文章目录
- 市面上的几种数据源比对
- SpringBoot自动装配DataSource原理
- HiKariCP 数据源配置
- Druid 数据源配置
- SpringBoot集成Druid连接池
- Druid 多数据源配置(不同Mapper操作不同数据源)
- HikariCP 多数据源动态配置
springboot2.0整合druid,以及springboot自动装配DataSource原理
市面上的几种数据源比对
常用的数据库连接池: C3P0、DBCP、Druid、HiKariCP
- C3P0: 在16-18年没有更新,19年更新了,但是更新很慢,且历史悠久,代码及其复杂,不利于维护,性能差,不推荐使用。
- DBCP: 更新速度很慢,基本处于不活跃状态,不推荐使用。
- Druid: 阿里开源,功能最为全面,sql拦截等功能,统计数据较为全面,具有良好的扩展性,需要监控sql性能,推荐使用。
- HiKariCP: SpringBoot2默认的数据源,优化力度大,功能简单,起源于boneCP,性能优越,推荐使用。
性能:HiKariCP > Druid > DBCP > C3P0
SpringBoot自动装配DataSource原理
SpringBoot 已经实现了自动加载 DataSource 的相关配置。只需要在项目中引用相关依赖,在配置文件 application.yml 中配置相关属性即可。
自动装配配置类:org.springframework.boot.autoconfigure.jdbc.DataSourceAutoConfiguration。
@Configuration
// 自动配置条件,当给定的类名在类路径上存在,则实例化当前Bean
@ConditionalOnClass({ DataSource.class, EmbeddedDatabaseType.class })
// 开启属性配置类生效,这里生效的是:DataSourceProperties 配置类
@EnableConfigurationProperties(DataSourceProperties.class)
// 引入两个配置类
@Import({ DataSourcePoolMetadataProvidersConfiguration.class,DataSourceInitializationConfiguration.class })
public class DataSourceAutoConfiguration {......@Configuration// 按照条件注册Bean,需实现Condition接口,matches方法返回true@Conditional(PooledDataSourceCondition.class)// 当BeanFactory中不存在 DataSource、XADataSource 类型的 bean@ConditionalOnMissingBean({ DataSource.class, XADataSource.class })// 导入数据源配置类@Import({ DataSourceConfiguration.Hikari.class, DataSourceConfiguration.Tomcat.class,DataSourceConfiguration.Dbcp2.class, DataSourceConfiguration.Generic.class,DataSourceJmxConfiguration.class }) protected static class PooledDataSourceConfiguration {}
在PooledDataSourceConfiguration内部类上有 Tomcat.class 、Hikari.class 、Dbcp2.class 、Generic.class 四个内部类。
每个内部类上都包含有 @ConditionalOnClass(XXX.class) 条件注解,即只有某些特定条件才会创建一个特定的 bean。
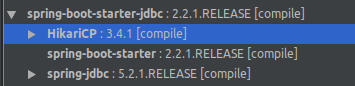
JDBC场景启动器中默认依赖了HikariCP,所以默认只有 HikariCP内部类满足了所有的限定条件。
abstract class DataSourceConfiguration {......// 判断当前 classpath 下是否存在指定类@ConditionalOnClass(HikariDataSource.class)// beanFactory中不存在 DataSource 类型的 bean@ConditionalOnMissingBean(DataSource.class) // spring.datasource.type 属性值默认为 com.zaxxer.hikari.HikariDataSource@ConditionalOnProperty(name = "spring.datasource.type", havingValue = "com.zaxxer.hikari.HikariDataSource", matchIfMissing = true) static class Hikari {@Bean@ConfigurationProperties(prefix = "spring.datasource.hikari")public HikariDataSource dataSource(DataSourceProperties properties) {HikariDataSource dataSource = createDataSource(properties,HikariDataSource.class);if (StringUtils.hasText(properties.getName())) {dataSource.setPoolName(properties.getName());}return dataSource;}}
属性绑定:
通过上面的@EnableConfigurationProperties(DataSourceProperties.class)注解来生效的。
@ConfigurationProperties(prefix = "spring.datasource") 表示通过绑定配置文件中以 spring.datasource 开头的属性到配置类中。
@ConfigurationProperties(prefix = "spring.datasource")
public class DataSourceProperties implements BeanClassLoaderAware, InitializingBean {......
