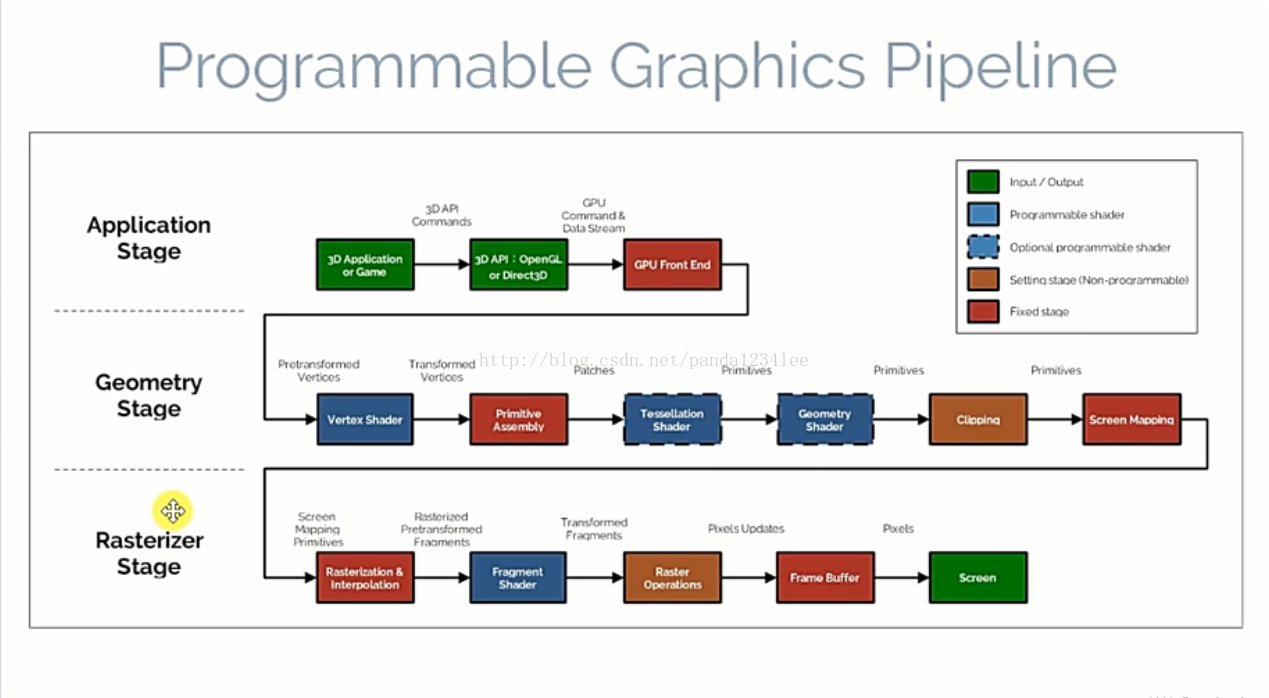
什么是渲染管线
注:
应用程序阶段:主要是CPU与内存打交道,例如碰撞检测,计算好的数据(顶点坐标、法向量、纹理坐标、纹理)就会通过数据总线传给图形硬件 。
几何阶段:其实上图有个问题(网上不少博客也没写清楚这个问题),根据 OpenGL 蓝宝书(Super Bible)上的讲解,“几何图元装配”应该位于“细分着色器”阶段之后(细分着色器处理的还是一个个 Patch),然后再进入“几何着色器”(因为几何着色器处理的基础就是一整个图元)生成新的图元,在该阶段的最后,就是我们熟悉的MVP变换视锥体裁剪操作了。

光栅化阶段:进入光栅化器进行光栅化(还包括剪刀测试、深度测试、模板测试),最后输出到屏幕的 framebuffer 中。
编写 shader 时的一些建议
转自:http://www.cnblogs.com/sifenkesi/p/4716791.html
1、只计算需要计算的东西
尽量减少无用的顶点数据, 比如贴图坐标, 如果有Object使用2组有的使用1组, 那么不 要将他们放在一个vertex buffer中, 这样可以减少传输的数据量;
避免过多的顶点计算,比如过多的光源, 过于复杂的光照计算(复杂的光照模型);
避免 VS 指令数量太多或者分支过多, 尽量减少 VS 的长度和复杂程度;
2、尽量在 VS 中计算
通常,需要渲染的像素比顶点数多,而顶点数又比物体数多很多。所以如果可以,尽量将运算从 FS 移到 VS,或直接通过 script 来设置某些固定值;
3、指令优化【Unity】
在使用 Surface Shader 时,可以通过一些指令让shader优化很多。
通常情况下,Surface shader的很多默认选项都是开启的,以适应大多数情况,但是很多时候,你可以关闭其中的一些选项,从而让你的shader运行的更快:
- approxview 对于使用了 view direction 的shader,该选项会让 view dir 的 normalize 操作 per-vertex 进行,而不是 per-pixel。这个优化通常效果明显。
- halfasview 可以让Specular shader变得快一些,使用一个介于光照方向和观察方向之间的 half vector 来代替真正的观察方向 viewDir 来计算光照函数。
- noforwardadd Forward Rende r时,完全只支持一盏方向光的 per-pixel 渲染,其余的光照全部按照 per-vertex 或 SH 渲染。这样可以确保shader在一个pass里渲染完成。
- noambient 禁掉 ambient lighting 和 SH lighting,可以让 shader 快一点儿。
4、浮点数精度相关:
float:最高精度,通常32位
half:中等精度,通常16位,-60000到60000,
fixed:最低精度,通常11位,-2.0到 2.0,1/256的精度。
尽量使用低精度。对于 color 和 unit length vectors,使用fixed,其他情况,根据取值范围尽量使用 half,实在不够则使用 float 。
在移动平台,关键是在 FS 中尽可能多的使用低精度数据。另外,对于多数移动 GPU,在低精度和高精度之间转换是非常耗的,在 fixed 上做 swizzle 操作也是很费事的。
5、Alpha Test
