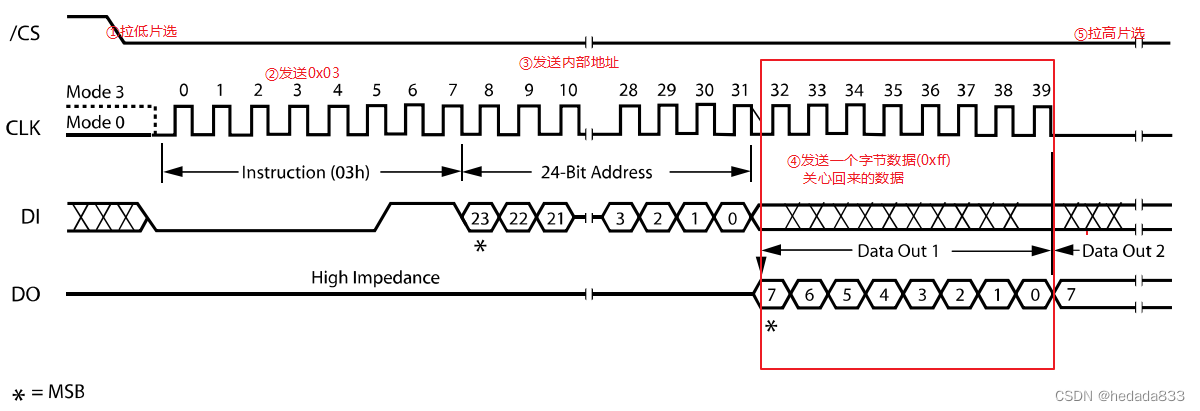
1. 论文阅读
论文地址:Language Models are Unsupervised Multitask Learners
1.1 背景介绍
2019年OpenAI发布的模型,OpenAI在2018年的GPT1中给出了一种半监督的训练方法,在GPT2中针对如下问题做了升级:
- 以前机器学习训练代价大,往往先要指定训练任务和高质量的标注数据集,且要保证训练数据和测试数据的分布相同,不同任务间无法复用;GPT2实现一个更通用的系统,支持多种NLP任务的学习,实现了Zero Shot。
- 大模型训练往往需要海量数据,准备高质量的标注数据集明显是不现实的;GPT2中支持使用网上公开的无标注的数据进行训练。
1.2 方法实现
在GPT1的基础上,GPT2中在多种NLP任务表示、训练数据准备、输入表示、模型设计四个方面上进行了改进实现。
1.2.1 多种NLP任务表示
论文关注的核心是NLP的语言模型,对于一个指定的NLP任务来说是通过条件概率p(output|input)来获取输出;对于多任务学习来说,输出应该跟任务是相关的,即p(output|input,task);参考论文【Multitask Learning as Question Answering】把多种NLP训练任务都变成了基于上下文的问答任务(Question-Answering-Over-Context)。