}
总结:
通过上面的分析,最终 DataSourceAutoConfiguration 数据源自动配置将 DataSource 对象注册到 IOC 容器中的,默认的数据源类型 com.zaxxer.hikari.HikariDataSource 。
Spring Boot 2 中已经将默认数据源更改为 Hikari 数据源,之前版本中的默认数据源为 org.apache.tomcat.jdbc.pool.DataSource,主要是因为 Hikari 数据源优异的性能。
HiKariCP 数据源配置
导入依赖:
<dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><!-- 如果数据库服务器是5.7以下版本,驱动建议使用这个版本,如果使用高版本会导致时间问题--><version>5.1.42</version><scope>runtime</scope>
</dependency>
<!-- JDBC场景启动器 -->
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
在全局配置文件中配置 spring.datasource 相关值:
spring.datasource.url=jdbc:mysql://localhost:3306/test?useUnicode=true&useSSL=false&characterEncoding=utf8
spring.datasource.username=root
spring.datasource.password=123456
# JDBC驱动程序的完全限定名称,默认情况下,基于URL自动检测。
spring.datasource.driver-class-name=com.mysql.jdbc.Driver
# 数据源类型,SpringBoot2以后默认HikariDataSource
spring.datasource.type=com.zaxxer.hikari.HikariDataSource
#连接池名称,默认HikariPool-1
spring.datasource.hikari.pool-name=YqHikariPool
#最大连接数,小于等于0会被重置为默认值10;大于零小于1会被重置为minimum-idle的值
spring.datasource.hikari.maximum-pool-size=12
#连接超时时间:毫秒,小于250毫秒,否则被重置为默认值30秒
spring.datasource.hikari.connection-timeout=60000
#最小空闲连接,默认值10,小于0或大于maximum-pool-size,都会重置为maximum-pool-size
spring.datasource.hikari.minimum-idle=10
#空闲连接超时时间:毫秒,默认值600000(10分钟),大于等于max-lifetime且max-lifetime>0,会被重置为0;不等于0且小于10秒,会被重置为10秒。
# 只有空闲连接数大于最大连接数且空闲时间超过该值,才会被释放
spring.datasource.hikari.idle-timeout=540000
#连接最大存活时间:毫秒.不等于0且小于30秒,会被重置为默认值30分钟.设置应该比mysql设置的超时时间短
spring.datasource.hikari.max-lifetime=540000
#连接测试查询
spring.datasource.hikari.connection-test-query=SELECT 1
SpringBoot通过org.springframework.boot.autoconfigure.jdbc.DataSourceAutoConfiguration来实现自动装配数据源。
SpringBoot通过org.springframework.boot.autoconfigure.jdbc.DataSourceProperties定义了数据源相关配置。
SpringBoot2.0以后默认使用的是 class com.zaxxer.hikari.HikariDataSource 数据源。
如果想自定义数据源,比如 DruidDataSource,则可以使用 type 指定:
spring:datasource:type: com.alibaba.druid.pool.DruidDataSource
打印数据源信息:
import org.springframework.beans.BeansException;
import org.springframework.context.ApplicationContext;
import org.springframework.context.ApplicationContextAware;
import org.springframework.stereotype.Component;import javax.sql.DataSource;@Component
// 实现 Spring Bean 生命周期接口 ApplicationContextAware
public class DataSourceShow implements ApplicationContextAware{private ApplicationContext applicationContext = null;// Spring 容器会自动调用这个方法 , 注入 Spring IoC 容器@Overridepublic void setApplicationContext(ApplicationContext applicationContext) throws BeansException {this.applicationContext = applicationContext;// Spring Boot 默认已经配置好了数据源,程序员可以直接 DI 注入然后使用即可DataSource dataSource = this.applicationContext.getBean(DataSource.class);System.out.println("--------------------------------");System.out.println(dataSource.getClass().getName());System.out.println("--------------------------------");}
}
Druid 数据源配置
官方文档:https://github.com/alibaba/druid
1、Druid 是阿里巴巴开源平台上一个数据库连接池实现,结合了 C3P0、DBCP、PROXOOL 等 DB 池的优点,同时加入了日志监控。
2、Druid 可以很好的监控 DB 池连接和 SQL 的执行情况,天生就是针对监控而生的 DB 连接池。
3、druid依赖:
<dependency><groupId>com.alibaba</groupId><artifactId>druid</artifactId><version>1.1.11</version></dependency>
