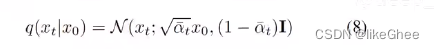从NAACL2021到ACL2022:两个信息抽取SOTA的比较分析(PURE vs PL-Marker)
- 1 前文
- 2 PURE 和 PL-Marker
- 3 PURE
- 3.1 相关工作
- 3.1.1结构化预测
- 3.1.2 多任务学习
- 3.2 问题的数学定义
- 3.3 模型
- 3.3.1 **NER模型( standard span-based模型)**
- 3.3.2 RE模型
- 3.3.3 Cross-sentence context(跨句上下文)
- 3.3.4 训练 & 推理
- 3.3.5 Efficient Batch Computations(高效的批计算)
- 3.4 实验结果及分析
- 4 PL-Marker
- 4.1 介绍
- 4.1.1 T-Concat
- 4.1.2 Solid Marker(固定标记)
- 4.1.3 Levitated Marker(悬浮标记)
- 4.2 出发点
- 4.3 相关工作
- 4.3.1 span pre-training
- 4.3.2 knowledge infusion
- 4.3.3 structural extension
- 4.4 方法
- 4.4.1 Levitated Marker背景知识
- 4.4.2 NER阶段
- 4.4.3 RE阶段
- 4.4.4 其他细节 —— Prompt Initialization for NER
- 4.5 实验结果与分析
- 4.5.1 结论 from NER实验
- 4.5.2 结论 from RE实验
- 5 PL-marker vs PURE
- 6 思考
- 7 Reference
文中部分内容摘自类似博客,既是个人阅读文献的笔记,也是资料收集整合的记录。如涉及版权问题,请告知本人,本人第一时间删除相关内容。
1 前文
笔者1月份闲暇时间逛 arxiv 时,发现一篇同时刷榜NER和RE两大任务的论文(PL-Marker),于是利用业余时间从论文(作者当时上传的论文并未更新到现在的version 5)到代码进行了仔细研读。PL-Marker是在PURE基础上的further work,又回到曾经粗略浏览的PURE论文,中间断了近两个月,直到4月份才完成研读工作,现将笔者研读期间的笔记以博客形式记录下来。
请各位看官轻喷,如有不当敬请指正。
请各位看官轻喷,如有不当敬请指正。
请各位看官轻喷,如有不当敬请指正。
2 PURE 和 PL-Marker
首先先简要介绍一下两篇文章:
-
第一篇来自普利斯顿大学 陈丹琦大佬(一作是Zexuan Zhong,陈丹琦是二作)在NAACL2021发表的《A Frustratingly Easy Approach for Joint Entity and Relation Extraction》(PDF | code ),原文中未对算法进行命名,但在源代码中用PURE来指代所提出的算法,本博客就沿用这个名称,致敬大佬。
-
第二篇来自清华大学Deming Ye在ACL2022发表的《Packed Levitated Marker for Entity and Relation Extraction 》(PDF | code ),该论文是在PURE基础上进行的改进工作,二者非常相似。
下面开始笔记内容。
3 PURE
3.1 相关工作
传统上,提取文本中实体之间的关系被研究为两个独立的任务:命名实体识别和关系抽取。作者将现有的端到端关系抽取(end-to-to realtion extraction)工作分为两大类:结构化预测和多任务学习。
3.1.1结构化预测
下列所有方法都需要解决一个全局优化问题,并在推理时使用波束搜索或强化学习进行联合解码。
| 归类 | 相关研究 |
|---|---|
| 提出了一个基于行动的系统,该系统识别新实体以及与实体的链接 | Incremental joint extraction of entity mentions and relations.(2014); End-to-end neural relation extraction with global optimization (2017) |
| 采用填表方法 | Joint extraction of entities and relations based on a novel tagging scheme.(2017); Modeling joint entity and relation extraction with table representation(2014); Going out on a limb: Joint extraction of entity mentions and relations without dependency trees.(2017,ACL) |
| 基于序列标记的方法 | Joint extraction of entities and relations based on a novel tagging scheme.(2017,ACL) |
| 出基于图的方法来联合预测实体和关系类型 | Joint type inference on entities and relations via graph convolutional networks.(2019,ACL); GraphRel: Modeling text as relational graphs for joint entity and relation extraction.(2019,ACL) |
