时间序列的聚类方法
时间序列是按照时间排序的一组随机变量,它通常是在相等间隔的时间段内,依照给定的采样率,对某种潜在过程进行观测的结果。
时间序列数据是实值型的序列数据,具有数据量大、数据维度高以及数据是不断更新的等特点。
时间序列聚类方法的分类
什么是聚类?聚类是一种无监督学习方法,聚类就是按照某个特定标准(如距离)把一个数据集分割成不同的类或簇,使类内差异最小,类间差异最大。传统的聚类方法针对静态数据,所谓静态数据就是其特征不随时间变化。
由于时间序列的特征包含随时间变化的值,所以不是静态数据。对于时间序列的聚类来说,有两种思路:
- 一种是修改现有的聚类方法以适用于时间序列
- 一种是将时间序列转换为静态数据,然后在使用现有的聚类方法
前一种思路直接作用于原始数据,称为基于原始数据的方法,难点在于要找到适用于时间序列的距离/相似性度量。
第二种思路首先将原始的时间序列数据转换为低维的特征向量或若干模型参数,称为基于特征的或基于模型的方法。
由于金融交易数据普遍存在信噪比低、非线性、非平稳、非正态的特点,因此直接利用原始数据进行聚类往往效果不好。所以后两种方法是研究的重点。这两种方法都是通过一定的方式将原始时间序列转化为静态的特征或模型参数,然后通过传统的静态数据的聚类方法进行聚类。
基于模型的方法认为相似的时间序列应该产生相似的模型,所以通过比较模型之间的相似性可以达到时间序列聚类的目的。困难在与模型选择和参数确定两个问题。常用的模型:
- ARMA模型
- HMM模型
- 马尔科夫链
基于特征提取的聚类主要应用于高维时间序列,特别是高频金融时间序列,经过特征提取后可有效降维。针对时间序列的数学特性。对时间序列进行特征提取,用提取的特征项对时间序列进行时间序列的重新描述,然后对重新描述的时间序列聚类。

时间序列聚类的步骤
- 数据简化
- 两个时间序列相似性的度量
- 时间序列聚类的通用算法
- 评估聚类结果的标准
数据简化
- DFT 离散傅里叶变换
- DWT 离散小波变换
- SVD 奇异值分解
- PLA 分段线性估计
- PAA 分段聚合近似
- SAX 符号化聚合近似
相似性/距离度量
-
欧氏距离、Minkovski距离

-
Pearson相关系数

-
DTW(Dynamic time warping)
在时间序列中,需要比较相似性的两段时间序列的长度可能并不相等,在语音识别领域表现为不同人的语速不同。在这种情况下,使用传统的欧几里得距离无法有效求解两个时间序列之间的距离。
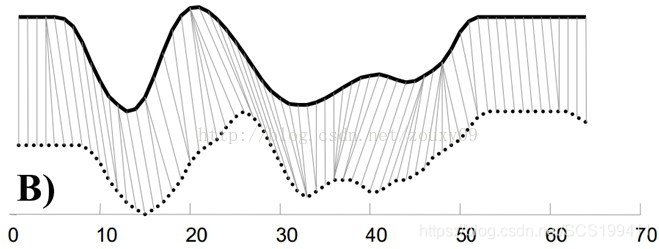
大部分情况下,两个序列整体上具有非常相似的形状,但是这些形状在x轴上并不是对齐的。DTW的思想是把两个时间序列进行wraping,使特征点对齐,直观上理解,就是warping一个序列后可以与另一个序列重合,来得到两个时间序列性的最短距离。