配置参数详解:
com.alibaba.druid.pool.DruidDataSource 基本配置参数如下:
| 配置 | 缺省值 | 说明 |
|---|---|---|
| name | 配置这个属性的意义在于,如果存在多个数据源,监控的时候可以通过名字来区分开来。如果没有配置,将会生成一个名字,格式是:“DataSource-” + System.identityHashCode(this) | |
| jdbcUrl | 连接数据库的url,不同数据库不一样。例如: mysql : jdbc:mysql://10.20.153.104:3306/druid2 oracle : jdbc:oracle:thin:@10.20.149.85:1521:ocnauto | |
| username | 连接数据库的用户名 | |
| password | 连接数据库的密码。如果你不希望密码直接写在配置文件中,可以使用ConfigFilter。详细看这里:https://github.com/alibaba/druid/wiki/%E4%BD%BF%E7%94%A8ConfigFilterhttps://github.com/alibaba/druid/wiki/%E4%BD%BF%E7%94%A8ConfigFilter | |
| driverClassName | 根据url自动识别 这一项可配可不配,如果不配置druid会根据url自动识别dbType,然后选择相应的driverClassName(建议配置下) | |
| initialSize | 0 | 初始化时建立物理连接的个数。初始化发生在显示调用init方法,或者第一次getConnection时 |
| maxActive | 8 | 最大连接池数量 |
| maxIdle | 8 | 已经不再使用,配置了也没效果 |
| minIdle | 最小连接池数量 | |
| maxWait | 获取连接时最大等待时间,单位毫秒。配置了maxWait之后,缺省启用公平锁,并发效率会有所下降,如果需要可以通过配置useUnfairLock属性为true使用非公平锁。 | |
| poolPreparedStatements | false | 是否缓存preparedStatement,也就是PSCache。PSCache对支持游标的数据库性能提升巨大,比如说oracle。在mysql下建议关闭。 |
| maxOpenPreparedStatements | -1 | 要启用PSCache,必须配置大于0,当大于0时,poolPreparedStatements自动触发修改为true。在Druid中,不会存在Oracle下PSCache占用内存过多的问题,可以把这个数值配置大一些,比如说100 |
| validationQuery | 用来检测连接是否有效的sql,要求是一个查询语句。如果validationQuery为null,testOnBorrow、testOnReturn、testWhileIdle都不会其作用。 | |
| testOnBorrow | true | 申请连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能。 |
| testOnReturn | false | 归还连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能 |
| testWhileIdle | false | 建议配置为true,不影响性能,并且保证安全性。申请连接的时候检测,如果空闲时间大于timeBetweenEvictionRunsMillis,执行validationQuery检测连接是否有效。 |
| timeBetweenEvictionRunsMillis | 有两个含义: 1) Destroy线程会检测连接的间隔时间2) testWhileIdle的判断依据,详细看testWhileIdle属性的说明 | |
| numTestsPerEvictionRun | 不再使用,一个DruidDataSource只支持一个EvictionRun | |
| minEvictableIdleTimeMillis | ||
| connectionInitSqls | 物理连接初始化的时候执行的sql | |
| exceptionSorter | 根据dbType自动识别 | 当数据库抛出一些不可恢复的异常时,抛弃连接 |
| filters | 属性类型是字符串,通过别名的方式配置扩展插件,常用的插件有: 监控统计用的filter:stat日志用的filter:log4j防御sql注入的filter:wall | |
| proxyFilters | 类型是List<com.alibaba.druid.filter.Filter>,如果同时配置了filters和proxyFilters,是组合关系,并非替换关系! |
配置 Druid 数据源参数:
1、如同以前 c3p0、dbcp 数据源可以设置数据源连接初始化大小、最大连接数、等待时间、最小连接数 等一样,Druid 数据源同理可以进行设置。
2、Druid 数据源参数配置在全局配置文件中即可:
spring:datasource:# 公共部分对应的是 org.springframework.boot.autoconfigure.jdbc.DataSourceProperties 中的属性url: jdbc:mysql://localhost:3306/test?useUnicode=true&characterEncoding=utf8&characterSetResults=utf8username: rootpassword: 123456# 可以不配置,根据url自动识别,建议配置driver-class-name: com.mysql.jdbc.Drivertype: com.alibaba.druid.pool.DruidDataSource# druid 数据源专有配置# 属性对应的是 com.alibaba.druid.pool.DruidDataSource 中的属性,Spring Boot 默认是不注入不了这些属性值的,需要自己绑定# 初始化连接池个数initialSize: 5# 最小连接池个数——》已经不再使用,配置了也没效果minIdle: 2# 最大连接池个数maxActive: 20# 配置获取连接等待超时的时间,单位毫秒,缺省启用公平锁,并发效率会有所下降maxWait: 60000# 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒timeBetweenEvictionRunsMillis: 60000# 配置一个连接在池中最小生存的时间,单位是毫秒minEvictableIdleTimeMillis: 300000# 用来检测连接是否有效的sql,要求是一个查询语句。# 如果validationQuery为null,testOnBorrow、testOnReturn、testWhileIdle都不会起作用validationQuery: SELECT 1 FROM DUAL# 建议配置为true,不影响性能,并且保证安全性。