| 将任务转化为多轮问答 | Entity-relation extraction as multi-turn question answering.(2019,ACL) |
3.1.2 多任务学习
| 归类 | 相关研究 |
|---|---|
| NER是列序标注模型,RE采用基于Tree的LSTM模型,两个模型共享一个LSTM层 | End-to-end relation extraction using LSTMs on sequences and tree structures(2016,ACL) |
| 跟上面差不多,只是RE模型是一个多标签头选择问题; | Adversarial training for multi-context joint entity and relation extraction(2018,EMNLP) |
3.2 问题的数学定义
| 数学表达 | 含义 |
|---|---|
| x i x_i xi | 句子中的单个token |
| X = { x 1 , ⋯ , x n } X=\{x_1, \cdots, x_n\} X={x1,⋯,xn} | 含有 n n n个token的句子 |
| s j s_j sj | 句子中的单个span |
| S = { s 1 , ⋯ , s m } S=\{s_1, \cdots, s_m\} S={s1,⋯,sm} | 句子 X X X中的所有span的集合( m m m个span) |
| START ( i ) \text{START}(i) START(i) | s i s_i si 的start index |
| END ( i ) \text{END}(i) END(i) | s i s_i si 的end index |
3.3 模型

PURE方法是一种pipeline方法,将命名实体和关系分类拆成两步执行:NER+RE,采取两个独立的预训练模型进行编码(不共享参数)。
3.3.1 NER模型( standard span-based模型)
standard span-based模型:即将句子中所有长度小于等于指定长度的span聚集成一个候选集,每个候选span根据模型生成一个对应的embedding表示,最后进行分类。
第一步:就是将文本送入PLM中获取每个token的上下文表征,然后将每个span的start token、end token的上下文表征以及span长度的embedding拼接在一起得到span的表征 h e ( s i ) \textbf{h}_e(s_i) he(si):
h e ( s i ) = [ X S T A R T ( i ) ; X E N D ( i ) ; ϕ ( s i ) ] \textbf{h}_e(s_i)=\left[X_{START(i)};X_{END(i)};\phi(s_i)\right] he(si)=[XSTART(i);XEND(i);ϕ(si)]
其中, ϕ ( s i ) \phi(s_i) ϕ(si)表示学习到的跨度宽度特征的嵌入(问题:如何学习得到的?要看代码)
第二步:将 h e ( s i ) \textbf{h}_e(s_i) he(si)送进两层前馈神经网络,经由RELU激活函数得到最终预测的entity type:
P e ( e ∣ s i ) = softmax ( W e ⋅ FFNN ( h e ( s i ) ) ) P_e(e|s_i)=\text{softmax}\left(\mathbf{W}_e \cdot \textbf{FFNN}(\textbf{h}_e(s_i))\right) Pe(e∣si)=softmax(We⋅FFNN(he(si)))
3.3.2 RE模型
本文的RE模型实际上是关系分类任务,就是将一对span,即subject s i s_i si 和 object s j s_j sj作为输入,预测两者之间的关系类别。
第一步:插入typed marker
作者发现,现有工作只捕捉到了每个单独实体的上下文信息,可能无法捕获特定一对span之间的依赖关系,于是作者做了个假设:共享不同跨度对的上下文表示可能不是最优的。举个栗子,在对“MORPA”和“PARSER”之间的关系进行分类时,Figure1的单词“is a”是很重要的,但是对于“MORPA”和“TEXT-TO-SPEECH”之间关系分类却并不重要。
因此,作者做出如下改进:在句子中的subject span和object span的前后插入typed marker(typed marker就是一对标记),以此来强化主语、谓语及实体类型特征,对模型来说也是对关键信息的一种“高亮显示”。这些typed marker表示为 < S : entity_type > , < / S : entity_type > , < O : entity_type > , < / O : entity_type > <S:\text{entity\_type}>, </S:\text{entity\_type}>, <O:\text{entity\_type}>, </O:\text{entity\_type}> <S:entity_type>,</S:entity_type>,<O:entity_type>,</O:entity_type>,如: < S : e i > , < / S : e i > , < O : e j > , < / O : e j > <S:e_i>, </S:e_i>, <O:e_j>, </O:e_j> <S:ei>,</S:ei>,<O:ej>,</O:ej>。插入typed marker后,句子 X X X变为了 X ^ \hat{X} X^:
