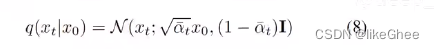聚类分析概念
聚类分析是根据给出数据中发现描述对象及关系的信息,对数据对象进行分组的过程。
聚类是一种寻找数据之间内在结构的技术,聚类把全体数据实例组织成一些相似组,这些相似组被称作簇,处于相同簇中的数据实例彼此相同(相关),处于不同簇中的实例彼此不同的(不相关)。
聚类分析是一种无监督学习,与监督学习不同的是,簇中表示数据类别分类或者信息是没有的,是对位置类别的样本进行划分,按照一定的规则划分为若干个簇类,揭示其中存在的规律。
在数学建模中,聚类分析可以应用在数据预处理过程中,对于复杂结构的多维数据可以通过聚类分析的方法对数据进行聚集,使复杂结构数据标准化。聚类分析还可以用来发现数据项之间的依赖关系,从而去除或合并有密切依赖关系的数据项。聚类分析也可以为某些数据挖掘方法(如关联规则、粗糙集方法),提供预处理功能。在商业类问题上,聚类分析是细分市场的有效工具,被用来发现不同的客户群,并且它通过对不同的客户群的特征的刻画,被用于研究消费者行为,寻找新的潜在市场等等。
聚类分析算法
聚类分析算法主要分为五大类:基于划分的聚类方法、基于层次的聚类方法、基于密度的聚类方法、基于网格的聚类方法和基于模型的聚类方法。
- 基于划分的聚类(k‐均值算法、k‐medoids算法、k‐prototype算法)
- 基于层次的聚类
- 基于密度的聚类(DBSCAN算法、OPTICS算法、DENCLUE算法)
- 基于网格的聚类
- 基于模型的聚类(模糊聚类、Kohonen神经网络聚类)
数学建模常用算法
聚类分析算法有很多种,在数学建模中基于划分的聚类方法是最常用的,本文主要介绍K-means聚类。
k‐均值聚类算法,通过计算样本点与类簇质心的距离,将类簇质心相近的样本点划分为同一类簇。并通过样本间的距离来衡量它们之间的相似度,两个样本距离越远,则相似度越低,反之相似度越高。
k-均值算法:
- 选择 K 个初始质心(K需要用户指定),初始质心随机选择即可,每一个质心为一个类
- 对剩余的每个样本点,计算它们到各个质心的欧式距离,并将其归入到相互间距离最小的质心所在的簇。计算各个新簇的质心。
- 在所有样本点都划分完毕后,根据划分情况重新计算各个簇的质心所在位置,然后迭代计算各个样本点到各簇质心的距离,对所有样本点重新进行划分
- 重复2. 和 3.,直到质心不在发生变化时或者到达最大迭代次数时
k-均值算法优缺点
- k‐均值算法原理简单,容易实现,且运行效率比较高(优点)
- k‐均值算法聚类结果容易解释,适用于高维数据的聚类(优点)
- k‐均值算法采用贪心策略,导致容易局部收敛,在大规模数据集上求解较慢(缺点)
- k‐均值算法对离群点和噪声点非常敏感,少量的离群点和噪声点可能对算法求平均值产生极大影响,从而影响聚类结果(缺点)
- k‐均值算法中初始聚类中心的选取也对算法结果影响很大,不同的初始中心可能会导致不同的聚类结果。对此,研究人员提出k‐均值++算法,其思想是使初始的聚类中心之间的相互距离尽可能远
k‐均值++算法:
- 从样本中随机选择一个样本点ܿx1作为第一个聚类中心
- 计算其它样本点x到最近的聚类中心的距离݀d(x)
- 以概率
选择一个新样本点x2加入聚类中心集合中,其中距离值越大,被选中的概率就越高
- 重复2和3选定k个聚类中心
- 基于这k个聚类中心进行k-均值运算
k‐均值++算法的优缺点
- 提高局部最优点质量,收敛更快(优点)
- 相比随机选择中心点计算较大(缺点)
聚类分析评估
聚类分析评估是聚类过程的最后一步
聚类过程
- 数据准备:包括特征标准化和降维;
- 特征选择:从最初的特征中选择最有效的特征,并将其存储于向量中;
- 特征提取:通过对所选择的特征进行转换形成新的突出特征;
- 聚类(或分组):首先选择合适特征类型的某种距离函数(或构造新的距离函数)进行接近程度的度量,而后执行聚类或分组;
- 聚类结果评估:是指对聚类结果进行评估,评估主要有3种:外部有效性评估、内部有效性评估和相关性测试评估。
一个良好的聚类算法应具备良好的可伸缩性,处理不同的类型数据的能力,处理噪声数据的能力,对样本数据顺序的不敏感性,约束条件下良好的表现,易解释性和易用性。
聚类分析结果的好坏可以从内部指标和外部指标评判:
- 外部指标指用事先指定的聚类模型作为参考来评判聚类结果的好坏
- 内部指标是指不借助任何外部参考,只用参与聚类的样本评判聚类结果好坏
案例
五个品种八个属性进行聚类:
% 五个品种八个属性进行聚类
%Matlab程序如下:
X=[7.90 39.77 8.49 12.94 19.27 11.05 2.04 13.29
7.68 50.37 11.35 13.30 19.25 14.59 2.75 14.87
9.42 27.93 8.20 8.14 16.17 9.42 1055 9.76
9.16 27.98 9.01 9.32 15.99 9.10 1.82 11.35
