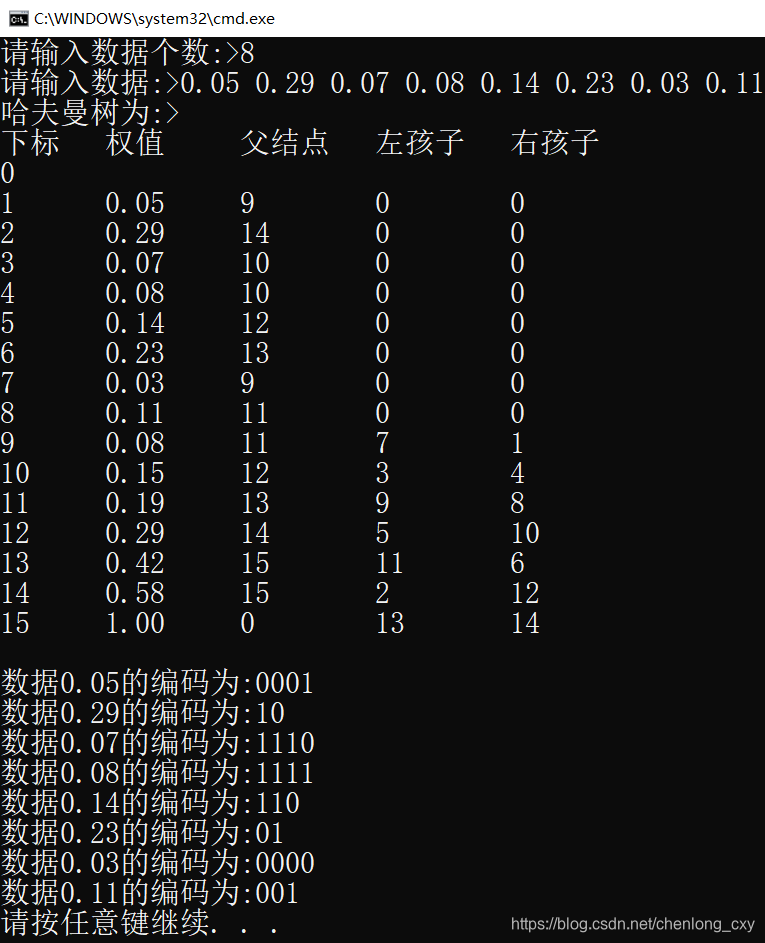
哈夫曼树的作用:在数据通信中,需要将传送的文字转换成二进制的字符串,用0,1码的不同排列来表示字符。例如,需传送的报文为“AFTER DATA EAR ARE ART AREA”,这里用到的字符集为“A,E,R,T,F,D”,各字母出现的次数为{8,4,5,3,1,1}。现要求为这些字母设计编码。要区别6个字母,最简单的二进制编码方式是等长编码,固定采用3位二进制,可分别用000、001、010、011、100、101对“A,E,R,T,F,D”进行编码发送,当对方接收报文时再按照三位一分进行译码。显然编码的长度取决报文中不同字符的个数。若报文中可能出现26个不同字符,则固定编码长度为5。然而,传送报文时总是希望总长度尽可能短。在实际应用中,各个字符的出现频度或使用次数是不相同的,如A、B、C的使用频率远远高于X、Y、Z,自然会想到设计编码时,让使用频率高的用短码,使用频率低的用长码,以优化整个报文编码。
哈夫曼树的结构
//创建一个树结点
typedef struct TreeNode{char data; //结点元素int weight; //树的权重int parent; //双亲结点int lchild; //左孩子int rchild; //右孩子
}TreeNode; //创建一个树(顺序存储)
typedef struct HFTree{TreeNode* data; int length; //树的长度
}HFTree; 初始化哈夫曼树
//初始化哈夫曼树
HFTree* initTree(int* weight,int length)
{HFTree* T=(HFTree*)malloc(sizeof(HFTree));T->data=(TreeNode*)malloc(sizeof(TreeNode)*(2*length-1));T->length=length;for(int i=0;i<length;i++){T->data[i].weight=weight[i];T->data[i].parent=0; //刚开始为空T->data[i].lchild=-1; //刚开始为空T->data[i].rchild=-1; //刚开始为空}for (int i = 0; i <length; i++){//scanf("%c ",&HT[i].data);char a = getchar();if(a == '\n') //遇到回车就结束break;elseT->data[i].data = a; //给每个结点赋予数据}return T;
}选择权重最小的函数(便于哈夫曼树的创建)
//选择权重最小的函数
int* selectMin(HFTree* T)
{int min=10000;int secondmin=100000;int minIndex,secondminIndex; //便于最小的两个权值无法在进行对比//找出最小的权值for(int i=0;i<T->length;i++) {if(T->data[i].parent==0){if(T->data[i].weight<min){min=T->data[i].weight;minIndex=i; //便于后面求出第二小的权值}}}//求出第二小的权值for(int i=0;i<T->length;i++){if(T->data[i].parent==0&&i!=minIndex){if(T->data[i].weight<secondmin){secondmin=T->data[i].weight;secondminIndex=i;}}}int* res=(int*)malloc(sizeof(int)*2); //放回两个值要用指针;res[0]=minIndex;res[1]=secondminIndex;return res; //返回res指针
}创建哈夫曼树
//创建哈夫曼树
void createHFTree(HFTree* T)
{int* res;int min;int secondmin;int len=T->length*2-1; //总共有2n-1个结点for(int i=T->length;i<len;i++){res=selectMin(T);min=res[0];secondmin=res[1];T->data[i].weight=T->data[min].weight+T->data[secondmin].weight;//双亲结点权重等于左右孩子权重之和T->data[i].lchild=min;T->data[i].rchild=secondmin;T->data[min].parent=i;T->data[secondmin].parent=i;T->length++;T->data[i].parent=0;}
}哈夫曼树的编码
void createHuffmanCode(HFTree* T, huffmanCode& HC, int n)
{HC = (huffmanCode)malloc(sizeof(huffmanCode) * n + 1); /*申请len + 1个huffmanCode大小huffmanCode类型的临时空间因为下标是从一开始,所以我们要申请比结点多一个的结点,和哈夫曼树的结构对应,方便输出*/char* cd = (char*)malloc(sizeof(char) * n); //申请n个char大小char类型的临时空间,这个临时数组记录每次遍历出来的编码int start = 0,c = 0,f = 0; //start为cd数组记录下标,c初始为叶子结点下标,而后就是孩子结点的下标,f记录双亲结点的下标cd[n - 1] = '\0'; //这个就是给printf留着的,因为printf不会生成'\0',如果用puts就不用这句语句了for (int i = 0; i <n; i++) //只要叶子结点的编码{start = n - 1; //这句要赋值n的话,start--要写在判断后方c = i; //指向叶子结点f = T->data[c].parent; //指向双亲结点while (f != 0) //根结点没有双亲{start--;if (T->data[f].lchild == c) //是左孩子就是0,右孩子就为1cd[start] = '0';elsecd[start] = '1';c = f; f = T->data[c].parent; //向根结点接近}HC[i] = (char*)malloc(sizeof(char) * (n - start)); //给数组里的数组申请n - start个char大小的char*类型的临时空间strcpy(HC[i], &cd[start]); //cd里记录的编码给HC的第i个数组}free(cd); //释放临时空间
}哈夫曼树的解码
void HuffmanDecoding(HFTree* T,int n,char* pwd,int Len)
{//从根结点出发,是走0左子树,1走右子树,直到遇到叶子结点,然后再从根结点出发printf("Original:");int len=strlen(pwd); //获取用户输入编码的长度int i=0;int t=Len; //初始化为从根结点出发while(i<len){if(pwd[i]=='0') //是0,走左子树{t=T->data[t].lchild;i++;if(T->data[t].lchild==-1&&T->data[t].rchild==-1){printf("%c",T->data[t].data);t=Len; //重新从根结点出发}}if(pwd[i]=='1') //是1,走右子树{t=T->data[t].rchild;i++;if(T->data[t].lchild==-1&&T->data[t].rchild==-1){printf("%c",T->data[t].data);t=Len;}}}
}主函数
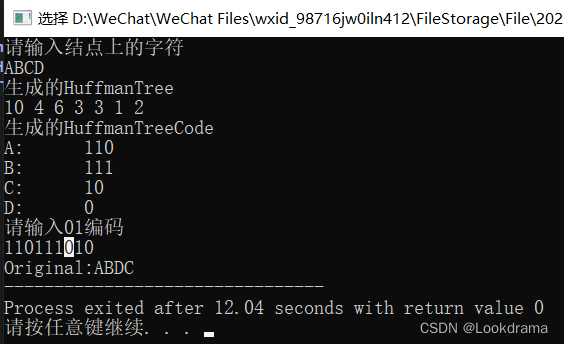
int main()
{int weight[]={1,2,3,4};int len=sizeof(weight)/sizeof(weight[0]); //求出权值数组长度;printf("请输入结点上的字符\n");HFTree* T=initTree(weight,len);huffmanCode HC;createHFTree(T);createHuffmanCode(T,HC,len);printf("生成的HuffmanTree\n");preOrder(T,T->length-1);printf("\n生成的HuffmanTreeCode\n");for(int i=0;i<len;i++){printf("%c:\t",T->data[i].data);printf("%s\n",HC[i]);}char s[MAXSIZE];printf("请输入01编码\n");scanf("%s",s);HuffmanDecoding(T,len,s,T->length-1);return 0;
}完整代码
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#define MAXSIZE 10000//创建一个树结点
typedef struct TreeNode{char data;int weight;int parent;int lchild;int rchild;
}TreeNode;//创建一个树(顺序存储)
typedef struct HFTree{TreeNode* data;int length;
}HFTree; typedef char** huffmanCode;
/*第一个*是代表它是指针变量,说明它是数组;
第二个*说明它是指针数组
代表这个char类型数组里每个元素都是*huffmanCode变量*///初始化哈夫曼树
HFTree* initTree(int* weight,int length)
{HFTree* T=(HFTree*)malloc(sizeof(HFTree));T->data=(TreeNode*)malloc(sizeof(TreeNode)*(2*length-1));T->length=length;for(int i=0;i<length;i++){T->data[i].weight=weight[i];T->data[i].parent=0; //刚开始为空T->data[i].lchild=-1; //刚开始为空T->data[i].rchild=-1; //刚开始为空}for (int i = 0; i <length; i++){//scanf("%c ",&HT[i].data);char a = getchar();if(a == '\n') //遇到回车就结束break;elseT->data[i].data = a; //给每个结点赋予数据}return T;
}//选择权重最小的函数
int* selectMin(HFTree* T)
{int min=10000;int secondmin=100000;int minIndex,secondminIndex; //便于最小的两个权值无法在进行对比//找出最小的权值for(int i=0;i<T->length;i++) {if(T->data[i].parent==0){if(T->data[i].weight<min){min=T->data[i].weight;minIndex=i; //便于后面求出第二小的权值}}}//求出第二小的权值for(int i=0;i<T->length;i++){if(T->data[i].parent==0&&i!=minIndex){if(T->data[i].weight<secondmin){secondmin=T->data[i].weight;secondminIndex=i;}}}int* res=(int*)malloc(sizeof(int)*2); //放回两个值要用指针;res[0]=minIndex;res[1]=secondminIndex;return res;