# 申请连接的时候检测,如果空闲时间大于timeBetweenEvictionRunsMillis,执行validationQuery检测连接是否有效。testWhileIdle: true# 申请连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能testOnBorrow: false# 归还连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能testOnReturn: false# 打开PSCache,并且指定每个连接上PSCache的大小poolPreparedStatements: true# 配置监控统计拦截的filters,通过别名的方式配置扩展插件,多个英文逗号分隔,常用的插件有:# 监控统计;filter:stat# 日志记录;filter:log4j(需导入 log4j 依赖,Maven 地址: https://mvnrepository.com/artifact/log4j/log4j)# 防御sql注入;filter:wallfilters: stat,wall,log4j# 通过connectProperties属性来打开mergeSql功能;慢SQL记录connectionProperties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=5000# 合并多个DruidDataSource的监控数据useGlobalDataSourceStat: truemaxPoolPreparedStatementPerConnectionSize: 20
3、Druid 数据源的专有属性对应的是 com.alibaba.druid.pool.DruidDataSource 中的属性,虽然切换为 Druid 数据源之后,Spring Boot 会自动生成 DruidDataSource 并放入容器中供程序员使用,但是它并不会自动绑定配置文件的参数。
4、所以需要程序员自己为 com.alibaba.druid.pool.DruidDataSource 绑定全局配置文件中的参数,再添加到容器中,而不再使用 Spring Boot 的自动生成了。
配置 Druid 后台管理 Servlet 和 监控 Filter:
1、Druid 数据源具有监控的功能,并提供了一个 web 界面方便用户查看,类似安装 路由器 时,人家也提供了一个默认的 web 页面。
所以需要设置 Druid 的后台管理页面,比如 登录账号、密码 等。
DruidConfig配置类案例:
import com.alibaba.druid.pool.DruidDataSource;
import com.alibaba.druid.support.http.StatViewServlet;
import com.alibaba.druid.support.http.WebStatFilter;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.boot.web.servlet.FilterRegistrationBean;
import org.springframework.boot.web.servlet.ServletRegistrationBean;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;import javax.sql.DataSource;
import java.util.Arrays;
import java.util.HashMap;
import java.util.Map;@Configuration
public class DruidConfig {/*** 添加 DruidDataSource 组件到容器中,并绑定属性:* 将自定义的 Druid 数据源添加到容器中,不再让 Spring Boot 自动创建* 这样做的目的是:绑定全局配置文件中的 druid 数据源属性到 com.alibaba.druid.pool.DruidDataSource* 从而让它们生效* @ConfigurationProperties(prefix = "spring.datasource"):作用就是将 全局配置文件中 前缀为 spring.datasource* 的属性值注入到 com.alibaba.druid.pool.DruidDataSource 的同名参数中*/@ConfigurationProperties(prefix = "spring.datasource")@Beanpublic DataSource druidDataSource() {return new DruidDataSource();}/*** 注册 Druid 监控之管理后台的 Servlet*/@Beanpublic ServletRegistrationBean servletRegistrationBean() {ServletRegistrationBean bean = new ServletRegistrationBean(new StatViewServlet(), "/druid/*");/*** 这些参数可以在 com.alibaba.druid.support.http.StatViewServlet 的父类 com.alibaba.druid.support.http.ResourceServlet 中找到* loginUsername:Druid 后台管理界面的登录账号* loginPassword:Druid 后台管理界面的登录密码* allow:Druid 白名单,后台允许谁可以访问,多个用逗号分割, 如果allow没有配置或者为空,则允许所有访问* initParams.put("allow", "localhost"):表示只有本机可以访问* initParams.put("allow", ""):为空或者为null时,表示允许所有访问* deny:Druid 黑名单,后台拒绝谁访问,多个用逗号分割 (共同存在时,deny优先于allow)* initParams.put("deny", "192.168.1.20");表示禁止此ip访问*/Map<String, String> initParams = new HashMap<>();initParams.put("loginUsername", "admin");initParams.put("loginPassword", "123456");initParams.put("allow", "");/*initParams.put("deny", "192.168.1.20");*//** 设置初始化参数*/bean.setInitParameters(initParams);return bean;}/*** 配置 Druid 监控之 web 监控的 filter* 这个过滤器的作用就是统计 web 应用请求中所有的数据库信息,* 比如 发出的 sql 语句,sql 执行的时间、请求次数、请求的 url 地址、以及seesion 监控、数据库表的访问次数 等等。*/@Beanpublic FilterRegistrationBean filterRegistrationBean() {FilterRegistrationBean bean = new FilterRegistrationBean();bean.setFilter(new WebStatFilter());/** exclusions:设置哪些请求进行过滤排除掉,从而不进行统计*/Map<String, String> initParams = new HashMap<>();initParams.put("exclusions", "*.js,*.gif,*.jpg,*,png,*.css,/druid/*");bean.setInitParameters(initParams);/** "/*" 表示过滤所有请求*/bean.setUrlPatterns(Arrays.asList("/*"));return bean;}}