10.06 28.64 10.52 10.05 16.18 8.39 1.96 10.81 ]';
Y=pdist(X);
SF=squareform(Y);
Z=linkage(Y,'average');
dendrogram(Z);
T=cluster(Z,'maxclust',3)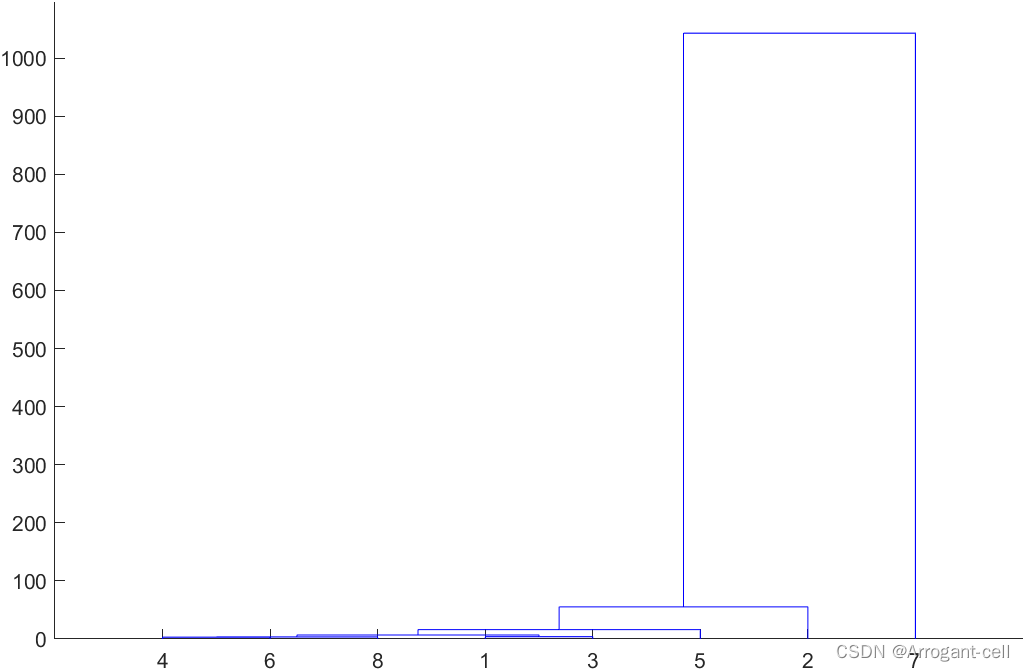
K-means聚类matlab代码
function [Idx, Center] = K_means(X, xstart)
% K-means聚类
% Idx是数据点属于哪个类的标记,Center是每个类的中心位置
% X是全部二维数据点,xstart是类的初始中心位置len = length(X); %X中的数据点个数
Idx = zeros(len, 1); %每个数据点的Id,即属于哪个类C1 = xstart(1,:); %第1类的中心位置
C2 = xstart(2,:); %第2类的中心位置
C3 = xstart(3,:); %第3类的中心位置for i_for = 1:100%为避免循环运行时间过长,通常设置一个循环次数%或相邻两次聚类中心位置调整幅度小于某阈值则停止%更新数据点属于哪个类for i = 1:lenx_temp = X(i,:); %提取出单个数据点d1 = norm(x_temp - C1); %与第1个类的距离d2 = norm(x_temp - C2); %与第2个类的距离d3 = norm(x_temp - C3); %与第3个类的距离d = [d1;d2;d3];[~, id] = min(d); %离哪个类最近则属于那个类Idx(i) = id;end%更新类的中心位置L1 = X(Idx == 1,:); %属于第1类的数据点L2 = X(Idx == 2,:); %属于第2类的数据点L3 = X(Idx == 3,:); %属于第3类的数据点C1 = mean(L1); %更新第1类的中心位置C2 = mean(L2); %更新第2类的中心位置C3 = mean(L3); %更新第3类的中心位置
endCenter = [C1; C2; C3]; %类的中心位置%演示数据
%% 1 random sample
%随机生成三组数据
a = rand(30,2) * 2;
b = rand(30,2) * 5;
c = rand(30,2) * 10;
figure(1);
subplot(2,2,1);
plot(a(:,1), a(:,2), 'r.'); hold on
plot(b(:,1), b(:,2), 'g*');
plot(c(:,1), c(:,2), 'bx'); hold off
grid on;
title('raw data');%% 2 K-means cluster
X = [a; b; c]; %需要聚类的数据点
xstart = [2 2; 5 5; 8 8]; %初始聚类中心
subplot(2,2,2);
plot(X(:,1), X(:,2), 'kx'); hold on
plot(xstart(:,1), xstart(:,2), 'r*'); hold off
grid on;
title('raw data center');[Idx, Center] = K_means(X, xstart);
subplot(2,2,4);
plot(X(Idx==1,1), X(Idx==1,2), 'kx'); hold on
plot(X(Idx==2,1), X(Idx==2,2), 'gx');
plot(X(Idx==3,1), X(Idx==3,2), 'bx');
plot(Center(:,1), Center(:,2), 'r*'); hold off
grid on;
title('K-means cluster result');disp('xstart = ');
disp(xstart);
disp('Center = ');
disp(Center);参考文献
https://blog.csdn.net/weixin_43584807/article/details/105539675
https://zhuanlan.zhihu.com/p/139924042
https://www.bilibili.com/video/BV1kC4y1a7Ee?p=19&vd_source=08ffbcb9832d41b9a520bccfe1600cc9


![C#处理Gauss光斑图像[通过OpenGL和MathNet]](https://img-blog.csdnimg.cn/20210526102441529.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L20wXzM3ODE2OTIy,size_16,color_FFFFFF,t_70#pic_center)