}//创建哈夫曼树
void createHFTree(HFTree* T)
{int* res;int min;int secondmin;int len=T->length*2-1; //总共有2n-1个结点for(int i=T->length;i<len;i++){res=selectMin(T);min=res[0];secondmin=res[1];T->data[i].weight=T->data[min].weight+T->data[secondmin].weight;//双亲结点权重等于左右孩子权重之和T->data[i].lchild=min;T->data[i].rchild=secondmin;T->data[min].parent=i;T->data[secondmin].parent=i;T->length++;T->data[i].parent=0;}
}//前序遍历哈夫曼树
void preOrder(HFTree* T,int index) //index为data数组中的索引
{if(index!=-1){printf("%d ",T->data[index].weight);preOrder(T,T->data[index].lchild);preOrder(T,T->data[index].rchild);}
}void createHuffmanCode(HFTree* T, huffmanCode& HC, int n)
{HC = (huffmanCode)malloc(sizeof(huffmanCode) * n + 1); /*申请len + 1个huffmanCode大小huffmanCode类型的临时空间因为下标是从一开始,所以我们要申请比结点多一个的结点,和哈夫曼树的结构对应,方便输出*/char* cd = (char*)malloc(sizeof(char) * n); //申请n个char大小char类型的临时空间,这个临时数组记录每次遍历出来的编码int start = 0,c = 0,f = 0; //start为cd数组记录下标,c初始为叶子结点下标,而后就是孩子结点的下标,f记录双亲结点的下标cd[n - 1] = '\0'; //这个就是给printf留着的,因为printf不会生成'\0',如果用puts就不用这句语句了for (int i = 0; i <n; i++) //只要叶子结点的编码{start = n - 1; //这句要赋值n的话,start--要写在判断后方c = i; //指向叶子结点f = T->data[c].parent; //指向双亲结点while (f != 0) //根结点没有双亲{start--;if (T->data[f].lchild == c) //是左孩子就是0,右孩子就为1cd[start] = '0';elsecd[start] = '1';c = f; f = T->data[c].parent; //向根结点接近}HC[i] = (char*)malloc(sizeof(char) * (n - start)); //给数组里的数组申请n - start个char大小的char*类型的临时空间strcpy(HC[i], &cd[start]); //cd里记录的编码给HC的第i个数组}free(cd); //释放临时空间
}void HuffmanDecoding(HFTree* T,int n,char* pwd,int Len)
{//从根结点出发,是走0左子树,1走右子树,直到遇到叶子结点,然后再从根结点出发printf("Original:");int len=strlen(pwd); //获取用户输入编码的长度int i=0;int t=Len; //初始化为从根结点出发while(i<len){if(pwd[i]=='0') //是0,走左子树{t=T->data[t].lchild;i++;if(T->data[t].lchild==-1&&T->data[t].rchild==-1){printf("%c",T->data[t].data);t=Len; //重新从根结点出发}}if(pwd[i]=='1') //是1,走右子树{t=T->data[t].rchild;i++;if(T->data[t].lchild==-1&&T->data[t].rchild==-1){printf("%c",T->data[t].data);t=Len;}}}
}
int main()
{int weight[]={1,2,3,4};int len=sizeof(weight)/sizeof(weight[0]); //求出权值数组长度;printf("请输入结点上的字符\n");HFTree* T=initTree(weight,len);huffmanCode HC;createHFTree(T);createHuffmanCode(T,HC,len);printf("生成的HuffmanTree\n");preOrder(T,T->length-1);printf("\n生成的HuffmanTreeCode\n");for(int i=0;i<len;i++){printf("%c:\t",T->data[i].data);printf("%s\n",HC[i]);}char s[MAXSIZE];printf("请输入01编码\n");scanf("%s",s);HuffmanDecoding(T,len,s,T->length-1);return 0;
}编译的结果