Alpha test 和 clip() 函数,在不同平台有不同的性能开销。
通常使用它来剔除那些完全透明的像素。
但是,在 iOS 和一些 Android 上使用的 PowerVR GPUs上面,alpha test非常的昂贵。
6、Color Mask
在移动设备上,Color Mask 也是非常昂贵的,所以尽量别使用它,除非真的是需要。
shader 中用for,if等条件语句为什么会使得帧率降低很多?
作者:空明流转
链接:https://www.zhihu.com/question/27084107/answer/39281771
来源:知乎
著作权归作者所有,转载请联系作者获得授权。
1. For和If不一定意味着动态分支
在 GPU 上的分支语句(for,if-else,while),可以分为三类:
Branch 的 Condition 仅依赖编译期常数
此时编译器可以直接摊平分支,或者展开(unloop)。对于For来说,会有个权衡,如果For的次数特别多,或者body内的代码特别长,可能就不展开了,因为会指令装载也是有限或者有耗费的额外成本可以忽略不计;
Branch的 Condition 仅依赖编译期常数和 Uniform 变量
一个运行期固定的跳转语句,可预测同一个 Warp 内所有 micro thread 均执行相同分支额外成本很低;
Branch 的 Condition 是动态的表达式
这才是真正的“动态分支”,会存在一个 Warp 的 Micro Thread 之间各自需要走不同分支的问题
2. 跳转本身的成本非常低
随着IP/EP(Instruction Pointer/Execution Pointer)的引入,现代GPU在执行指令上的行为,和CPU没什么两样。跳转仅仅是重新设置一个寄存器。
3.Micro Thread 走不同分支时的处理
GPU 本身的执行速度快,是因为它一条指令可以处理多个 Micro Thread 的数据(SIMD)。但是这需要多个 Micro Thread 同一时刻的指令是相同的。如果不同,现代 GPU 通常的处理方法是,按照每个 Micro Thread 的不同需求多次执行分支。
x = tex.Load();
if(x == 5)
{// Thread 1 & 2 使用这个路径out.Color = float4(1, 1, 1, 1);
}
else
{// Thread 3 & 4 使用这个路径out.Color = float4(0, 0, 0, 0);
}
比如在上例中,两个分支的语句 Shader Unit 都会执行,只是不同的是如果在执行 if 分支,那么计算结果将不会写入到 thread 3 和 4的存储中(无副作用)。这样做就相当于运算量增加了不少,这是动态分支的主要成本。但是如果所有的线程,都走的是同一分支,那么另外一个分支就不用走了。这个时候 Shader Unit 也不会去傻逼一样的执行另外一个根本不需要执行的分支。此时性能的损失也不多。并且,在实际的 Shader 中,除非特殊情况,大部分 Warp 内的线程,即便在动态分支的情况下,也多半走的是同一分支。
4. 动态分支和代码优化难度有相关性
这一点经常被忽视,就是有动态分支的代码,因为没准你要读写点什么,前后还可能有依赖,往往也难以被优化。比如说你非要闹这样的语句出来:
if(x == 1)
{color = tex1.Load(coord);
}
else if(x == 2)
{color = tex2.Load(coord);
}
...