访问:http://127.0.0.1:8080/druid/login.html
SpringBoot集成Druid连接池
1、在 Spring Boot 项目中加入druid-spring-boot-starter依赖 (点击查询最新版本)
<dependency><groupId>com.alibaba</groupId><artifactId>druid-spring-boot-starter</artifactId><version>1.1.17</version>
</dependency>
2、添加配置
spring:datasource:# 可以不配置,根据url自动识别,建议配置driver-class-name: com.mysql.jdbc.Driverurl: jdbc:mysql://localhost:3306/test?useUnicode=true&characterEncoding=utf8&characterSetResults=utf8username: rootpassword: 123456druid:# 初始化连接池个数initial-size: 5# 最大连接池个数max-active: 20# 最小连接池个数min-idle: 5# 配置获取连接等待超时的时间,单位毫秒,缺省启用公平锁,并发效率会有所下降max-wait: 60000# 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒time-between-eviction-runs-millis: 60000# 配置一个连接在池中最小生存的时间,单位是毫秒min-evictable-idle-time-millis: 300000# 如果validationQuery为null,testOnBorrow、testOnReturn、testWhileIdle都不会起作用validation-query: SELECT 1 FROM DUAL# 建议配置为true,不影响性能,并且保证安全性。# 申请连接的时候检测,如果空闲时间大于timeBetweenEvictionRunsMillis,执行validationQuery检测连接是否有效。test-while-idle: true# 申请连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能test-on-borrow: false# 归还连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能test-on-return: false# 打开PSCache,并且指定每个连接上PSCache的大小pool-prepared-statements: true
Druid 多数据源配置(不同Mapper操作不同数据源)
1、pom 依赖
<dependency><groupId>com.alibaba</groupId><artifactId>druid-spring-boot-starter</artifactId><version>1.1.17</version>
</dependency>
<dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>5.1.28</version><scope>runtime</scope>
</dependency>
2、yml 配置
spring:datasource:type: com.alibaba.druid.pool.DruidDataSourcedriver-class-name: com.mysql.jdbc.Driverdruid:# 初始化连接池个数initial-size: 5# 最大连接池个数max-active: 20# 最小连接池个数min-idle: 5# 配置获取连接等待超时的时间,单位毫秒,缺省启用公平锁,并发效率会有所下降max-wait: 60000# 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒time-between-eviction-runs-millis: 60000# 配置一个连接在池中最小生存的时间,单位是毫秒min-evictable-idle-time-millis: 300000# 如果validationQuery为null,testOnBorrow、testOnReturn、testWhileIdle都不会起作用validation-query: SELECT 1 FROM DUAL# 建议配置为true,不影响性能,并且保证安全性。# 申请连接的时候检测,如果空闲时间大于timeBetweenEvictionRunsMillis,执行validationQuery检测连接是否有效。test-while-idle: true# 申请连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能test-on-borrow: false# 归还连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能test-on-return: false# 打开PSCache,并且指定每个连接上PSCache的大小pool-prepared-statements: trueone:jdbc-url: jdbc:mysql://47.103.82.100:3306/chargepile-v2.0?useUnicode=true&characterEncoding=utf8&zeroDateTimeBehavior=convertToNull&useSSL=true&serverTimezone=GMT%2B8username: rootpassword: GT2021!two:jdbc-url: jdbc:mysql://139.196.127.156:3306/chargepile-v2.0?useUnicode=true&characterEncoding=utf8&zeroDateTimeBehavior=convertToNull&useSSL=true&serverTimezone=GMT%2B8username: rootpassword: GT2021!
