模型简单,本地可跑
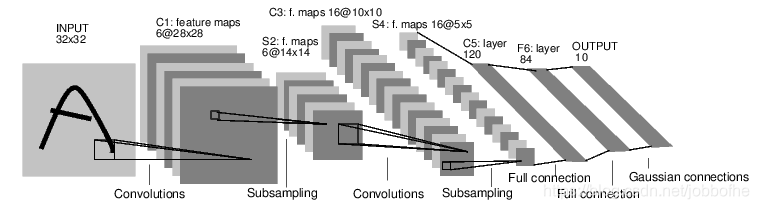
论文参考:Gradient-based learning applied to document recognition
MNIST手写数据集
50000个训练数据
10000个测试数据
图像大小28×28
10类(0-9)
一、python预安装库
pip install torch
pip install torchvision
pip install opencv-python
pip install matplotlib
二、model部分
view 与 reshape 的区别
view:只是修改了读取数据的方式,相当于一个正方体从不同角度去看
reshape:修改了数据在内存中的存储,相当于你直接移动了正方体的朝向
返回值一样,但对应的物理内存不同
import torch
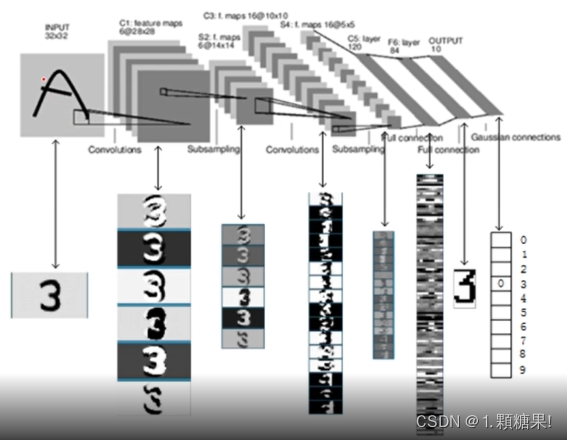
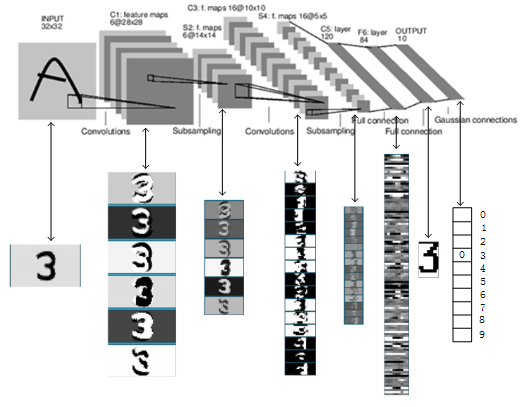
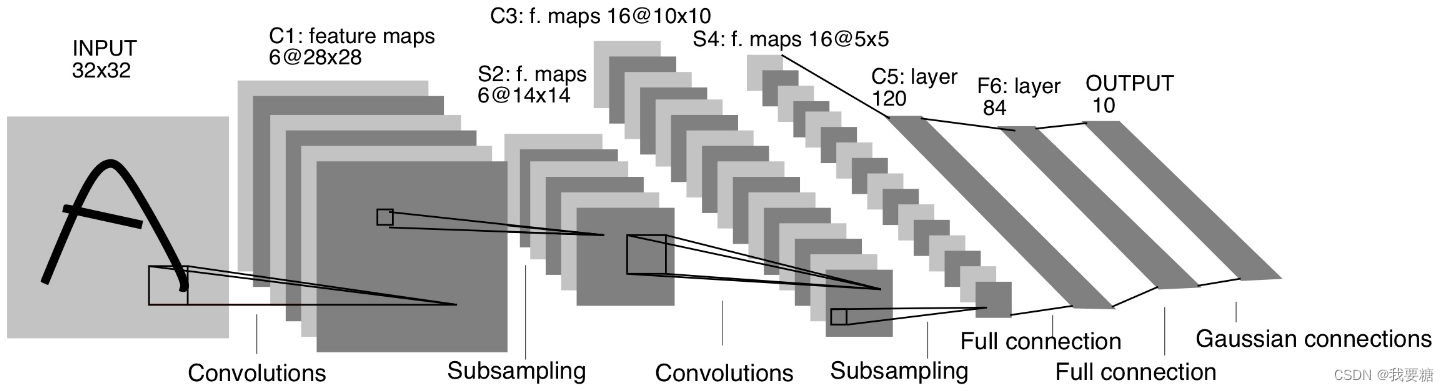
from torch import nnclass Reshape(nn.Module):"""docstring for Reshape"""def forward(self, x):return x.view(-1, 1, 28, 28) #第一维数据不变,后一维数据转化为(1,28,28)# -1 表示自适应,由张量中元素个数和其它维度自动计算并补全该维度class LeNet5(nn.Module):"""docstring for LeNet5"""def __init__(self):super(LeNet5, self).__init__()self.net = nn.Sequential(Reshape(),# CONV1, ReLU1, POOL1nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5, padding=2), #输入1通道(黑白图像),经过5✖5的卷积层,并上下左右用2个元素进行填充,输出通道数为6,得到 6✖28✖28 的输出nn.ReLU(),nn.MaxPool2d(kernel_size=2, stride=2), #核大小为2✖2,步幅为2,得到 6✖14✖14 的输出# CONV2, ReLU2, POOL2nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5), # 得到 16✖10✖10 的输出nn.ReLU(),nn.MaxPool2d(kernel_size=2, stride=2), # 核大小为2✖2,步幅为2,得到 16✖5✖5 的输出nn.Flatten(),# FC1nn.Linear(in_features=400, out_features=120),nn.ReLU(),# FC2nn.Linear(in_features=120, out_features=84),nn.ReLU(),# FC3nn.Linear(in_features=84, out_features=10))def forward(self, x):logits = self.net(x)return logitsif __name__ == '__main__':model = LeNet5()X = torch.rand(size=(256, 1, 28, 28), dtype=torch.float32)for layer in model.net:X = layer(X)print(layer.__class__.__name__, '\toutput: \t', X.shape)
三、训练部分
import torch
from torch import nn
from torchvision import datasets