你说编译器怎么给你优化。
说句题外话,为啥要有 TextureArray 呢?也是为了这个场合。TextureArray 除了纹理不一样,无论格式、大小、坐标、LoD、偏移,都可以是相同的。这样甚至可以预见不同 Texture Surface 上取数据的内存延迟也是非常接近的。这样有很多的操作都可以合并成 SIMD,就比多个 Texture 分别来取快得多了。这就是一个通过增加了约束(纹理格式、大小、寻址坐标)把 SISD 优化成 SIMD 的例子。
定位渲染通道瓶颈的方法
转自:http://blog.csdn.net/rabbit729/article/details/6398343
一般来说, 定位渲染通道瓶颈的方法就是改变渲染通道每个步骤的工作量, 如果吞吐量也改变了, 那个步骤就是瓶颈.。找到了瓶颈就要想办法消除瓶颈, 可以减少该步骤的工作量, 增加其他步骤的工作量。
一般在光栅化之前的瓶颈称作”transform bound”, 三角形设置处理后的瓶颈称作”fill bound”
定位瓶颈的办法:
1. 改变帧缓冲或者渲染目标(Render Target)的颜色深度(16 到 32 位), 如果帧速改变了, 那么瓶颈应该在帧缓冲(RenderTarget)的填充率上。
2. 否则试试改变贴图大小和贴图过滤设置, 如果帧速变了,那么瓶颈应该是在贴图这里。
3. 否则改变分辨率.如果帧速改变了, 那么改变一下pixel shader的指令数量, 如果帧速变了, 那么瓶颈应该就是pixel shader. 否则瓶颈就在光栅化过程中。
4. 否则, 改变顶点格式的大小, 如果帧速改变了, 那么瓶颈应该在显卡带宽上。
5. 如果以上都不是, 那么瓶颈就在CPU这一边。
着色器的最佳实践
转自:OpenGL ES Programming Guide for iOS
在初始化期间编译和链接着色器
与其他 OpenGL ES 状态更改相比,创建着色器程序是一项昂贵的操作。在初始化应用程序时编译、链接和验证程序。一旦创建了所有着色器,应用程序就可以通过调用glUseProgram在它们之间进行有效切换。
调试时检查着色器程序错误
在应用程序构建 Release 的版本时,没有必要在编译或链接着色器程序后读取诊断信息,而且会降低性能。只在应用程序的开发构建中使用 OpenGL ES 函数读取着色器编译或链接日志,如清单10-1所示。
- 清单10-1只在开发构建中读取着色器编译/链接日志
// After calling glCompileShader, glLinkProgram, or similar#ifdef DEBUG
// Check the status of the compile/link
glGetProgramiv(prog, GL_INFO_LOG_LENGTH, &logLen);
if(logLen > 0) {
// Show any errors as appropriate
glGetProgramInfoLog(prog, logLen, &logLen, log);
fprintf(stderr, “Prog Info Log: %s\n”, log);
}
#endif类似地,您应该只在开发构建中调用 glValidateProgram 函数。您可以使用此函数查找开发错误,例如未能绑定着色器程序所需的所有纹理单元。但是,因为验证程序会根据整个 OpenGL ES 上下文状态来检查它,所以这是一个昂贵的操作。由于程序验证的结果只在开发期间有意义,所以不应该在应用程序的发布构建中调用此函数。
使用单独的着色器对象来加速编译和链接
任何使用多个顶点着色器和片段着色器的 OpenGL ES 应用程序,使用不同的顶点着色器重用相同的片段着色器通常很有用,反之亦然。由于核心 OpenGL ES 规范要求在单个着色器程序中链接顶点和片段着色器,混合和匹配着色器会导致大量程序,从而增加了初始化应用程序时着色器编译和链接的总时间。
iOS上的 OpenGL ES 2.0和 3.0上下文支持 EXT_separate_shader_objects 扩展。您可以使用此扩展提供的函数分别编译顶点着色器和片段着色器,并在呈现时使用程序管道对象混合和匹配预编译的着色器阶段。此外,这个扩展提供了一个用于编译和使用着色器的简化接口,如清单10-2 所示。
- 清单10-2 编译并使用单独的着色器对象
- (void)loadShaders
{
const GLchar *vertexSourceText = " ... vertex shader GLSL source code ... ";
const GLchar *fragmentSourceText = " ... fragment shader GLSL source code ... ";// Compile and link the separate vertex shader program, then read its uniform variable locations