3、数据源配置,提供两个 DataSource
import com.alibaba.druid.spring.boot.autoconfigure.DruidDataSourceBuilder;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;import javax.sql.DataSource;@Configuration
public class DataSourceConfig {@Bean@ConfigurationProperties(prefix = "spring.datasource.one")DataSource dsOne() {return DruidDataSourceBuilder.create().build();}@Bean@ConfigurationProperties(prefix = "spring.datasource.two")DataSource dsTwo() {return DruidDataSourceBuilder.create().build();}
}
4、MyBatis配置(两个数据源在两个类中分开来配置)
第一个数据源配置
import org.apache.ibatis.session.SqlSessionFactory;
import org.mybatis.spring.SqlSessionFactoryBean;
import org.mybatis.spring.SqlSessionTemplate;
import org.mybatis.spring.annotation.MapperScan;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.io.support.PathMatchingResourcePatternResolver;import javax.annotation.Resource;
import javax.sql.DataSource;@Configuration
@MapperScan(basePackages = "com.demo.mapper1",sqlSessionFactoryRef = "sqlSessionFactory1",sqlSessionTemplateRef = "sqlSessionTemplate1")
public class MyBatisConfigOne {@Resource(name = "dsOne")DataSource dsOne;@BeanSqlSessionFactory sqlSessionFactory1() {SqlSessionFactory sessionFactory = null;try {SqlSessionFactoryBean bean = new SqlSessionFactoryBean();PathMatchingResourcePatternResolver resolver = new PathMatchingResourcePatternResolver();bean.setDataSource(dsOne);// 每张表对应的xml文件bean.setMapperLocations(resolver.getResources(("classpath:mapper/*Mapper.xml")));// 每一张表对应的实体类bean.setTypeAliasesPackage("com.demo.entity");sessionFactory = bean.getObject();} catch (Exception e) {e.printStackTrace();}return sessionFactory;}@BeanSqlSessionTemplate sqlSessionTemplate1() {return new SqlSessionTemplate(sqlSessionFactory1());}
}
第二个数据源配置
import org.apache.ibatis.session.SqlSessionFactory;
import org.mybatis.spring.SqlSessionFactoryBean;
import org.mybatis.spring.SqlSessionTemplate;
import org.mybatis.spring.annotation.MapperScan;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.io.support.PathMatchingResourcePatternResolver;import javax.annotation.Resource;
import javax.sql.DataSource;@Configuration
@MapperScan(basePackages = "com.demo.mapper2",sqlSessionFactoryRef = "sqlSessionFactory2",sqlSessionTemplateRef = "sqlSessionTemplate2")
public class MyBatisConfigTwo {@Resource(name = "dsTwo")DataSource dsTwo;@BeanSqlSessionFactory sqlSessionFactory2() {SqlSessionFactory sessionFactory = null;try {SqlSessionFactoryBean bean = new SqlSessionFactoryBean();PathMatchingResourcePatternResolver resolver = new PathMatchingResourcePatternResolver();bean.setDataSource(dsTwo);// 每张表对应的xml文件bean.setMapperLocations(resolver.getResources(("classpath:mapper/*Mapper.xml")));// 每一张表对应的实体类bean.setTypeAliasesPackage("com.demo.entity");sessionFactory = bean.getObject();} catch (Exception e) {e.printStackTrace();}return sessionFactory;}@BeanSqlSessionTemplate sqlSessionTemplate2() {return new SqlSessionTemplate(sqlSessionFactory2());}
}
5、mapper 和实体类创建
@Data
public class User {private int id;private String name;
}public interface UserMapperOne {List<User> getAllUser();
}public interface UserMapperTwo {List<User> getAllUser();
}
6、mapper 对应的 XML 配置
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapperPUBLIC "-//mybatis.org//DTD Mapper 3.0//EN""http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.demo.mapper1.UserMapperOne"><select id="getAllUser" resultType="com.demo.entity.User">select * from user;</select>
