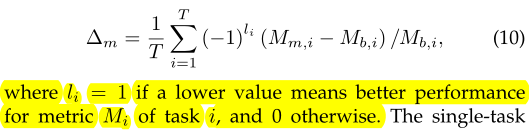前言
-
本文源自
ICLR 2022 -
原文地址:Multitask Prompted Training Enables Zero-shot Task Generalization
-
Discussion中提到的FLAN参考博文 【论文阅读】Finetuned Language Models Are Zero-Shot Learners_长命百岁️的博客-CSDN博客
Abstract
大模型在多种任务上学习提高了 zero-shot 泛化能力,有人假设这是语言模型在隐式多任务学习的结果。
zero-shot 泛化能力能否通过显式多任务学习来直接引发呢?
1.Introduction
目标:训练一个模型能够在留出任务上泛化性更好,且不需要很大的模型规模,同时对于 prompt 的措辞选择更鲁棒。
实验学习了两个问题:
- 多任务 prompted training 是否提升了在留出任务上的泛化性
- 我们发现,多任务训练增强了在 zero-shot 任务上的泛化能力
- 在更大范范围的 prompts 上进行训练是否能够提升 prompt 措辞的鲁棒性
- 我们发现,在每个数据集上进行更多 prompt 的训练始终提高在留出任务上性能的中位数,并减少变化性

2.Related work
3.Measuring generalization to held-out tasks

本文提供了四个保留任务(绿色部分):
- 自然语言推理
- 共指消解
- 句子补全
- 词意消歧
同时也在 BIG-bench(这是最近一个由社区驱动的基准测试,它创建了各种各样的困难任务集合,以测试大型语言模型的能力) 中的部分数据集上评估。所有源自 BIG-bench 的任务都是新任务,是从训练中留出的。
4.A unfied prompt format
所有数据集都是以自然语言 prompt 的格式给到模型,以实现 zero-shot 实验。
定义 prompt 为:包含一个输入模板和一个目标模板,并且带有一组相关元数据
- 模板是将数据示例映射为输入和目标序列的自然语言的函数。实际上,模板允许用户将任何文本与数据字段,元数据,其他用于呈现和格式化原始字段的代码混合
比如一个NLI数据,包含字段premise,Hypothesis,Label。
- 输入模板:If {Premise} is true, is it also true that {Hypothesis}?
- 目标模板:{Choices[label]}
- 这里 choice 是 prompt-specific 元数据,包含选项:yes,maybe,no。对应着label 是 entailment(0),neutral(1),contradiction(2)。

我们收集了一个 prompt 集合,叫做Public Pool of Prompts(P3),包含了对 177 个数据集的 2073 个prompt。实验中使用的 prompt 除BIG-bench外均来自P3, BIG-bench的 prompt 由其维护人员提供。
5.Experimental setup
Model:使用 encoder-decoder 结构,通过最大似然训练训练模型自动生成目标。与GPT-3等纯解码器语言模型不同,它从未被训练生成输入
我们训练的所有模型都基于 T5,一个基于transformer的 encoder-decoder 语言模型,使用 masked 语言建模风格的目标对来自C4的1T tokens进行预训练。由于 T5 的预训练目标是生成从输入文本中移走的 token,它不同于 prompt 数据集的自然文本生成格式。因此使用 LM-adapted T5(T5+LM) 模型(将 T5 利用标准语言建模目标在来自C4的额外 100B tokens 上训练得到)
Training:T0在section3和table5中的数据集上训练,T0+用的是相同超参,但是额外添加了 GPT-3 的评估数据集。T0++进一步增加了 SuperGLUE。
因为数据集大小区别很大,因此我们将超过 500000样本的数据集看为只有 500000/num_template 样本。num_template 是为数据集创建的模板数目。我们将出入和输出序列分别截断至 1024 和 256 token,使用 packing 来结合多个训练样本到一个序列中来达到最大序列长度。batch size:1024 sequences,optimizer:Adafactor,learning rate:1e-3,dropout rate:0.1
Evaluation:
6.Results
6.1.Generalization to held-out tasks
我们的第一个研究问题是,多任务 prompted training是否能提高对留出任务的泛化能力。
- 我们的方法在所有数据集的baseline上都有很大的提升,说明了了多任务 prompted training 比只使用相同的模型和prompts进行语言建模训练的好处。
接着,比较了 T0 与可获得的最大的语言模型(多种达到175B参数的 GPT-3 模型)的 zero-shot 性能。
- 发现在 11 个留出数据集中的 9 个上比得上/超过 GPT-3。
- 值得注意的是,T0和GPT-3都没有接受自然语言推理方面的训练,但T0在所有NLI数据集上的表现都优于GPT-3,尽管我们的 baseline T5+LM没有
大多数情况下,我们的模型表现随着训练数据的增加而提升。