_vertexProgram = glCreateShaderProgramvEXT(GL_VERTEX_SHADER, 1, &vertexSourceText);
_uniformModelViewProjectionMatrix = glGetUniformLocation(_vertexProgram, "modelViewProjectionMatrix");
_uniformNormalMatrix = glGetUniformLocation(_vertexProgram, "normalMatrix");// Compile and link the separate fragment shader program (which uses no uniform variables)
_fragmentProgram = glCreateShaderProgramvEXT(GL_FRAGMENT_SHADER, 1, &fragmentSourceText);// Construct a program pipeline object and configure it to use the shaders
glGenProgramPipelinesEXT(1, &_ppo);
glBindProgramPipelineEXT(_ppo);
glUseProgramStagesEXT(_ppo, GL_VERTEX_SHADER_BIT_EXT, _vertexProgram);
glUseProgramStagesEXT(_ppo, GL_FRAGMENT_SHADER_BIT_EXT, _fragmentProgram);
}- (void)glkView:(GLKView *)view drawInRect:(CGRect)rect
{
// Clear the framebuffer
glClearColor(0.65f, 0.65f, 0.65f, 1.0f);
glClear(GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT);// Use the previously constructed program pipeline and set uniform contents in shader programs
glBindProgramPipelineEXT(_ppo);
glProgramUniformMatrix4fvEXT(_vertexProgram, _uniformModelViewProjectionMatrix, 1, 0, _modelViewProjectionMatrix.m);
glProgramUniformMatrix3fvEXT(_vertexProgram, _uniformNormalMatrix, 1, 0, _normalMatrix.m);// Bind a VAO and render its contents
glBindVertexArrayOES(_vertexArray);
glDrawElements(GL_TRIANGLE_STRIP, _indexCount, GL_UNSIGNED_SHORT, 0);
}
敬畏着色器的硬件限制
OpenGL ES 限制了可以在顶点着色器或片段着色器中使用的每种变量类型的数量。OpenGL ES 规范不要求实现在超过这些限制时提供软件回退的方法;相反,着色器只是无法编译或链接。在开发应用程序时,必须确保着色器编译过程中不会发生错误,如清单10-1所示。
使用精度提示
精度提示被添加到 GLSL ES 语言规范中,以解决对紧凑着色器变量的需求,以匹配嵌入式设备的较小硬件限制。每个着色器必须指定一个默认精度;单个着色器变量可能会覆盖此精度,以便向编译器提供关于在应用程序中如何使用该变量的提示。OpenGL ES 实现不强制需要使用提示信息,但可以使用提示信息生成更高效的着色器。GLSL ES规范列出了每个提示的范围和精度。
重要提示:精度提示定义的范围限制没有强制执行。您不能假定您的数据被夹在这个范围内。
按照以下指导:
如果有疑问,默认为高精度。
0.0到1.0范围内的颜色通常可以使用低精度变量表示。
位置数据通常应存储为高精度。
用于照明计算的法线和矢量通常可以存储为中等精度。
降低精度后,重新测试您的应用程序,以确保结果是您所期望的。
举个例子:
precision highp float; // Defines precision for float and float-derived (vector/matrix) types.