from torchvision.transforms import ToTensor
from torch.utils.data import DataLoaderfrom model import LeNet5# DATASET
train_data = datasets.MNIST(root = './data',train = False,download=True,transform=ToTensor() # ToTensor() 将 shape 为 (H,W,C) 的 numpy.ndarray 转为 shape 为 (C, H, W) 的 tensor# 并做归一化处理(除以255到[0,1]))test_data = datasets.MNIST(root='./data',train=False,download=True,transform=ToTensor())# PREPROCESS
batch_size = 256
train_dataloader = DataLoader(dataset=train_data, batch_size=batch_size)
test_dataloader = DataLoader(dataset=test_data, batch_size=batch_size)print(len(train_dataloader)) # batch_size 设置为256,可打印输出40个epochfor X, y in train_dataloader:print(X.shape) # torch.Size([256, 1, 28, 28])print(y.shape) # torch.Size([256])break# MODEL
device = 'cuda' if torch.cuda.is_available() else 'cpu' # 选择 device 否则默认 CPU
model = LeNet5().to(device)# TRAIN MODEL
loss_func = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(params=model.parameters())def train(dataloader, model, loss_func, optimizer, epoch):model.train()# 针对 BN(Batch Normalization) 层,保证BN层用每一批数据的均值和方差,针对每个mini-batch# 针对 Dropout 层,随机取一部分网络连接来训练更新参数data_size = len(dataloader.dataset)for batch, (X, y) in enumerate(dataloader):X, y = X.to(device), y.to(device) #将所有数据复制一份到device上y_hat = model(X)loss = loss_func(y_hat, y)optimizer.zero_grad() # 清空过往梯度loss.backward() # 反向传播,计算当前梯度optimizer.step() # 根据梯度更新网络参数if batch == len(dataloader) -1:loss, current = loss.item(), batch * len(X)print(f'EPOCH{epoch+1}\tloss: {loss:>7f}', end='\t')# TEST MODEL
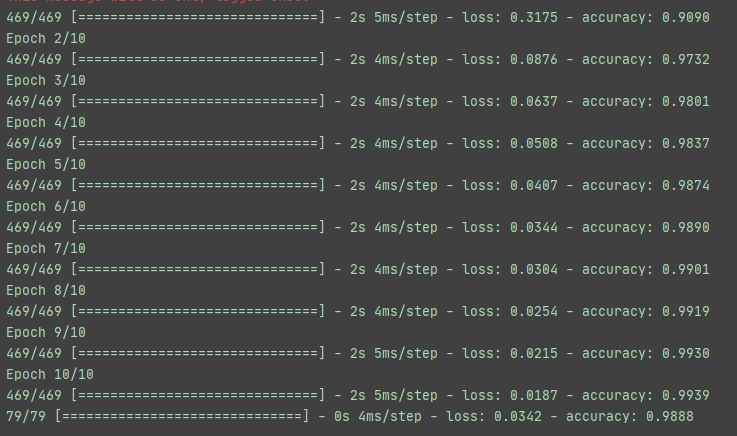