X ^ = ⋯ , < S : e i > , x S T A R T ( i ) , ⋯ , x E N D ( i ) , < / S : e i > , ⋯ , < O : e j > , x S T A R T ( j ) , ⋯ , x E N D ( j ) , < / O : e j > , ⋯ \hat{X}=\cdots, <S:e_i>, x_{START(i)}, \cdots, x_{END(i)},</S:e_i>, \cdots, \\ <O:e_j>, x_{START(j)}, \cdots, x_{END(j)},</O:e_j>, \cdots X^=⋯,<S:ei>,xSTART(i),⋯,xEND(i),</S:ei>,⋯,<O:ej>,xSTART(j),⋯,xEND(j),</O:ej>,⋯
TIPS
- 相比于 < S > , < / S > <S>, </S> <S>,</S>类型的
entity marker,这种带实体类型的typed entity markers是前人没有研究探索过的方式,事实证明,这种在输入层就注入实体信息的方法对模型鉴别不同实体非常有用- 作者在实验中发现了很大的改进,这验证了之前的假设,即对一个句子中不同实体对之间的关系建模需要不同的上下文表征
- 知乎博客中指出,实体标记存在以下问题:(1)仅考虑开始和结束位置,没考虑类型;(2)仅仅通过增加损失函数的方法,添加实体类型信息,没考虑位置。
第二步:将句子 X ^ \hat{X} X^送入PLM得到输出 x ^ t \hat{\mathbf{x}}_t x^t 和实体候选span对( s i , s j s_i , s_j si,sj),得到实体对的嵌入表示:
h r ( s i , s j ) = [ x ^ S T A R T ^ ( i ) ; x ^ S T A R T ^ ( j ) ] \mathbf{h}_r(s_i, s_j)=[\hat{\mathbf{x}}_{\widehat{START}_(i)} ; \hat{\mathbf{x}}_{\widehat{START}_(j)}] hr(si,sj)=[x^START (i);x^START (j)]
注意:对于实体span pair ,RE模型只对每个实体的第一个token(其实是
typed marker)的词嵌入进行concatenate,来获取实体对的嵌入表示。
例如:
在句子MORPA is fully implemented parser for a text-to-speech system.中MORPA和parser是两个实体, 并且两个实体的类型都是Md, 所以设计出的两对标签分别是<S:Md> </S:Md>和<O:Md> </O:Md>, 实体可能是多个token组成, 加前后标签的目的其实是给出了实体的范围. 经过模型的fine-tune 训练后,<S:Md>的embedding代表实体MORPA, 而<O:Md>的embedding则表示另一个实体parser. 将<S:Md>和<O:Md>两个变量串接后进行softmax即可得到两个实体的关系类型
第三步:对实体对的嵌入表示进行SoftMax分类:
P r ( r ∣ s i , s j ) = softmax ( W r ⋅ h r ( s i , s j ) ) P_r(r|s_i,s_j)=\text{softmax}\left(\mathbf{W}_r \cdot \textbf{h}_r(s_i, s_j)\right) Pr(r∣si,sj)=softmax(Wr⋅hr(si,sj))
3.3.3 Cross-sentence context(跨句上下文)
为了更好的提取语义信息,作者在NER模型和RE模型上,从左上下文和右上下文中截取 ( W − n ) / 2 (W−n)/2 (W−n)/2个单词拼接到句子首尾,句子的长度就扩展为固定长度 W W W(代码中 W W W默认为 100 100 100),这使模型能够获得更多信息(尤其是上下文中出现指代名词时,如它他她等),有利于实体识别和关系分类。
跨句上下文的引入,对NER和RE两个任务都很重要,该tips也是本文的重点。
3.3.4 训练 & 推理
需注意的是,实体模型和关系模型采取的两个独立的预训练模型进行编码(不共享参数)。
在训练阶段,NER模型和RE模型的损失函数均为交叉熵损失函数:
L e = − ∑ s i ∈ S log P e ( e i ∗ ∣ s i ) L r = − ∑ s i , s j ∈ S G , s i ≠ s j log P r ( r i , j ∗ ∣ s i , s j ) \mathcal{L}_e=-\sum_{s_i \in S}\text{log}P_e(e_i^*|s_i)\\ \mathcal{L}_r=-\sum_{s_i,s_j \in S_G, s_i \neq s_j}\text{log}P_r(r_{i,j}^*|s_i,s_j) Le=−si∈S∑logPe(ei∗∣si)Lr=−si,sj∈SG,si=sj∑logPr(ri,j∗∣si,sj)
需注意的是,在RE模型训练过程中,只用gold entities作为实体标签,而不用NER模型预测的实体span。