uniform lowp sampler2D sampler; // Texture2D() result is lowp.
varying lowp vec4 color;
varying vec2 texCoord; // Uses default highp precision.void main()
{gl_FragColor = color * texture2D(sampler, texCoord);
}
延迟执行向量计算
并不是所有的图形处理器都包括向量处理器;它们可能在标量处理器上执行向量计算。在着色器中执行计算时,请考虑操作的顺序,以确保即使在标量处理器上执行计算,也能有效地执行计算。
如果清单10-4中的代码是在向量处理器上执行的,那么每个乘法将在向量的所有四个组件上并行执行。然而,由于括号的位置,对标量处理器执行相同的操作将需要 8 次乘法,即使其中两个参数是标量值。
- 清单 10-4 向量运算符的不当使用
highp float f0, f1;
highp vec4 v0, v1;
v0 = (v1 * f0) * f1;通过移动括号,可以更有效地执行相同的计算,如清单10-5所示。在本例中,首先将标量值相乘,然后将结果与向量参数相乘;整个运算可以用五次乘法来计算。
- 清单10-5向量操作的正确使用
highp float f0, f1;
highp vec4 v0, v1;
v0 = v1 * (f0 * f1);类似地,如果向量运算不使用结果的所有组件,应用程序应该始终为其指定写掩码。在标量处理器上,可以跳过掩码中未指定组件的计算。清单10-6在标量处理器上以两倍的速度运行,因为它指定只需要两个组件。
- 清单10-6指定了一个写掩码
highp vec4 v0;
highp vec4 v1;
highp vec4 v2;
v2.xz = v0 * v1;
在着色器中使用 Uniform 变量或常量而不是计算值
当一个值可以在着色器之外计算时,将它作为一个统一变量或常量传递到着色器中。在着色器中重新计算动态值可能非常昂贵。
谨慎使用分支指令。
在着色器中不鼓励使用分支,因为它们会降低在3D图形处理器上并行执行操作的能力(尽管在支持OpenGL ES 3.0的设备上这种性能成本会降低)。
如果你完全避免分支,你的应用程序可能会运行得最好。例如,不要创建带有许多条件选项的大型着色器,而是创建专门用于特定呈现任务的较小着色器。在减少着色器中的分支数量和增加创建的着色器数量之间存在权衡。测试不同的选项并选择最快的解决方案。
如果你的着色器必须使用分支,遵循以下建议:
最佳性能:在编译着色器时,在已知的常量上进行分支。
可接受:在统一变量上进行分支。
潜在的差性能:在着色器内部计算的值上进行分支。
消除循环
您可以通过展开循环或使用向量执行操作来消除许多循环。例如,这段代码非常低效:
int i;
float f;
vec4 v;for(i = 0; i < 4; i++)v[i] += f;同样的操作可以直接使用组件添加:
float f;
vec4 v;
v += f;当不能消除循环时,最好循环具有一个常量限制,以避免动态分支。
避免在着色器中计算数组索引
使用着色器中计算的索引比使用常量或均匀数组索引更昂贵。访问统一数组通常比访问临时数组开销小。
注意动态纹理查找
动态纹理查找(也称为依赖纹理读取)发生在片段着色器计算纹理坐标而不是使用传递到着色器的未修改纹理坐标时。在 OpenGL ES 3.0 支持的硬件上,不需要任何性能代价就可以支持依赖的纹理读取;在其他设备上,依赖的纹理读取会延迟 texel 数据的加载,从而降低性能。当着色器没有依赖的纹理读取时,图形硬件可能会在着色器执行之前预取 texel 数据,从而隐藏访问内存的一些延迟。
清单10-7显示了一个片段着色器,它计算新的纹理坐标。本例中的计算可以很容易地在顶点着色器中执行。通过将计算移动到顶点着色器并直接使用顶点着色器的计算纹理坐标,可以避免依赖的纹理读取。
注意:这可能看起来不明显,但是对纹理坐标的任何计算都被认为是一个依赖的纹理读取。例如,将多个纹理坐标集打包到一个 varying 的参数中,并使用 swizzle 命令提取坐标,仍然会导致一个依赖的纹理读取。
- 清单10-7依赖的纹理读取
varying vec2 vTexCoord;
uniform sampler2D textureSampler;void main()