矩阵第(m, n)个元素即是序列P和Q的DTW距离。通常使用一种动态规划的方法来寻找DTW路径,算法的时间复杂度是O(mn),迭代式如下:
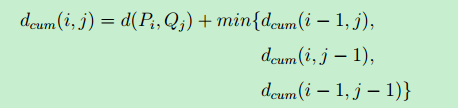
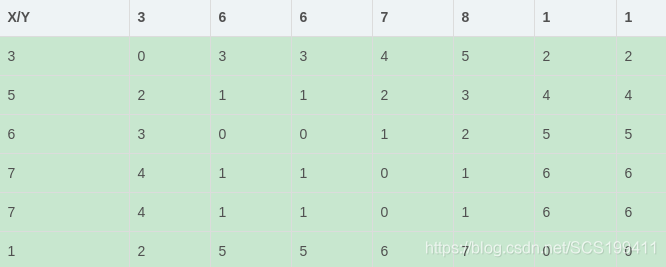
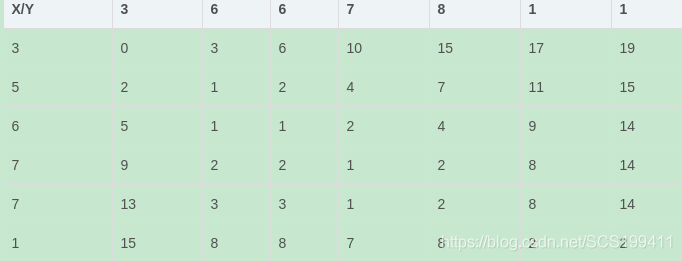
举例来说,给定一个样本序列X和比对序列Y:
- X:3,5,6,7,7,1; Y:3,6,6,7,8,1,1
X/Y距离矩阵
聚类方法
常用于时间序列的聚类算法可以划分为如下几类:
- 划分方法 例如k-means算法:是一种典型的划分聚类算法,它用一个聚类的中心来代表一个簇,即在迭代过程中选择的聚点不一定是聚类中的一个点,该算法只能处理数值型数据
- 层次方法 例如CRUE算法:采用抽样技术先对数据集D随机抽取样本,再采用分区技术对样本进行分区,然后对每个分区局部聚类,最后对局部聚类进行全局聚类
- 基于模型的方法 主要是指基于概率模型的方法和基于神经网络模型的方法,例如SOM神经网络
k-means算法,也被称为k-均值或k-平均。该算法首先随机地选择k个对象作为初始的k个簇的质心;然后对剩余的每个对象,计算其与各个质心的距离,将它赋给最近的簇,然后重新计算每个簇的质心;这个过程不断重复,直到准则函数收敛。通常采用的准则函数为平方误差和准则函数,即SSE(sum of the squared error),其定义如下:
S S E = ∑ i = 1 k ∑ x ∈ C i ∣ ∣ x − μ i ∣ ∣ 2 2 SSE = \sum\limits_{i=1}^k\sum\limits_{x \in C_i} ||x-\mu_i||_2^2 SSE=i=1∑kx∈Ci∑∣∣x−μi∣∣22
k-means算法的具体步骤:
输入是样本集 D = { x 1 , x 2 , . . . x m } D=\{x_1,x_2,...x_m\} D={x1,x2,...xm},聚类的簇数 k k k,最大迭代次数 N N N
输出是簇划分 C = { C 1 , C 2 , . . . C k } C=\{C_1,C_2,...C_k\} C={C1,C2,...Ck}
- 从数据集D中随机选择k个样本作为初始的k个质心向量: { μ 1 , μ 2 , . . . , μ k } \{\mu_1,\mu_2,...,\mu_k\} {μ1,μ2,...,μk}
- 对于 n = 1 , 2 , . . . , N n=1,2,...,N n=1,2,...,N
a) 将簇划分C初始化为 C t = ∅ t = 1 , 2... k C_t = \varnothing \;\; t =1,2...k Ct=∅t=1,2...k
b) 对于i=1,2…m,计算样本 x i x_i xi和各个质心向量 μ j ( j = 1 , 2 , . . . k ) \mu_j(j=1,2,...k) μj(j=1,2,...k)的距离: d i j = ∣ ∣ x i − μ j ∣ ∣ 2 2 d_{ij} = ||x_i - \mu_j||_2^2 dij=∣∣xi−μj∣∣22,将 x i x_i xi标记最小的为 d i j d_{ij} dij所对应的类别 λ i \lambda_i λi。此时更新 C λ i = C λ i ∪ { x i } C_{\lambda_i} = C_{\lambda_i} \cup \{x_i\} Cλi=Cλi∪{xi}
c) 对于j=1,2,…,k,对 C j C_j Cj中所有的样本点重新计算新的质心 μ j = 1 ∣ C j ∣ ∑ x ∈ C j x \mu_j = \frac{1}{|C_j|}\sum\limits_{x \in C_j}x μj=∣Cj∣1x∈Cj∑x
d) 如果所有的k个质心向量都没有发生变化,则转到步骤3) - 输出簇划分 C = { C 1 , C 2 , . . . C k } C=\{C_1,C_2,...C_k\} C={C1,C2,...Ck}
k-means算法的性能分析
主要优点:
- 是解决聚类问题的一种经典算法,简单、快速。
- 对处理大数据集,该算法是相对可伸缩和高效率的。
主要缺点:
- 必须事先给出k值,但很多时候并不知道数据集应该分为多少个类别才最合适。聚类结果对初值敏感,对于不同的初始值,可能会导致不同结果。
- 初始聚类中心的选择对聚类结果有较大的影响,一旦初始值选择的不好,可能无法得到有效的聚类结果。可以多设置一些不同的初值,对比最后的运算结果,一直到结果趋于稳定来解决这一问题,但比较耗时,浪费资源。
- 只能处理等长的时间序列
评估聚类结果的标准
一般来说,在没有数据标签的情况下,对提取的聚类进行评估并不容易,它仍然是一个开放的问题。聚类的定义取决于用户,领域,而且是主观的。 例如,簇的数量,簇的大小,异常值的定义以及问题中时间序列之间相似性的定义都是主观的。
-
有ground truth 将聚类结果与ground truth比较
Rand Index
Mutual Information
Cluster Similarity Measure (CSM)
Cluster purity
Jaccard Score
…… -
无ground truth 用于比较不同聚类方法得到的结果
SSE(均方误差):对每个时间序列来说,就是到最近的集群的距离
Silhouette Coefficient(轮廓系数)
……
参考
Clustering of time series data—a survey
Time-series clustering – A decade review
https://www.cnblogs.com/pinard/p/6164214.html
https://www.jianshu.com/p/7c2640973f01