def test(dataloader, model, loss_fn):size = len(dataloader.dataset)num_batches = len(dataloader)model.eval() # 保证 BN 层用全部训练数据的均值和方差,即针对单张图片# 针对 Dropout 层,利用了所有网络连接test_loss, correct = 0, 0with torch.no_grad(): # 所有计算得出的 tensor 的 requires_grad 都自动设置为 false,反向传播便不会自动求导,节约内存for X, y in dataloader:X, y = X.to(device), y.to(device)pred = model(X)test_loss += loss_fn(pred, y).item()correct += (pred.argmax(1) == y).type(torch.float).sum().item()# argmax 取出每一行概率最大的数字的下标test_loss /= num_batchescorrect /= size print(f'Test Error: Accuracy: {(100*correct):>0.1f}%, Average loss: {test_loss:>8f}\n')if __name__ == '__main__':epoches = 40for epoch in range(epoches):train(train_dataloader, model, loss_func, optimizer, epoch)test(test_dataloader, model, loss_func)# save modelstorch.save(model.state_dict(), 'model.pth')print('Saved PyTorch LeNet5 State to model.pth')
四、测试部分
import torch
import cv2 as cv
from model import LeNet5
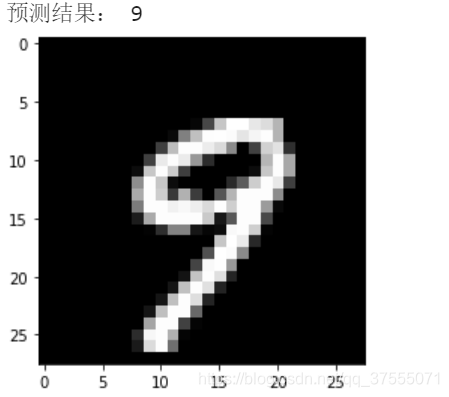
from matplotlib import pyplot as pltif __name__ == '__main__':# Loading modelsmodel = LeNet5()model.load_state_dict(torch.load('./model.pth'))device = 'cuda' if torch.cuda.is_available() else 'cpu'model.to(device)# READ IMAGEimg = cv.imread('./images/2.jpg')gray = cv.cvtColor(img, cv.COLOR_BGR2GRAY)gray = 255 - cv.resize(gray, (28, 28), interpolation=cv.INTER_LINEAR)X = torch.Tensor(gray.reshape(1, 28, 28).tolist())X = X.to(device)with torch.no_grad():pred = model(X)print(pred[0].argmax(0))print(pred)
输出结果为:
tensor(2)
tensor([[-1073.5400, 3579.4260, 6510.0640, 781.4053, -7424.6592, -2042.7059,-3917.9944, -953.5059, 722.2081, -2653.5115]])
五、补充说明
LeNet 最早期的神经网络,先使用卷积层来学习图片空间信息,然后使用全连接层来转换到类别空间。
池化层可用可不用。
第二个卷积层通道数增加到了16,模式变多了,相当于把这些模式给分离开到更多的通道中。
(高宽减半,这时通道数一般翻倍)
为什么用 view 不用 reshape?
view对于数据构造不会发生任何变化,reshape可以做数据的copy。
MLP与CNN对比,MLP速度更快,都能用的话,可以先用MLP。
池化层 Max 和 Avg,max不会损失很多信息,只是数据更大一些,训练更好一些。
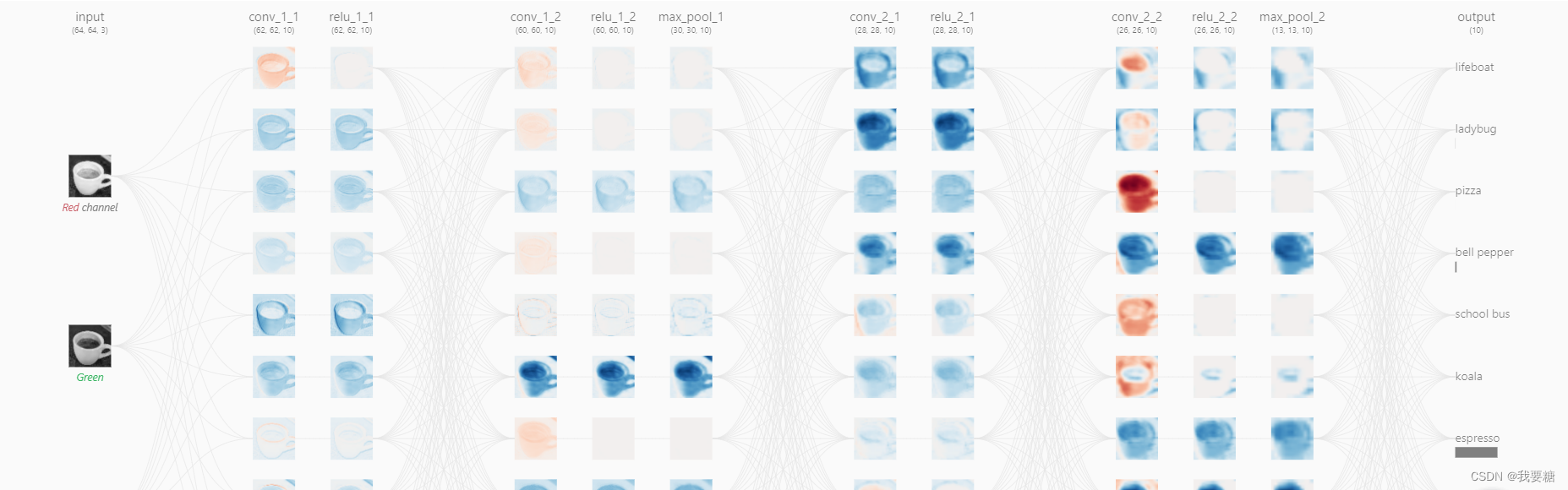
卷积可视化的一个网站,很有趣
cup, car and so on