File(inputDataDir + "/test");
FileSplit testSplit = new FileSplit(testData, NativeImageLoader.ALLOWED_FORMATS, randNumGen);
ImageRecordReader testRR = new ImageRecordReader(height, width, channels, labelMaker);
testRR.initialize(testSplit);
DataSetIterator testIter = new RecordReaderDataSetIterator(testRR, batchSize, 1, outputNum);
testIter.setPreProcessor(scaler); // same normalization for better results数据准备的过程分成以下几个步骤:
1)通过FileSplit处理输入文件,FileSplit决定了文件的分布式的分发和处理。
2)ParentPathLabelGenerator通过父目录来直接生成标签,这个生成标签的接口非常方便,比如说如果是二分类,我们先将两个父目录设定为0和1,然后再分别在里面放置对应的图像就行。
3)通过ImageRecordReader读入输入图像。RecordReader是DataVec中的一个类,ImageRecordReader是RecordReader中的一个子类,这样就可以将输入图像转成向量化的带有索引的数据。
4)生成DataSetIterator,实现了对输入数据集的迭代。
2.3 网络定义
在Deeplearning4j中,添加一个层的方式是通过NeuralNetConfiguration.Builder()调用layer,指定其在所有层中的输入及输出节点数nIn和nOut,激活方式activation,层的类型如ConvolutionLayer等。
// 设置网络层及超参数
MultiLayerConfiguration conf = new NeuralNetConfiguration.Builder().seed(seed).l2(0.0005).updater(new Adam(0.0001)).weightInit(WeightInit.XAVIER).list().layer(0, new ConvolutionLayer.Builder(3, 3).nIn(channels).stride(2, 2).nOut(12).activation(Activation.RELU).weightInit(WeightInit.XAVIER).build()).layer(1, new BatchNormalization.Builder().nIn(12).nOut(12).build()).layer(2, new ConvolutionLayer.Builder(3, 3).nIn(12).stride(2, 2).nOut(24).activation(Activation.RELU).weightInit(WeightInit.XAVIER).build()).layer(3, new BatchNormalization.Builder().nIn(24).nOut(24).build()).layer(4, new ConvolutionLayer.Builder(3, 3).nIn(24).stride(2, 2).nOut(48).activation(Activation.RELU).weightInit(WeightInit.XAVIER).build()).layer(5, new BatchNormalization.Builder().nIn(48).nOut(48).build()).layer(6, new DenseLayer.Builder().activation(Activation.RELU).nOut(128).build()).layer(7, new OutputLayer.Builder(LossFunctions.LossFunction.NEGATIVELOGLIKELIHOOD).nOut(outputNum).activation(Activation.SOFTMAX).build()).setInputType(InputType.convolutionalFlat(48, 48, 3)) // InputType.convolutional for normal image.backprop(true).pretrain(false).build();这里的网络结构和之前的caffe、tensorflow、pytorch等框架采用的网络结构是一样的,都是一个3层的神经网络。
3 模型训练
数据准备好了,网络也建好了,接下来就可以训练了。
// 新建一个多层网络模型MultiLayerNetwork net = new MultiLayerNetwork(conf);
net.init();// 训练的过程中同时进行评估
for (int i = 0; i < nEpochs; i++) {net.fit(trainIter);log.info("Completed epoch " + i);Evaluation trainEval = net.evaluate(trainIter);Evaluation eval = net.evaluate(testIter);log.info("train: " + trainEval.precision());log.info("val: " + eval.precision());trainIter.reset();testIter.reset();
}//保存模型ModelSerializer.writeModel(net, new File(modelDir + "/mouth-model.zip"), true);训练的过程非常简单直观,直接通过net.fit()加载trainIter就可以,其中trainIter在数据准备中已经定义好了。
通过net.evaluate(trainIter)和net.evaluate(testIter)的方式来评估训练和测试的表现,这里我们将每个epoch的准确率打印出来。
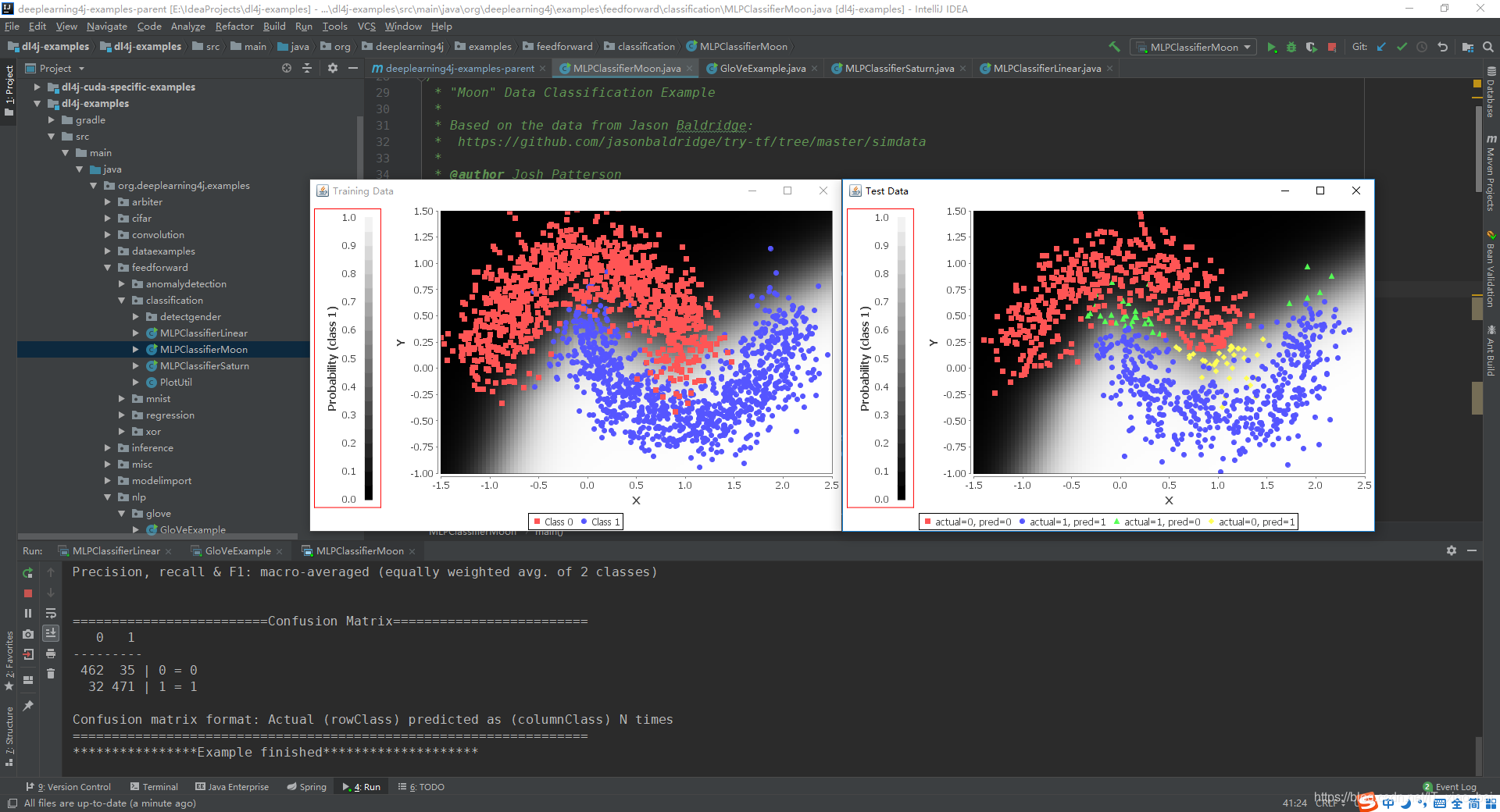
4 可视化
DL4J提供的用户界面可以在浏览器中看到实时的训练过程。
第一步:
将用户界面依赖项添加到pom文件中:
<dependency><groupId>org.deeplearning4j</groupId><artifactId>deeplearning4j-ui_2.10</artifactId><version>${dl4j.version}</version></dependency>第二步:
在项目中启动用户界面
//初始化用户界面后端,获取一个UI实例
UIServer uiServer = UIServer.getInstance();
//设置网络信息(随时间变化的梯度、分值等)的存储位置。这里将其存储于内存。
StatsStorage statsStorage = new InMemoryStatsStorage();
//将StatsStorage实例连接至用户界面,让StatsStorage的内容能够被可视化
uiServer.attach(statsStorage);
//添加StatsListener来在网络定型时收集这些信息
net.setListeners(new StatsListener(statsStorage));首先我们初始化一个用户界面后端,设置网络信息的存储位置。
这里将其存储于内存,也可以放入文件中,通过new FileStatsStorage(File)的方式实现。
再将StatsStorage实例连接至用户界面,让StatsStorage的内容能够被可视化。
最后添加StatsListener监听,在网络定型时收集这些信息。
默认的浏览器地址是:http://localhost:9000/train/overview
下面可视化一下损失函数值随迭代次数的变化曲线

