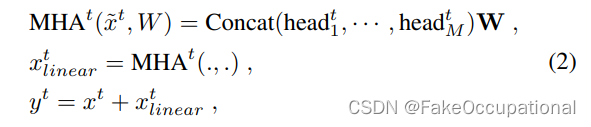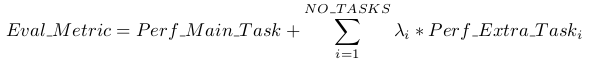语言模型是无监督的多任务学习者
摘要
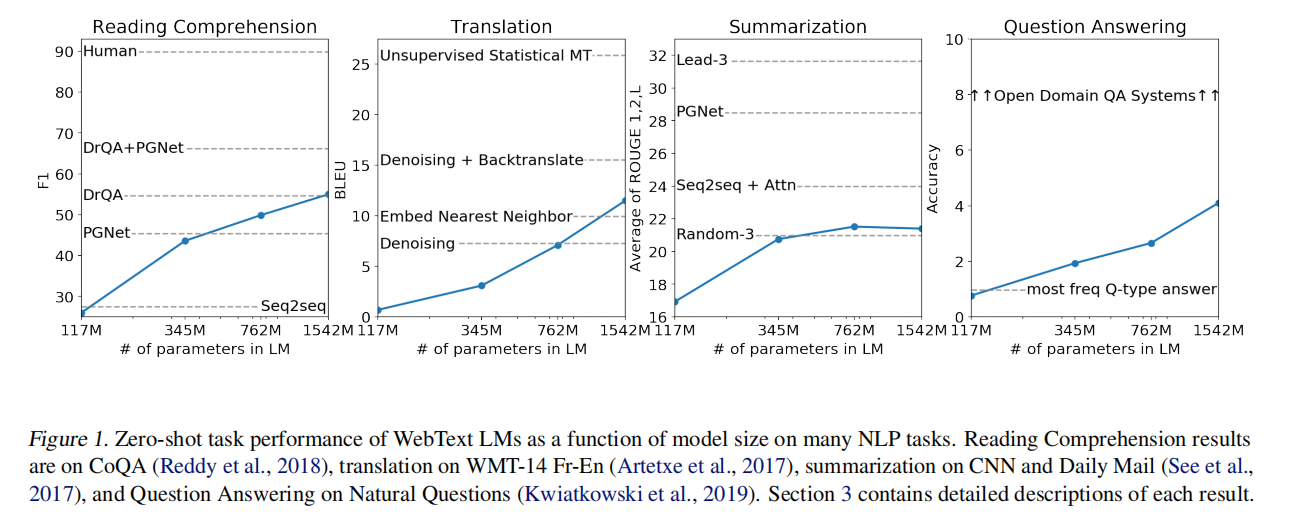
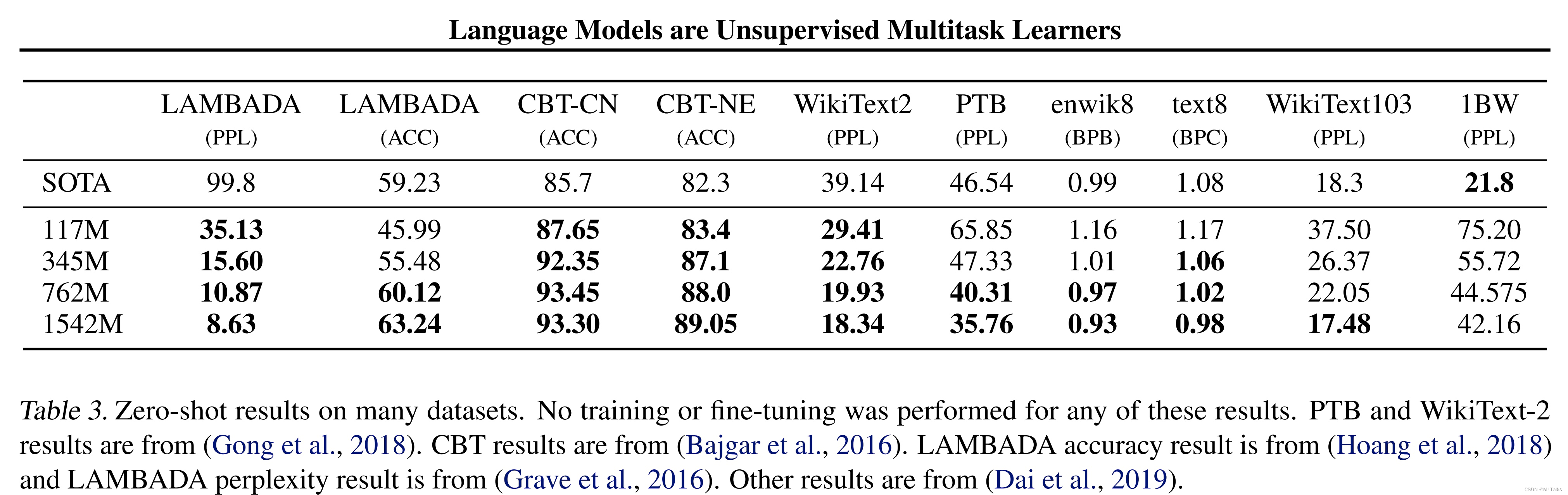
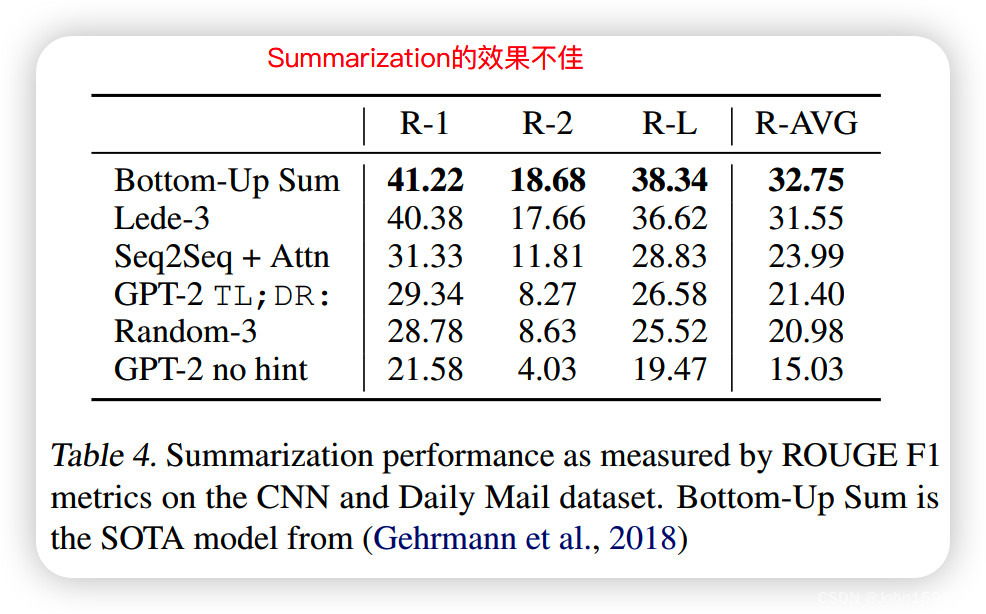
自然语言处理任务,如问题回答、机器翻译、阅读理解和总结,通常是通过任务特定数据集上的监督学习来完成的。我们证明,当语言模型在一个称为WebText的数百万网页的新数据集上训练时,它们可以在没有任何明确监督的情况下开始学习这些任务。当以文档和问题为条件时,语言模型生成的答案在CoQA数据集上达到55F1—在不使用127,000+训练示例的情况下匹配或超过4个基线系统中的3个。语言模型的能力对于零起点任务转移的成功是至关重要的,提高它可以以对数线性的方式提高任务之间的性能。我们最大的模型,GPT-2,是一个1.5B的参数转换器,在零镜头设置下,在8个测试的语言建模数据集中,有7个获得了最先进的结果,但仍然不适合WebText。模型中的样本反映了这些改进,并包含了连贯的文本段落。这些发现为构建语言处理系统提供了一条有希望的道路,该系统可以从自然发生的演示中学习执行任务。
Introduction
机器学习系统现在通过使用大数据集、大容量模型和监督学习的组合(Krizhevsky et al., 2012) (Sutskever et al., 2014) (Amodeiet al., 2016)来训练它们。这些系统对数据分布(Recht等,2018)和任务规范(Kirkpatrick等,2017)的变化是脆弱和敏感的。当前的系统更容易被描述为狭隘的专家,而不是称职的通才。我们希望向更通用的系统发展,它可以执行许多任务,最终不需要为每个任务手动创建和标记一个训练数据集。
创建ML系统的主要方法是:收集显示所需任务的正确行为的训练示例数据集,训练系统模仿这些行为,然后在独立且同分布(IID)的保留示例上测试其性能。这有助于在狭隘的专家上取得进展。但是标题模式(Lake et al.,2017)、阅读理解系统(Jia &(Liang, 2017)和图像分类器(Alcorn et al., 2018)对可能输入的多样性和多样性进行了研究,突出了这种方法的一些缺点。