{vec2 modifiedTexCoord = vec2(1.0 - vTexCoord.x, 1.0 - vTexCoord.y);gl_FragColor = texture2D(textureSampler, modifiedTexCoord);
}
为可编程混合获取 Framebuffer 数据
传统的 OpenGL 和 OpenGL ES 实现提供了一个固定的函数混合阶段,如图10-1所示。在发出 draw 调用之前,您要从一组固定的可能参数中指定一个混合操作。在片段着色器输出像素的颜色数据之后,OpenGL ES 混合阶段将读取目标 framebuffer 中相应像素的颜色数据,然后根据指定的混合操作将两者结合起来,生成输出颜色。
图10-1传统的固定函数混合

在 iOS 6.0 或更高版本中,可以使用 EXT_shader_framebuffer_fetch 扩展来实现可编程混合和其他效果。您的片段着色器读取与正在处理的片元对应的目标 framebuffer 中的内容,而不是提供要由 OpenGL ES 混合的源颜色。然后,片段着色器可以使用您选择的任何算法来生成输出颜色,如图10-2所示。
图 10-2 与 framebuffer fetch 可编程混合

这个扩展支持许多高级渲染技术:
额外的混合模式。通过定义自己的 GLSL ES 函数来组合源颜色和目标颜色,可以实现 OpenGL ES 固定函数混合阶段不可能实现的混合模式。例如,清单10-8实现了在流行的图形软件中发现的覆盖和差异混合模式。
后处理的效果。在渲染一个场景之后,您可以使用片段着色器绘制一个全屏 quad,该着色器读取当前片元颜色并将其转换为输出颜色。清单 10-9 中的着色器可以使用这种技术将场景转换为灰度。
Non-color片元操作。framebuffer 可以包含非彩色数据。例如,延迟着色算法使用多个 render targets 来存储深度和法线信息。您的片元着色器可以从一个(或多个) render targets 读取这些数据,并使用它们在另一个 render targets 中生成输出颜色。
这些效果在没有 framebuffer fetch 扩展的情况下是可以实现的——例如,可以通过将场景呈现为纹理来实现灰度转换,然后使用纹理和将 texel 颜色转换为灰度的片元着色器绘制一个全屏 quad。但是,使用这个扩展通常会获得更好的性能。
要启用这个特性,片段着色器必须声明它需要EXT_shader_framebuffer_fetch扩展,如清单10-8和清单10-9所示。实现该特性的着色器代码在OpenGL ES着色语言(GLSL ES)的不同版本之间有所不同。
在 GLSL ES 1.0 中使用 Framebuffer Fetch
对于不使用 #version 300 ES 着色器的 OpenGL ES 2.0 上下文和 OpenGL ES 3.0 上下文,可以使用 gl_FragColor 内置变量来输出片元着色器,使用 gl_LastFragData 内置变量来读取 framebuffer 数据,如清单10-8所示。
- 清单10-8 片段着色器,用于在 GLSL ES 1.0 中进行可编程混合
#extension GL_EXT_shader_framebuffer_fetch : require#define kBlendModeDifference 1
#define kBlendModeOverlay 2
#define BlendOverlay(a, b) ( (b<0.5) ? (2.0*b*a) : (1.0-2.0*(1.0-a)*(1.0-b)) )uniform int blendMode;
varying lowp vec4 sourceColor;void main()
{lowp vec4 destColor = gl_LastFragData[0];if (blendMode == kBlendModeDifference) {gl_FragColor = abs( destColor - sourceColor );} else if (blendMode == kBlendModeOverlay) {gl_FragColor.r = BlendOverlay(sourceColor.r, destColor.r);gl_FragColor.g = BlendOverlay(sourceColor.g, destColor.g);gl_FragColor.b = BlendOverlay(sourceColor.b, destColor.b);gl_FragColor.a = sourceColor.a;} else { // normal blendinggl_FragColor = sourceColor;}
