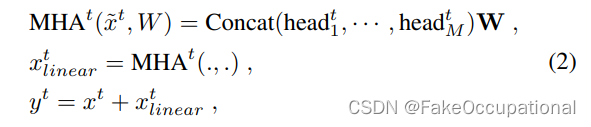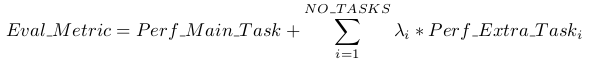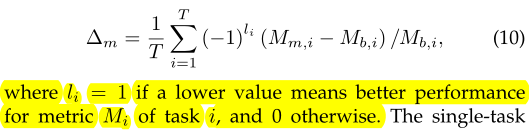作为一个刚刚入门NLP的学生,希望在阅读每一篇论文后都进行一定的记录,提炼文中观点,写出自己的理解,如有任何解读错误之处敬请指出,O(∩_∩)O谢谢!
先放出paper的网址 https://arxiv.org/pdf/1806.08730.pdf
key words
- Multitask Learning
- Zero-shot Learning
- Transfer Learning
- Meta-Learning
前言
当今QA问题在NLP领域可以说是炽手可热,SQUAD数据集的出现,大量RNN,Attention的模型出现将SQUAD1.0的简单问题准确度提高至超越人类。我的同学也有在做SQUAD的,基本上是在别人模型的输入和encoder端上面做些小trick,提升那么1、2个百分点的EM/F1,在我看来这些工作真的是毫无意义。
本篇文章的作者的一句话直中要害:
The quirk of the dataset does not hold for question answering in general, so recent models for SQUAD are not necessarily general QA models.
数据集的“怪癖”并不对普遍的QA问题适用,所以当前的QA Model都不是通用模型。
然而跳出SQUAD的局限,我们确实可以借助QA模型来解决很多其他的NLP子问题,比如我们Apex实验室小组将QA用于关系提取,搭建了QA4IE框架。本篇文章更是将QA模型的能力发挥到了极致,一个通用框架解决10个NLP子问题,真的非常酷。
| Task | QA | Machine Translation | Summarization | Natrual Language Inference | Semantic Analysis | Semantic Role Labeling | Zero-shot RE | Goal-Oriented Dialogue | Semantic Parsing | Pronoun Resolution |
|---|---|---|---|---|---|---|---|---|---|---|
| Dataset | SQUAD | IWSLT | CNN/DM | MNLI | SST | QA-SRL | QA-ZRE | WOZ | WikiSQL | MWSL |
为什么可以通用?
通用模型的关键是——这十个子问题都可以被规约为同一个问题,即输入一段context,一个query,输出一个Answer,且三者均为字符串序列。
如机器翻译:
| context | question | Answer |
|---|---|---|
| English text | What is the translation from English to German? | German text |
看到这有人会问,德语在原文、问题中也不存在啊,你怎么得到答案?这个在后面会说,模型引入了一个External Vocabulary解决这种文中no answer的问题。
模型

Encoder
C ∈ R l × d e m b , Q ∈ R m × d e m b , A ∈ R n × d e m b C\in R^{l \times d_{emb}},Q\in R^{m \times d_{emb}},A\in R^{n \times d_{emb}} C∈Rl×demb,Q∈Rm×demb,A∈Rn×demb
- 过线性层映射到d维空间
C W 1 = C p r o j ∈ R l × d CW_1 = C_{proj}\in R^{l\times d} CW1=Cproj∈Rl×d Q W 1 = Q p r o j ∈ R m × d QW_1 = Q_{proj}\in R^{m\times d} QW1=Qproj∈Rm×d - 过BiLSTM编码 -> C i n d , Q i n d C_{ind},Q_{ind} Cind,Qind
- 添加一维dummy embedding
- 对齐
s o f t m a x ( C i n d Q i n d T ) = S c q ∈ R ( l + 1 ) × ( m + 1 ) softmax(C_{ind}Q_{ind}^T) = S_{cq}\in R^{{(l+1)}\times {(m+1)}} softmax(CindQindT)=Scq∈R(l+1)×(m+1) s o f t m a x ( Q i n d C i n d T ) = S q c ∈ R ( m + 1 ) × ( l + 1 ) softmax(Q_{ind}C_{ind}^T) = S_{qc}\in R^{{(m+1)}\times {(l+1)}} softmax(QindCindT)=Sqc∈R(m+1)×(l+1) - Dual Coattention