我们怀疑,在单一领域数据集上进行单一任务训练的普遍性是导致当前系统缺乏泛化的主要原因。在当前架构下,向健壮系统的进展可能需要在广泛的领域和任务上进行培训和性能度量。最近,一些基准指标被提出,如GLUE (Wang et al., 2018)和decaNLP (McCann et al., 2018)开始研究这一点。
多任务学习(Caruana, 1997)是一种很有前途的提高综合性能的框架。然而,多任务训练在NLP中还处于起步阶段。最近的工作报告显示了适度的性能改进(Yogatama等人,2019年)和迄今为止最雄心勃勃的两项努力,分别训练了10对和17对(数据集,目标)(McCann等人,2018年)(Bowman等人,2018年)。从元学习的角度来看,每对(数据集、目标)都是从数据集和目标的分布中抽取的单个训练示例。目前的ML系统需要数百至数千个例子来归纳归纳功能。这表明,许多多任务训练需要许多有效的训练对,以实现其承诺与当前的方法。要想继续扩大数据集的创建和目标的设计,达到用现有技术强行达到的程度,将是非常困难的。这就激发了他们去探索额外的多任务学习设置。
当前在语言任务上表现最好的系统利用预先训练和监督微调的组合。这一方法历史悠久,其趋势是更灵活的传输形式。首先,单词学习和使用向量作为输入特定于任务的架构(Mikolov et al ., 2013) (Collobert et al ., 2011),然后传输循环网络的上下文表示(戴&勒,2015)(Peters等人,2018),和最近的研究表明,特定于任务的架构都不再必要,转移许多self-attention块就足够了(雷德福et al ., 2018) (Devlin et al ., 2018)。
为了完成一项任务,这些方法仍然需要监督训练。当只有极少的或没有监督数据可用时,另一个领域的研究表明,语言模型有望执行特定的任务,如常识推理(Schwartz et al., 2017)和情感分析(Radford et al., 2017)。
在本文中,我们将这两种工作联系起来,并讨论更一般的转移方法的发展趋势。我们证明了语言模型可以在不需要任何参数或结构修改的情况下,在零距离设置下执行下游任务。我们通过强调语言模型在零镜头设置下执行广泛任务的能力来展示这种方法的潜力。我们根据任务实现有希望的、有竞争力的和最先进的结果。
Approach