</mapper>
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapperPUBLIC "-//mybatis.org//DTD Mapper 3.0//EN""http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.demo.mapper2.UserMapperTwo"><select id="getAllUser" resultType="com.demo.entity.User">select * from user;</select>
</mapper>
最后,在Service中注入两个不同的Mapper,不同的Mapper将操作不同的数据源。
HikariCP 多数据源动态配置
1、pom 依赖
<dependencies><dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-boot-starter</artifactId><version>3.4.2</version></dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><!-- 如果数据库服务器是5.7以下版本,驱动建议使用这个版本,如果使用高版本会导致时间问题--><version>5.1.42</version><scope>runtime</scope></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-aop</artifactId></dependency>
</dependencies>
2、yml 配置
spring:datasource:type: com.zaxxer.hikari.util.DriverDataSourcehikari:minimum-idle: 5maximum-pool-size: 20auto-commit: trueidle-timeout: 540000max-lifetime: 540000connection-timeout: 60000connection-test-query: SELECT 1master:driver-class-name: com.mysql.jdbc.Driverjdbc-url: jdbc:mysql://47.103.82.100:3306/chargepile-v2.0?useUnicode=true&characterEncoding=utf8&zeroDateTimeBehavior=convertToNull&useSSL=true&serverTimezone=GMT%2B8username: rootpassword: GT2021!slave:driver-class-name: com.mysql.jdbc.Driverjdbc-url: jdbc:mysql://139.196.127.156:3306/chargepile-v2.0?useUnicode=true&characterEncoding=utf8&zeroDateTimeBehavior=convertToNull&useSSL=true&serverTimezone=GMT%2B8username: rootpassword: GT2021!
3、创建类MybatisPlusConfig,配置注入数据源
import com.baomidou.mybatisplus.core.MybatisConfiguration;
import com.baomidou.mybatisplus.extension.spring.MybatisSqlSessionFactoryBean;
import org.apache.ibatis.session.SqlSessionFactory;
import org.apache.ibatis.type.JdbcType;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.boot.jdbc.DataSourceBuilder;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Primary;
import org.springframework.core.io.support.PathMatchingResourcePatternResolver;import javax.sql.DataSource;
import java.util.HashMap;
import java.util.Map;@Configuration
public class MybatisPlusConfig {/*** 创建 master 数据源** @return dataSource*/@Bean(name = "master")@ConfigurationProperties(prefix = "spring.datasource.master")public DataSource masterDataSource() {return DataSourceBuilder.create().build();}/*** 创建 slave 数据源** @return dataSource*/@Bean(name = "slave")@ConfigurationProperties(prefix = "spring.datasource.slave")public DataSource slaveDataSource() {return DataSourceBuilder.create().build();}/*** 动态数据源配置** @return dataSource*/@Bean@Primarypublic DataSource multipleDataSource(@Qualifier("master") DataSource master,@Qualifier("slave") DataSource slave) {DynamicDataSource dynamicDataSource = new DynamicDataSource();Map<Object, Object> dataSources = new HashMap<>();dataSources.put(DBTypeEnum.MASTER.getValue(), master);dataSources.put(DBTypeEnum.SLAVE.getValue(), slave);dynamicDataSource.setTargetDataSources(dataSources);dynamicDataSource.setDefaultTargetDataSource(master);return dynamicDataSource;}@Bean("sqlSessionFactory")public SqlSessionFactory sqlSessionFactory() throws Exception {// 导入 MybatisSqlSession 配置MybatisSqlSessionFactoryBean sessionFactory = new MybatisSqlSessionFactoryBean();PathMatchingResourcePatternResolver resolver = new PathMatchingResourcePatternResolver();// 设置数据源sessionFactory.setDataSource(multipleDataSource(masterDataSource(), slaveDataSource()));// 实体类别名扫描,多个 package 用逗号或者分号隔开sessionFactory.setTypeAliasesPackage("com.yq.demo.entity");// xml 配置文件位置sessionFactory.setMapperLocations(resolver.getResources(("classpath:/mapper/**.xml")));// 导入 mybatis 配置MybatisConfiguration configuration = new MybatisConfiguration();configuration.setJdbcTypeForNull(JdbcType.NULL);configuration.setMapUnderscoreToCamelCase(true);configuration.setCacheEnabled(false);sessionFactory.setConfiguration(configuration);return sessionFactory.getObject();}