在 BIG-bench中,我们发现至少有一个 T0 的变种比所有的 baseline 都要好(除了 StrategyQA)

6.2.Prompt robustness
我们的第二个研究问题就是:在更大范围的 prompts 上进行训练是否能够提升对 prompts 措辞的鲁棒性。
做了两个消融实验
- 针对每个数据集中 prompts 的平均数量(p)
- 训练时使用的数据集的数量(d)
Effect of More Prompts per Dataset:T0(p=8.03)在一些没有映射为数据集原始任务的 prompts 上训练。
p=1,每个数据集随机选一个原始任务的 prompt。p=5.7,所有数据集都使用所有的原始任务prompts。p=0,对应 T5+LM,没有任何 prompts。在每个数据集的更多 prompt上训练能够在留出任务上获得更好,更鲁棒的泛化性。从 p = 1 p=1 p=1到 p = 5.7 p=5.7 p=5.7在中位数与 spread 都有额外的改善,这强化了我们的假设:针对每个数据集的更多提示进行训练,可以使留出任务的泛化更好、更健壮。T0包含了所有 prompts(包括哪些不对应于数据集原始任务的),进一步提升了效果,显示了在不是原始任务的 prompts 上训练也有收益。

Effect of prompts from more datasets:
令 p=所有可以获得的 prompts,增加 d。
增加d似乎并不能始终使模型对提示的措辞更加稳健。

Comparing T0 and GPT-3’s robustness:结果表明,T0 比 GPT-3 对 prompt 格式更鲁棒。
7.Discussion
同时期的工作,FLAN,使用了基本同样的方法,通过多任务 prompted 训练来增强 zero-shot 泛化能力。通过与我们相似的数据集混合,FLAN 训练了多个 decoder-only 语言模型,每个都对应一个单独的留出任务(我们关注于训练一个对应多个留出任务的模型,以能够分析模型在多种任务上泛化的能力)。
与 FLAN 相比,T0 的性能有更好的也有更差的,T0++基本都比得上或者更好。但是,这俩模型比 FLAN 小了十多倍(137B vs 11B)。
T0 和 FLAN 在 Winogrande 和 HellaSwag 上的性能都不如 GPT-3。Wei et al(2021) 猜测对于可以表示成补充一个不完整句子的任务(比如:共指消解),将任务指令添加到提示中“很大程度上是多余的。
Wei et al(2021) 做了一个消融实验,模型大小与 T0(11B)类似(8B),发现在多任务 prompted 训练后,在留出任务上的性能下降,而我们发现多任务 prompted 训练至少在3B参数下提高了模型的性能。我们确定了两个模型之间的关键差异,可以解释这种差异:
- 我们使用了 encoder-decoder 模型,在作为标准的语言模型训练之前,进行了不同目标的训练(masked 语言建模),然后在多任务混合上 fine-tune。这种预训练策略是更有效的。
- 我们的 prompt 在长度和创造性方面在质量上更加多样化,我们假设这种多样性可能会产生具体的影响。比如,这可以解释为什么Wei等人(2021)提出的消融结果,其中增加 prompt 的数量对性能的影响可以忽略不计,而我们观察到增加更多 prompt 时的改善
8.Conclusion
我们证明了多任务提示训练可以在语言模型中实现强大的 zero-shot 泛化能力。这种方法为无监督语言模型预训练提供了一个有效的可替代方法,常使我们的 T0 模型优于数倍于其自身大小的模型。我们还进行了消融研究,展示了包括许多不同 prompt 的重要性,以及在每个任务中增加数据集数量的影响。