我们方法的核心是语言建模。语言建模通常被描述为一组示例(x1, x2,…(x n)每个符号由可变长度的符号序列组成(s1, s2,…,s, n)。由于语言具有自然的顺序性,通常将符号上的联合概率因式分解为条件概率的乘积(Jelinek & Mercer, 1980) (Bengio et al., 2003)。
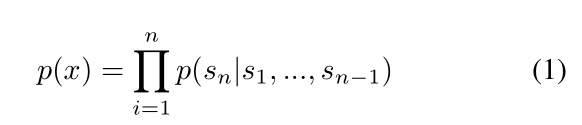
这种方法允许对p(x)进行可处理的采样和估计,以及p(s n-k,…,s n |s 1,…,s n-k-1)。近年来,可以计算这些条件概率的模型的表达性有了显著的改进,例如Transformer这样的自我关注架构(Vaswani et al., 2017)。
学习执行单个任务可以在概率框架中表示为估计一个条件分布p(输出|输入)。由于一个通用系统应该能够执行许多不同的任务,即使对于相同的输入,它不仅应该对输入设置条件,而且还应该对要执行的任务设置条件。也就是说,它应该对p(输出|输入,任务)进行建模。这在多任务和元学习环境中得到了不同程度的形式化。任务调节通常在架构级实现,例如任务特定的编码器和解码器(Kaiser et al., 2017),或者在算法级实现,例如MAML的内环和外环优化框架(Finn et al., 2017)。但如McCann等人(2018)所示,语言提供了一种灵活的方式来指定任务、输入和输出,所有这些都是作为符号序列。例如,可以将翻译训练示例编写为序列(翻译成法语、英语文本、法语文本)。同样,一个阅读理解训练的例子可以写成(回答问题、文档、问题、答案)。McCann等人(2018)证明了训练单一模型MQAN是可能的,在使用这种格式的示例上推断并执行许多不同的任务。
原则上,语言建模也能够学习McCann等人(2018)的任务,而不需要明确地监督哪些符号是要预测的输出。由于监督目标与无监督目标相同,但仅在序列的一个子集上求值,因此无监督目标的全局最小值也是有监督目标的全局最小值。在这个稍微有些玩具的设置中,(Sutskever et al., 2015)中讨论的将密度估计作为原则性训练目标的关注点被搁置一边。相反,问题变成了我们能否在实践中优化无监督目标以使其收敛。初步实验证实,足够大的语言模型能够在这种玩具式的设置中执行多任务学习,但学习速度比显式监督方法慢得多。