在推理阶段,训练好的NER模型以公式 y e ( s i ) = a r g max e ∈ E ∪ { ϵ } P e ( e ∣ s i ) y_e(s_i)=arg \text{max}_{e\in \mathcal{E} \cup \{\epsilon\}}P_e(e|s_i) ye(si)=argmaxe∈E∪{ϵ}Pe(e∣si) 来预测实体 S p r e d = { s i : y e ( s i ) ≠ ϵ } S_{pred}=\{s_i:y_e(s_i) \neq \epsilon\} Spred={si:ye(si)=ϵ} 。接着枚举所有可能的spans对,将 y e ( s i ) , y e ( s j ) y_e(s_i),y_e(s_j) ye(si),ye(sj)作为输入送入RE模型,得到 P r ( r ∣ s i , s j ) P_r(r|s_i,s_j) Pr(r∣si,sj)。
3.3.5 Efficient Batch Computations(高效的批计算)
文中提出的方法,有一个较大的弊端,就是对每个entity pair都要插入不同的typed markers,这就使得同一个 X X X 会因为插入了不同的typed markers而变成与entity pair一一对应的 X ^ \hat{X} X^,也就是一对entity pair就需要一个 X ^ \hat{X} X^与之对应,也就只能有一个训练样本与之对应。换句话说,每一对entity pair都要单独进行模型的训练/预测,可想而知,时间开销会很大。这种较为低效的方法,在文中实验部分称为PURE (Full)。
为了解决这个问题,作者提出一种近似的方法:不在原句子中加入“实体边界+实体类型”的标识符,而是将它们拼接到句子最后面,并用Position embedding实现与原文对应实体位置向量的共享(图c中相同的颜色代表共享相同的位置向量),同时设置attention掩码使得其只能attend到原句子而不会看到后面拼接的标识符。该方法目的是复用句子中所有token的隐向量,使得句子token和typed marker相互独立,就可以避免一对entity pair就需要一个 X ^ \hat{X} X^与之对应的结果了。就可以在一个句子中并行处理多对span pairs了,这种加速方法提升了关系抽取的速度,但是效果会有一些折扣。(后面称为PURE (Approx)。)
3.4 实验结果及分析

pipeline 方法会有曝光误差,即在训练阶段用了 golden truth 作为已知信息对训练过程进行引导,而在推理阶段只能依赖于预测结果。这导致中间步骤的输入信息来源于两个不同的分布,对性能有一定的影响。作者还做了一些实验探究这个问题:
- 类模型在训练时 ① 使用 gold entity ② 使用 jackknifing method(分十份,每一份都用在其它 9 份上训练的模型预测结果)发现还是 ① 最好。曝光误差还是无法证实。
- 如果在实体抽取的时候没抽到 gold entity,那么关系抽取时也一定凉了。作者就扩充了关系抽取实体对的范围,取实体抽取模型输出分数最高的 40% 作为 top span,在这些 span 上 beam search 的方法做关系抽取,发现不行,噪声太多。
结论1:(1)为不同的span pair不同的编码(即NER模型和RE模型采用独立编码的方式)表示非常重要,采用编码共享的方式反而会损害模型的性能;(2)及早融合实体类型信息(即在网络输入层或浅层就融入)可以进一步提高性能;(3)直接使用实体类型作为特征比使用辅助损失函数提供训练信号要好。
记住一点:对于实体关系抽取,2个独立的编码器也许会更好 : )
结论2:(1)实体信息显然有助于关系的预测,但在作者的实验中,还没有找到足够的证据证明关系信息可以显著地提高实体识别的性能;(2)简单地共享编码器有损实体和关系的F1指标。
(详情见论文)
4 PL-Marker
4.1 介绍
目前, span representation提取的方法主要分为三种:T-Concat、Solid Marker、Levitated Marker。
4.1.1 T-Concat
T-Concat 就是将span的边界 token(开始和结束)的嵌入拼接起来用以表示span的嵌入,这种方式停留在token level获取有关信息,也忽略了边界 token之间的关系。这是陈丹琦大佬的《A Frustratingly Easy Approach for Joint Entity and Relation Extraction》(下称PURE)中NER模型就是用的这个方法。
4.1.2 Solid Marker(固定标记)
这种方法则显式地在span首尾各插入固定标记solid marker,以突出显示输入文本中的 span ,而对于object-subject的span对,则会在 subject span 和 object span 前后插入分别一对 solid marker。这种方法难以处理多对 object-subject 的情况,因为它无法在同一句子中区分不同的object和subject,也不能处理 overlapping spans 的情况。
4.1.3 Levitated Marker(悬浮标记)
首先设置一对悬浮标记Levitated Marker,使其与 span 的边界 token共享相同的位置信息,之后通过定向注意机制(directed attention)将一对 Levitated Marker 绑定在一起。具体地说,Levitated Marker中的两个marker会在注意掩码矩阵(attention mask matrix)中被设置为彼此可见,而对于text token 和 其他Levitated Marker的marker来说却是不可见的。