}
4、创建动态数据源的获取类 DynamicDataSource 继承 AbstractRoutingDataSource:
import org.springframework.jdbc.datasource.lookup.AbstractRoutingDataSource;/*** 扩展 Spring 的 AbstractRoutingDataSource 抽象类,实现动态数据源(他的作用就是动态切换数据源)。* AbstractRoutingDataSource 中的抽象方法 determineCurrentLookupKey 是实现数据源的route的核心。* 上下文DbContextHolder为一线程安全的ThreadLocal*/
public class DynamicDataSource extends AbstractRoutingDataSource {/*** 取得当前使用哪个数据源* @return*/@Overrideprotected Object determineCurrentLookupKey() {return DbContextHolder.getDbType();}
}
5、创建获取,设置数据源的类 DbContextHolder,为了线程安全使用了 ThreadLocal:
/*** 设置,获取,清空 当前线程内的数据源变量。*/
public class DbContextHolder {private static final ThreadLocal CONTEXT_HOLDER = new ThreadLocal();/*** 设置数据源** @param dbTypeEnum 数据库类型*/public static void setDbType(DBTypeEnum dbTypeEnum) {CONTEXT_HOLDER.set(dbTypeEnum.getValue());}/*** 取得当前数据源** @return dbType*/public static String getDbType() {return (String) CONTEXT_HOLDER.get();}/*** 清除上下文数据*/public static void clearDbType() {CONTEXT_HOLDER.remove();}
}
/*** 设置数据源*/
public enum DBTypeEnum {/*** 主库*/MASTER("master"),/*** 从库*/SLAVE("slave");private final String value;DBTypeEnum(String value) {this.value = value;}public String getValue() {return value;}
}
6、添加一个 aop 切面类 DataSourceSwitchAspect,这样就可以动态切换数据源了:
import lombok.extern.slf4j.Slf4j;
import org.aspectj.lang.JoinPoint;
import org.aspectj.lang.annotation.Aspect;
import org.aspectj.lang.annotation.Before;
import org.aspectj.lang.annotation.Pointcut;
import org.aspectj.lang.reflect.MethodSignature;
import org.springframework.core.annotation.Order;
import org.springframework.stereotype.Component;import java.util.Objects;/*** AOP方式动态切换数据源 (为了保证AOP在事务注解之前生效,Order的值越小,优先级越高)*/
@Slf4j
@Component
@Aspect
@Order(-100)
public class DataSourceSwitchAspect {@Pointcut("execution(* com.yq.demo.service..*.*(..))")private void dbAspect() {}@Before("dbAspect()")public void db(JoinPoint joinPoint) {MethodSignature methodSignature = (MethodSignature) joinPoint.getSignature();DataSourceSwitch dataSourceSwitch = methodSignature.getMethod().getAnnotation(DataSourceSwitch.class);if (Objects.isNull(dataSourceSwitch)) {DbContextHolder.setDbType(DBTypeEnum.MASTER);} else {dataSourceSwitch.value();switch (dataSourceSwitch.value().getValue()) {case "master":DbContextHolder.setDbType(DBTypeEnum.MASTER);break;case "slave":DbContextHolder.setDbType(DBTypeEnum.SLAVE);break;default:DbContextHolder.setDbType(DBTypeEnum.MASTER);}}}
}
7、添加一个可以供我们用注解形式的调用方式的接口:
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;/*** 多数据源切换*/
@Target({ElementType.METHOD})
@Retention(RetentionPolicy.RUNTIME)
public @interface DataSourceSwitch {/*** 指定数据源,默认主数据源*/DBTypeEnum value() default DBTypeEnum.MASTER;
}
最后测试:
@Service
@AllArgsConstructor
public class TestServiceImpl implements TestService {private TestMapper testMapper;@DataSourceSwitch(DBTypeEnum.SLAVE) // 指定数据源,默认 master@Overridepublic void demo() {}
}