模型页面中可以直观感受我们建立的模型

看一下最后的训练集和测试集的准确率

有一些过拟合,主要原因还是数据太少。
以上就是我们用自己的数据在DL4J框架上实践的内容,完整代码可以参考官方git。
总结
本文讲解了如何使用DL4J深度学习框架完成一个分类任务,虽然这个框架不是很热门,但是它是唯一集成java和大数据平台的,您在用吗?如果您在用,可以联系我们一起交流下!另外,还有想让我们介绍的框架吗?欢迎留言。
转载文章请后台联系
侵权必究
本系列完整文章:
第一篇:【caffe速成】caffe图像分类从模型自定义到测试
第二篇:【tensorflow速成】Tensorflow图像分类从模型自定义到测试
第三篇:【pytorch速成】Pytorch图像分类从模型自定义到测试
第四篇:【paddlepaddle速成】paddlepaddle图像分类从模型自定义到测试
第五篇:【Keras速成】Keras图像分类从模型自定义到测试
第六篇:【mxnet速成】mxnet图像分类从模型自定义到测试
第七篇:【cntk速成】cntk图像分类从模型自定义到测试
第八篇:【chainer速成】chainer图像分类从模型自定义到测试
第九篇:【DL4J速成】Deeplearning4j图像分类从模型自定义到测试
第十篇:【MatConvnet速成】MatConvnet图像分类从模型自定义到测试
第十一篇:【Lasagne速成】Lasagne/Theano图像分类从模型自定义到测试
第十二篇:【darknet速成】Darknet图像分类从模型自定义到测试
感谢各位看官的耐心阅读,不足之处希望多多指教。后续内容将会不定期奉上,欢迎大家关注有三公众号 有三AI!




![感谢折磨你的人[三]](http://gl.paea.cn/upload/images/28811369810044.jpg)