S q c T S c q T C i n d = S q c T C s u m = C c o a ∈ R ( l + 1 ) × d S_{qc}^TS_{cq}^TC_{ind} = S_{qc}^TC_{sum} = C_{coa}\in R^{{(l+1)}\times d} SqcTScqTCind=SqcTCsum=Ccoa∈R(l+1)×d S c q T S q c T Q i n d = S c q T Q s u m = Q c o a ∈ R ( m + 1 ) × d S_{cq}^TS_{qc}^TQ_{ind} = S_{cq}^TQ_{sum}=Q_{coa}\in R^{{(m+1)}\times d} ScqTSqcTQind=ScqTQsum=Qcoa∈R(m+1)×d丢弃无用的dummy embedding, C C C、 Q Q Q重新变为 l × d l\times d l×d 和 m × d m\times d m×d维。
- 压缩
B i L S T M ( [ C p r o j , C i n d , C s u m , C c o a ] ) = C c o m ∈ R l × d BiLSTM([C_{proj},C_{ind},C_{sum},C_{coa}]) = C_{com}\in R^{l \times d} BiLSTM([Cproj,Cind,Csum,Ccoa])=Ccom∈Rl×d B i L S T M ( [ Q p r o j , Q i n d , Q s u m , Q c o a ] ) = Q c o m ∈ R m × d BiLSTM([Q_{proj},Q_{ind},Q_{sum},Q_{coa}]) = Q_{com}\in R^{m \times d} BiLSTM([Qproj,Qind,Qsum,Qcoa])=Qcom∈Rm×d - Self Attention
M u l t i H e a d C ( C c o m , C c o m , C c o m ) = C m h a MultiHead_C(C_{com},C_{com},C_{com}) = C_{mha} MultiHeadC(Ccom,Ccom,Ccom)=Cmha M u l t i H e a d Q ( Q c o m , Q c o m , Q c o m ) = Q m h a MultiHead_Q(Q_{com},Q_{com},Q_{com}) = Q_{mha} MultiHeadQ(Qcom,Qcom,Qcom)=Qmha再过一层带Relu的残差前馈神经网络 (不太清楚这里为什么要将C_com与C_mha相加?)
F F N C ( C c o m + C m h a ) = C s e l f FFN_C(C_{com} + C_{mha}) = C_{self} FFNC(Ccom+Cmha)=Cself F F N Q ( Q c o m + Q m h a ) = Q s e l f FFN_Q(Q_{com} + Q_{mha}) = Q_{self} FFNQ(Qcom+Qmha)=Qself
- Final Encoding (BiLSTM)
Decoder
-
Answer Representation
由于答案序列并不会经过CNN、RNN,所以人工加入Positional Encodings附带序列信息。
P E [ t , k ] = s i n ( t / 1000 0 k / 2 d ) o r s i n ( t / 1000 0 ( k − 1 ) / 2 d ) PE[t, k] = sin(t/10000^{k/2d})\ or\ sin(t/10000^{(k-1)/2d}) PE[t,k]=sin(t/10000k/2d) or sin(t/10000(k−1)/2d) A p r o j + P E = A p p r ∈ R n × d A_{proj} + PE = A_{ppr} \in R^{n\times d} Aproj+PE=Appr∈Rn×d -
Attention(略)
-
Multi-Pointer-Generator
这一部分我觉得是整体上最innovative的部分,首先获得答案词语 w i w_i wi出现在context和question的概率分布。(对 文中单词=目标单词 位置的Attention weight求和)
∑ i : c i = w i ( α t C ) i = p c ( w t ) ∈ R l \sum \limits_{i:c_i=w_i}(\alpha_t^C)_i = p_c(w_t)\in R^l i:ci=wi∑(αtC)i=pc(wt)∈Rl ∑ i : q i = w i ( α t Q ) i = p q ( w t ) ∈ R m \sum \limits_{i:q_i=w_i}(\alpha_t^Q)_i = p_q(w_t)\in R^m i:qi=wi∑(αtQ)i=pq(wt)∈Rm