PURE 中RE模型用的就是这种方法,她仅仅是简单地将 solid marker 替换成了带实体类型信息的levitated markers。
4.2 出发点
作者认为PURE方法在训练阶段处理不同的span pairs时,会在句子中独立的插入不同的typed markers,忽略了span pairs和spans之间的内在联系。
因此提出了Packed Levitated Marker (PL-Marker),设计“打包策略”来建模span pairs或spans之间内在联系。在NER阶段,设计面向邻居的打包策略(neighborhood-oriented packing strategy)将拥有相同start token的多个span同时打包放入同一个训练实例中,以此来建模spans之间的内在联系。
在RE阶段,最理想的打包策略就是把所有可能的span pairs打包放入一个训练实例中,进行完整的建模。但是,由于每一对levitated markers中的两个marker已经被定向注意力机制绑定了,若此时再利用定向注意力机制绑定两个levitated markers,那么levitated markers的marker将无法辨别它自己的partner marker。因此,作者采用solid markers与levitated markers混合使用的方式,用solid markers标记subject span,用levitated markers标记候选object,此外,设计面向主语的打包策略(subject-oriented packing strategy)来建模subject和与它相关的所有object之间的内在联系。
4.3 相关工作
现有的提高 span representation 的方法大致可以分为三类: Span Pre-training、Knowledge Infusion、Structural Extension。
4.3.1 span pre-training
详见论文
4.3.2 knowledge infusion
详见论文
4.3.3 structural extension
详见论文
4.4 方法
4.4.1 Levitated Marker背景知识
levitated marker作为solid markers的近似,它允许模型同时对多对实体进行分类,从而加速推理过程。与某个span相关联的一对levitated marker由一个start token marker 和一个end token marker所组成,这两个marker分别与span的start token和end token共享位置embedding,因此原句tokens的位置id不会发生改变。
为了能使多对levitated markers并行处理,需要引入directional attention mask matrix,在这个掩码矩阵的作用下,两个levitated marker partner之间是可见的,而对于其他levitated marker和句子tokens则是不可见的。
(详见PURE)
4.4.2 NER阶段

这部分采用的悬浮标记levitated markers,将所有的可能的实体span的悬浮标记对都放在句子最后面。但是这样就出现了一个问题,因为要遍历句子中所有可能的span,而PLM能处理的句子长度有限。
因此作者提出了Packing的策略,在Packing的时候,考虑到为了更好的分清楚span的边界(更重要的是区分同一个词为开头的span的差别),会将span相近的放在一起,就是将以开头相同的或者相近的放在一个样本中。
对于一个token数量为 N N N 的句子 X = { x 1 , x 2 , ⋯ , x N } X=\{x_1, x_2, \cdots, x_N\} X={x1,x2,⋯,xN} ,规定最大的span长度为 L L L ,具体步骤如下:
- 首先,对所有的悬浮标记对(一个开始标记,一个结束标记)进行排序。首先按照每一对悬浮标记所代表的span的start token的位置升序排序,接着再按end token的位置升序排序,得到排序后的候选span列表。
- 然后,将所有的悬浮标记拆分成 K K K 个组并进行拼接,使得相邻的span的悬浮标记被分在同一个组中(即拼接在一起),拼接之后的 K K K 个悬浮标记序列再分别拼接到句子tokens序列之后,生成 K K K个训练实例(如上图所示, [ O ] , [ / O ] [\text{O}], [/\text{O}] [O],[/O] 表示
levitated markers)。这就是面向邻居的打包策略(neighborhood-oriented packing strategy)。 - 最后,将训练实例送进PLM(如Bert),对于每一对悬浮标记对 s i = ( a , b ) s_i=(a,b) si=(a,b),分别将他们的开始标记(
start token marker)的表征 h a ( s ) h_a^{(s)} ha(s) 和结束标记(end token marker)的表征 h b ( e ) h_b^{(e)} hb(e) 拼接在一起,作为其对应span的表征: ϕ ( s i ) = [ h a ( s ) ; h b ( e ) ] \phi(s_i)=[h_a^{(s)};h_b^{(e)}] ϕ(si)=[ha(s);hb(e)]。 - 而在进行NER的时候,将上述步骤获取到span表征(也就是PL-Marker抽取到的span特征)与T-Concat方法抽取的span表征合并起来起来去预测entity type。怎么个合并法?看代码!