虽然这是一个很大的步骤,从上面描述的良好的设置到混乱的 “language in the wild”, Weston(2016)认为,在对话的上下文中,为了开发能够直接学习自然语言的系统,并且证明了一个概念——通过使用教师输出的前向预测,在没有奖励信号的情况下学习QA任务。虽然对话是一种吸引人的方式,但我们担心它过于严格。互联网包含了大量的信息,人们可以被动地获取这些信息,而不需要进行互动交流。我们推测,一个具有足够能力的语言模型将开始学习推断和执行自然语言序列中所演示的任务,以便更好地预测它们,而不管它们的获取方法如何。如果一个语言模型能够做到这一点,那么它实际上就是在执行无监督的多任务学习。我们通过分析语言模型在各种任务上的零距离设置的性能来测试是否存在这种情况。
2.1 训练数据集
之前的大多数工作都是在单一的文本上训练语言模型,比如新闻文章(Jozefowicz et al., 2016),维基百科(Merity et al., 2016)或小说(Kiros et al., 2015)。我们的方法鼓励建立尽可能大和多样化的数据集,以收集在尽可能多的领域和环境中任务的自然局域网语言演示。
一个有前途的来源,多样化和几乎无限的文本是网页提取,如常见的爬虫。虽然这些归档文件比当前的语言建模数据集要大很多个数量级,但它们存在严重的数据质量问题。陈,Le(2018)在他们关于常识推理的工作中使用了普通的爬虫,但注意到大量文档的内容大多难以理解。在我们最初的普通爬虫实验中,我们发现了类似的数据问题。陈,Le(2018)的最佳结果是通过使用一个小的常见抓取子样本实现的,该子样本只包含与目标数据集最相似的文档,即Winograd模式挑战。虽然这是一种提高特定任务性能的实用方法,但我们希望避免对将要提前执行的任务做出假设。
相反,我们创建了一个新的web提取,它强调文档质量。为了做到这一点,我们只抓取那些由人类管理/过滤的网页。手动过滤一个完整的网页抓取会非常昂贵,所以作为一个起点,我们从社交媒体平台Reddit上抓取所有的出站链接,这个平台至少收到了3个karma。这可以被看作是其他用户是否觉得链接有趣、有教育意义或仅仅是有趣的启发式指示器。
得到的数据集WebText包含这4500万个链接的文本子集。为了从HTML响应中提取文本,我们结合使用了Dragnet (Peters &《Lecocq, 2013》和《报纸1》的内容提取器。本文中的所有研究都使用了WebText的初步版本,该版本不包括在2017年12月之后创建的链接,在删除重复和基于启发式清理之后,该版本包含了总计40gb文本的800多万个文档。