}
在 GLSL ES 3.0 中使用 Framebuffer Fetch
在 GLSL ES 3.0 中,您使用用户定义的变量来声明片元着色器输出的 out 限定符。如果您使用 inout 限定符声明一个片元着色器输出变量,那么当片元着色器执行时,它将包含 framebuffer 数据。清单10-9展示了使用 inout 变量的灰度后处理技术。
- 清单 10-9 用于 GLSL ES 3.0 中颜色后处理的片段着色器
#version 300 es
#extension GL_EXT_shader_framebuffer_fetch : requirelayout(location = 0) inout lowp vec4 destColor;void main()
{lowp float luminance = dot(vec3(0.3, 0.59, 0.11), destColor.rgb);destColor.rgb = vec3(luminance);
}
在顶点着色器中为较大的内存缓冲区使用纹理
在 iOS 7.0及更高版本中,顶点着色器可以从当前绑定的纹理单元中读取数据。使用此技术,您可以在顶点处理期间访问更大的内存缓冲区,从而为一些高级呈现技术提供高性能。例如:
① 位移映射 (Displacement mapping)。绘制一个具有默认顶点位置的网格,然后从顶点着色器中的纹理中读取来更改每个顶点的位置。清单10-10演示了如何使用该技术从灰度高度映射纹理生成三维几何。
② 实例绘制(Instanced drawing)。正如在 “使用实例化绘图来最小化绘图调用” 中所述,实例化绘图在呈现包含许多类似对象的场景时可以显著降低 CPU 开销。然而,为顶点着色器提供每个实例的信息可能是一个挑战。纹理可以为许多实例存储大量信息。例如,您可以通过仅描述一个简单立方体的顶点数据绘制数百个实例来呈现一个巨大的城市景观。对于每个实例,顶点着色器可以使用 gl_InstanceID 变量从纹理中采样,获得一个转换矩阵、颜色变化、纹理坐标偏移量和高度变化,以应用于每个建筑物上。
- 清单10-10顶点着色器,用于从高度映射中呈现
attribute vec2 xzPos;uniform mat4 modelViewProjectionMatrix;
uniform sampler2D heightMap;void main()
{// Use the vertex X and Z values to look up a Y value in the texture.vec4 position = texture2D(heightMap, xzPos);// Put the X and Z values into their places in the position vector.position.xz = xzPos;// Transform the position vector from model to clip space.gl_Position = modelViewProjectionMatrix * position;
}您还可以使用统一数组和统一缓冲对象(在OpenGL es3.0中)向顶点着色器提供大量数据,但是顶点纹理访问提供了几个潜在的优势。您可以在纹理中存储的数据比在统一数组或统一缓冲区对象中存储的数据多得多,并且您可以使用纹理包装和过滤选项(texture wrapping and filtering options)来插值存储在纹理中的数据。此外,您还可以渲染到纹理上,利用GPU生成数据以供稍后的顶点处理阶段使用。
要确定顶点纹理采样在设备上是否可用(以及顶点着色器可用的纹理单元的数量),请检查 MAX_VERTEX_TEXTURE_IMAGE_UNITS 在运行时的限制值。(参见验证OpenGL ES功能。)
其他优化资料:GPU 优化总结