4.4.3 RE阶段

正如上文所说,本文在RE阶段采用solid markers与levitated markers混合使用的方式,用solid markers标记subject span,用levitated markers标记候选object。
假设输入序列为 X X X,subject span为 s i = ( a , b ) s_i=(a,b) si=(a,b) ,以及它的候选object spans: ( c 1 , d 1 ) , ( c 2 , d 2 ) , ⋯ , ( c m , d m ) (c_1,d_1), (c_2,d_2), \cdots, (c_m,d_m) (c1,d1),(c2,d2),⋯,(cm,dm)。具体做法如下:
- 对于句子
subject span首尾分别插入solid marker( [ S ] [\text{S}] [S] 和 [ / S ] [/\text{S}] [/S]),再将它对应的候选object span用悬浮标记的方式( [ O ] [\text{O}] [O] 和 [ / O ] [/\text{O}] [/O])拼接在文本后面(如上图所示)。句子 X = { x 1 , ⋯ , x n } X=\{x_1, \cdots, x_n\} X={x1,⋯,xn}就被改造成(符号 ∪ \cup ∪ 表示共享position embedding):
X ^ = ⋯ , [ S ] , x a , ⋯ , x b , [ / S ] , ⋯ , x c 1 ∪ [ O 1 ] , ⋯ , x d 1 ∪ [ / O 1 ] , ⋯ , x c 2 ∪ [ O 2 ] , ⋯ , x d 2 ∪ [ / O 2 ] , ⋯ \hat{X}= \cdots, [\text{S}], x_a, \cdots, x_b, [/\text{S}], \cdots ,x_{c_1} \cup [\text{O}1], \cdots, x_{d_1} \cup [/\text{O}1], \\ \cdots, x_{c_2} \cup [\text{O}2], \cdots, x_{d_2} \cup [/\text{O}2], \cdots X^=⋯,[S],xa,⋯,xb,[/S],⋯,xc1∪[O1],⋯,xd1∪[/O1],⋯,xc2∪[O2],⋯,xd2∪[/O2],⋯ - 把训练实例送入PLM,对于样本中的每一个span对 span pair = { s s u b j e c t , s o b j e c t } = { ( a , b ) , ( c , d ) } \text{span pair}=\{s_{subject}, s_{object}\}=\{(a,b),(c,d)\} span pair={ssubject,sobject}={(a,b),(c,d)},将subject span前后的
solid marker的表征 h a − 1 h_{a-1} ha−1 和 h b + 1 h_{b+1} hb+1以及一对object span的悬浮标记levitated markers的表征 h c ( s ) h_c^{(s)} hc(s) 和 h d ( e ) h_d^{(e)} hd(e) 拼接在一起,作为这一对span pair的表征:
ϕ ( s i , s j ) = [ h a − 1 ; h b + 1 ; h c ( s ) ; h d ( e ) ] \phi(s_i,s_j) = [h_{a-1}; h_{b+1}; h_c^{(s)}; h_d^{(e)}] ϕ(si,sj)=[ha−1;hb+1;hc(s);hd(e)] - 为了建模实体类型与关系类型之间的关系,他们还增加了预测object 类型的辅助loss函数。
- 为了增加一些补充信息,他们新增了从object到subject的反向关系的预测,从而实现了双向关系的预测,其实就是实现了一个Object-oriented packing strategy。
4.4.4 其他细节 —— Prompt Initialization for NER
受prompt tuning的启发,作者在初始化NER模型时,marker所对应的embedding不用随机初始化,而是embedding of meaningful words,也就是说,用单词[MASK]和entity的词嵌入来初始化marker embedding,发现效果均有一定程度的提升(原文 Table 8)。
4.5 实验结果与分析
4.5.1 结论 from NER实验
- 在所有三个flat NER数据集上,带有
neighborhood-oriented packing strategy的模型比带有随机打包策略的模型更有效,说明neighborhood-oriented packing strategy能更好地建模相邻span之间的相互关系,也就能更好地处理句子较长且marker group更多的数据集。 - 在使用同样的