再获得Out-of-context但in-vocabulary的单词概率分布, c ^ t \hat{c}_t c^t是当前时刻的Recurrent context state。
s o f t m a x ( W v c ^ t ) = p v ( w t ) ∈ R v softmax(W_v\hat{c}_t)= p_v(w_t)\in R^v softmax(Wvc^t)=pv(wt)∈Rv
那么我们如何在这三个分布中最后选取一个单词作答案呢?这势必要对这三个分布做整合,本文的方法是将三个分布的missing entries置为0,训练两个权重标量 λ , γ \lambda,\gamma λ,γ 来线性组合成一个 l + m + v l+m+v l+m+v维分布。
γ p v ( w t ) + ( 1 − γ ) [ λ p c ( w t ) + ( 1 − λ ) p q ( w t ) ] = p ( w t ) \gamma p_v(w_t) + (1-\gamma)[\lambda p_c(w_t) + (1-\lambda)p_q(w_t)] = p(w_t) γpv(wt)+(1−γ)[λpc(wt)+(1−λ)pq(wt)]=p(wt)
这两个权重参数的训练也很讲究,一个针对context,一个针对question,(奇怪的是为什么vocabulary分布取决于context?):
σ ( W p v [ c ^ t ; h t ; ( A s e l f ) t − 1 ] = γ ∈ [ 0 , 1 ] \sigma(W_{pv}[\hat{c}_t;h_t;(A_{self})_{t-1}]=\gamma\in[0,1] σ(Wpv[c^t;ht;(Aself)t−1]=γ∈[0,1] σ ( W c q [ q ^ t ; h t ; ( A s e l f ) t − 1 ] = λ ∈ [ 0 , 1 ] \sigma(W_{cq}[\hat{q}_t;h_t;(A_{self})_{t-1}]=\lambda\in[0,1] σ(Wcq[q^t;ht;(Aself)t−1]=λ∈[0,1] -
Loss function
最小化 negative log likelihood
L o s s = − ∑ t T log p ( a t ) Loss = -\sum \limits_t^T \log p(a_t) Loss=−t∑Tlogp(at)
训练
由于是multitask的模型,常常会出现catastrophic forgetting的问题,训练的方法直接决定了模型最终在各个task上的表现。在本文中,作者尝试了三种不同的训练方式:
| Fully Joint | Curriculum | Anti-Curriculum |
|---|---|---|
| 纯 Round Robin | From easy task to difficult task | Phase1:Difficult Tasks Phase2: All the Tasks |
Fully Joint容易理解,就是将所有task按顺序排好,然后按照这个轮回依次抽batch进行训练。事实与直觉相符,这种方法大大增加了模型收敛的难度,模型训练“三心二意”,效果必然不好。
Curriculum Learning的思想源自Bengio大神的文章,其思想是人类学习的知识是通过前人用心编排的,就如同小学生学加减法,初中生算数列几何,大学生学微积分一样,由易到难。如果我们让机器一股脑的学习所有的case,势必会增加其学习难度,而适当的人工编排训练顺序会让模型表现更优。 于是作者利用task的收敛轮数作为区分难易的指标,先训练容易的task,再训练难的。然而,实验后发现结果竟然比fully joint还差!
于是作者自己提出Anti-Curriculum训练方式,打破了前述理论,不再遵循从易到难的顺序,而是将训练分成两个phase:第一个phase先训练一些task给模型一些先验知识;第二个phase再一起训练所有task,相当于一个热启动。这种方式效果很好。

可以看到,Phase1仅有QA的时候decaScore最高达到571.7
然而我们也注意到,phase1加上Machine Translation,Summarization后反而下降了。对此作者总结道:
It is the concordance between the QA nature of the task and SQUAD that enabled improved outcomes and not necessarily the richness of the task!
Including easy tasks early in training makes it more difficult to learn Internal Representation that are useful to other tasks.