例如翻译任务表示成(translate to french, english text, french text),阅读理解任务表示成(answer the question, document question, answer)
1.2.2 训练数据
使用了自己准备的WebText数据集,使用了Dragnet和newspaper内容提取器。总共有800万文档,共40GB的文本数据。
1.2.3 输入表示
输入表示采用了BPE(Byte Pair Encoding)算法进行tokenizer,这里没有直接使用Unicode做为基础的词表,因为Unicode共有超过130000个字符太多了,这里采用了字节粒度的BPE,初始词表有256个(2**8)。
1.2.4 模型设计
模型设计上是基于GPT1进行改造的,GPT1的结构是基于transformer decoder设计的。GPT2的结构如下:
GPT2跟GPT1相比不同的点在于以下几点:
- 对于每个子block的输入都加上了layer norm,类似于resnet
- 在self-attention的最后也加上一个额外的layer norm
- residual层的权重初始化乘上了
1/sqrt(N),N是residual的层数 - 词表扩展到了50257个
- 上下文的大小从512增加到了1024个token
- batch size使用512大小
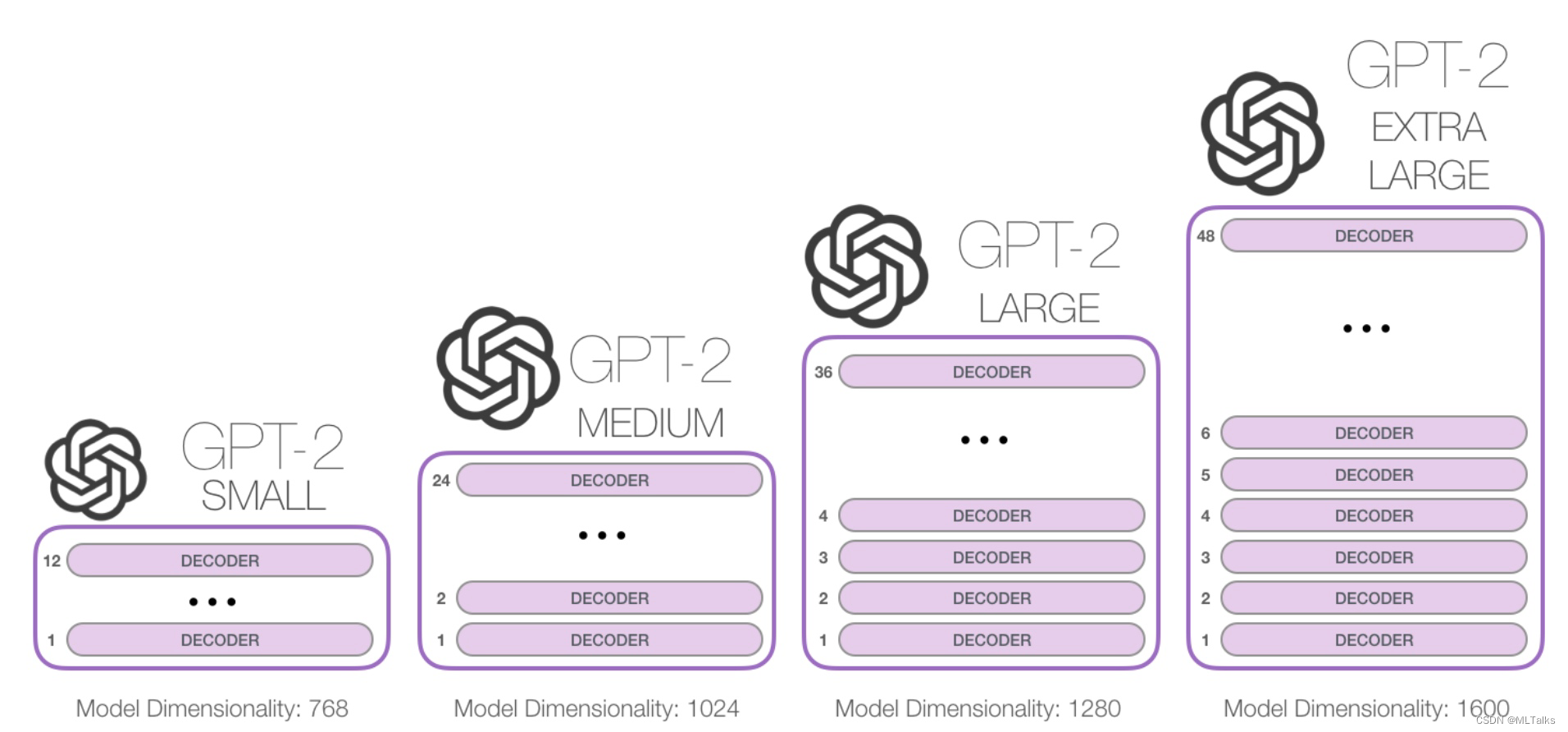
GPT2的不同网络结构的参数大小如下:

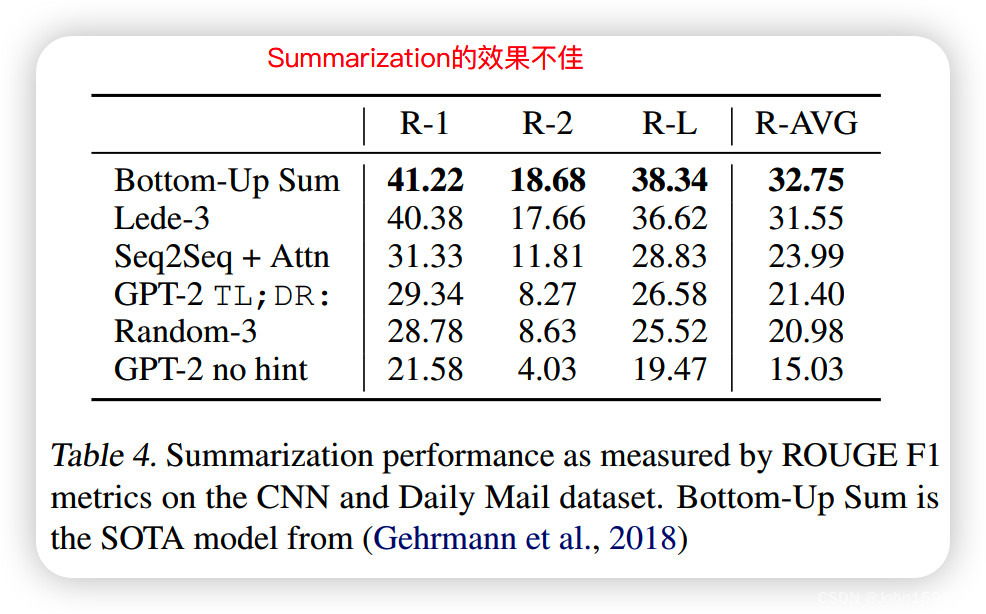
效果上zero-shot不用经过训练和finetune有些也可以达到SOTA:
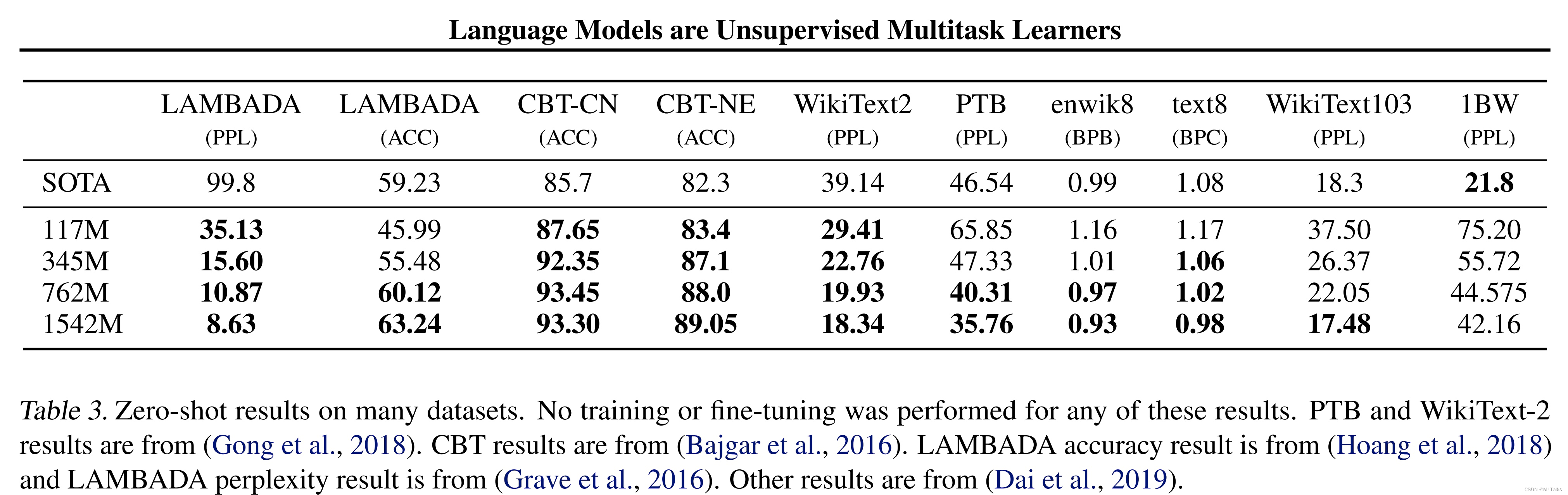
2. 参考
- Language Models are Unsupervised Multitask Learners
- Multitask Learning as Question Answering
- Unicode
- The Illustrated GPT-2 (Visualizing Transformer Language Models)
- Understanding Transformer model architectures
- GPT-1 to GPT-4: Each of OpenAI’s GPT Models Explained and Compared