large pre-trained model作为编码器时,与T-Concat相比,PL-Marker在6个NER基准测试的F1上获得了+0.1%-1.1%的提高,这表明levitated markers在实体类型预测中聚合span representation上的优势。 - 相比于SeqTagger,PL-Marker在实体类型更多的数据集上获得的性能提升更多,这证明了PL-Marker在处理不同类型实体之间的不同相互关系的有效性。
4.5.2 结论 from RE实验
对于PURE,实际上,PURE (Full)采用两对solid marker来标注一对span pair,PURE (Approx)采用两对levitated markers来标注一对span pair。
- 对于PL-Marker的RE阶段,不用
solid marker与levitated markers混合的方式(用solid markers标记subject span,用levitated markers标记候选object)时,即object和subject都用levitated markers标记的同时利用directional attention来绑定levitated markers标记,会造成 2.0%-3.8%的F1指标的下降(原文Table 7)。这证明,继续使用定向注意directional attention来绑定两对levitated markers是次优的,因为每一对悬浮标记的首尾marker之间已经被定向注意绑定了,再次用directional attention来绑定会造成混淆。 - Inverse Relation:作者为每个非对称关系建立了一个双向预测的逆关系,没有的 Inverse Relation 模型反而造成了 0.9%-1.1%的性能下降。这表明在非对称框架下,建模
object和subject之间信息的重要性。 - 作者通过实验(原文Table 7)发现,在PL-Marker的marker都换成typed marker,就像PURE一样,比如 [ S u b j e c t : P E R ] [Subject: PER] [Subject:PER],发现带有
type markers的RE模型比带有entity type loss的RE模型性能稍差些。type markers 与 entity type loss 对模型的提升到底谁好一些,个人觉得没有明确结论,在PURE中得到的结论是type markers好,而本文中却是entity type loss 好。
5 PL-marker vs PURE
总的来说,PL-Marker对PURE的改进主要包括:
- 针对PURE的
levitated marker方式,提出打包策略packed levitated marker。 - 在NER阶段,PURE使用标准的基于
span的方式(T-concat),本文同样使用packed levitated marker的方法做NER任务。 - RE阶段,引入
Inverse Relation,进一步提升了RE性能。同时,取消了PURE使用的typed marker,改用 entity type loss 函数
6 思考
- 本文通过实验发现,相比于
PURE,使用typed marker反而对性能造成了负面影响。个人认为,从遵循直觉角度而言,实体类型信息肯定是会对关系分类起到启发性作用的(特别的,如在“出生日期”和“国籍”两个候选关系类型中,如果存在类型分别是“人物”和“时间”的两个实体,它们之间的关系就是“出生日期”等,而不会是“国籍”),造成本文实验结果的原因可能是使用方式与模型架构不适用导致的,后续可以在这方面进行改进。 NER阶段通过分组的方法,缩减了训练的时间,但时间成本相对于以前的 SOTA 仍较高,毕竟是在枚举所有可能的span。除了分组,是否还有别的方法可以缩减计算时间?
7 Reference
- 绝了!关系抽取新SOTA
- 关系抽取新SOTA: 《A Frustratingly Easy Approach for Joint Entity and Relation Extraction》论文笔记
- 反直觉!陈丹琦用pipeline方式刷新关系抽取SOTA
- NAACL2021 A Frustratingly Easy Approach for Joint Entity and Relation Extraction
- 论文笔记 – A Frustratingly Easy Approach for Joint Entity and Relation Extraction
- 实体关系联合抽取-A Frustratingly Easy Approach for Entity and Relation Extraction





![C#处理Gauss光斑图像[通过OpenGL和MathNet]](https://img-blog.csdnimg.cn/20210526102441529.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L20wXzM3ODE2OTIy,size_16,color_FFFFFF,t_70#pic_center)