| 点击此处返回总目录
前面在深度学习介绍的最后有留下一个疑问。我们为什么要deep learning。 我们说,变深了,参数增多,model变复杂,performance变好,是很正常的。 所以,真正要比较一个深度model和一个shallow(浅层) model的时候,你要调整两个model,让他们的参数是一样多的。这样才有说服力。很多人在比较deep 和shallow model 的时候,没有注意到这件事,这样对比是不公平的。你要让两者的参数一样多,这样才公平,这种情况下shallow的model就是一个矮胖的model,deep的model就会是一个高瘦的model。接下来的问题就是,在这个公平的评比之下,shallow比较强还是deep比较强呢? 所以,刚才的实验结果是有后半段的。后半段的实验结果是这样的,用5层,每层2K个神经元得到的error是17.2%。另外,用1层,3772个神经元得到的error是22.5%,为什么是3772个神经元呢?因为这样这两个网络的参数是接近的。我们发现1层的error比较大。 同样,7层每层2K个神经元和1层4634个神经元,他们的参数是接近的。发现1层的也是比较差的。 甚至,增加参数变成1层但是有16K个神经元,error也只是从22.6变到22.1而已。 当用一层非常非常宽的网络(参数多),跟只有2层每层2K个神经元的网络(参数少)相比,效果还不如后者。
在很多人的想象里面,deep learning就是一个暴力碾压的方法,我弄一个很大很大的model,然后collect一大堆的data,所以就得到了一个比较好的performance,它就是一个暴力的方法。实际上,你会发现不是这样子。如果你今天只是单纯地增加参数,你是让网络长宽而不是长高的话,其实对performance的帮助是比较小的。把网络长高对performance很有帮助,把网络长宽帮助没有那么好。
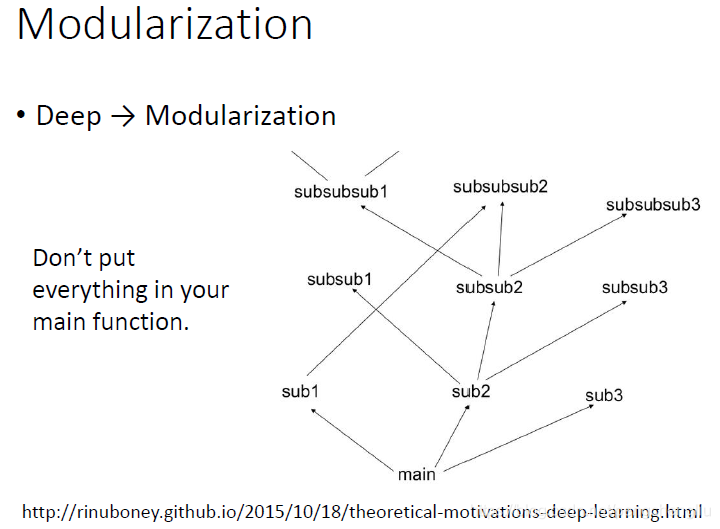
---------------------------------------------------------------------------------------------------------------------------- 为什么会这样呢? 我们可以想象说,当我们在做deep learning的时候,其实我们是在做模块化这件事情。什么意思呢,大家应该都会写程序,写程序的时候不能把所有的代码都写在一个函数里面,而是写一些子函数。然后层层调用。这样做的好处是,有的函数可以共用,不用每次都写,进而减小程序的复杂度。
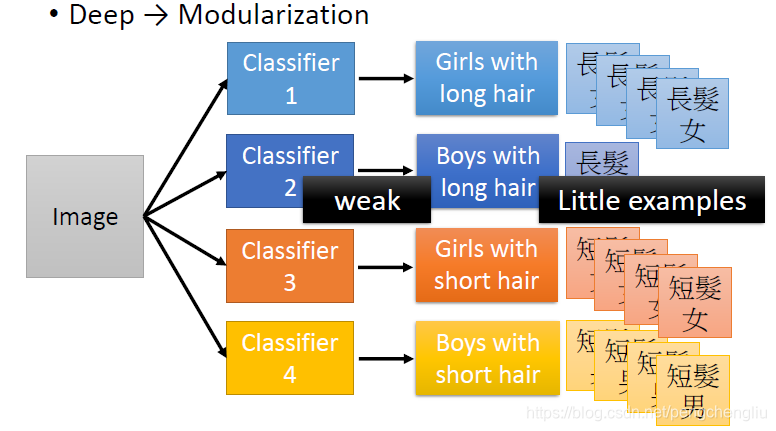
如果用在machine learning上面呢。假设我们要做图像分类。我们要把image分成4类。长发男,长发女,短发男,短发女。然后我们对这四类去收集data,然后去train 4个分类器,然后就可以解决这个问题。但是长发男生的examples可能是比较少的,所以没有太多的training data,所以分类器2就比较弱,它的performance就比较差。
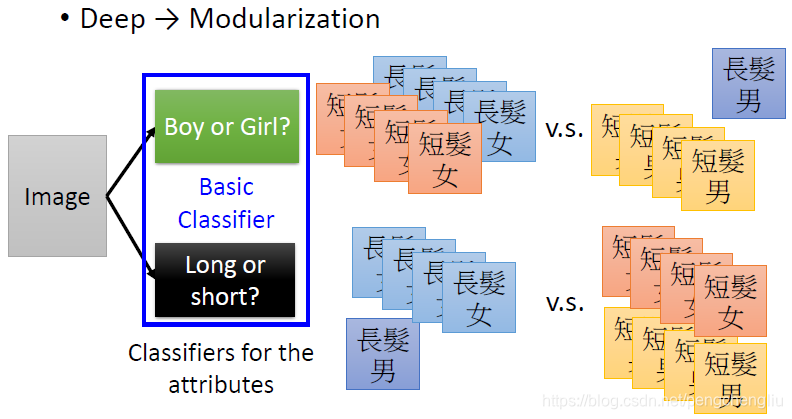
那怎么办呢?你可以用模块化的思想。 假设我们现在不是直接去解那个问题,而是把原来的问题切成比较小的问题,比如我们去learn一些分类器,这个分类器的工作呢,是去detect 有没有一种attribute(属性)出现。比如这里不是这里不是直接detect长发男生还是长发女生,而是把这个问题切成比较小的问题。切成两个问题,输入一张图片判断是长头发还是短头发,输入一张图片判断是男生还是女生。虽然说长头发的男生数量很少,但是男生女生的data可以收集很多。同样长头发和短头发的data也可以收集很多。所以,在train这个basic 分类器的时候,就不会说train的太差。这个分类器都有足够的data。
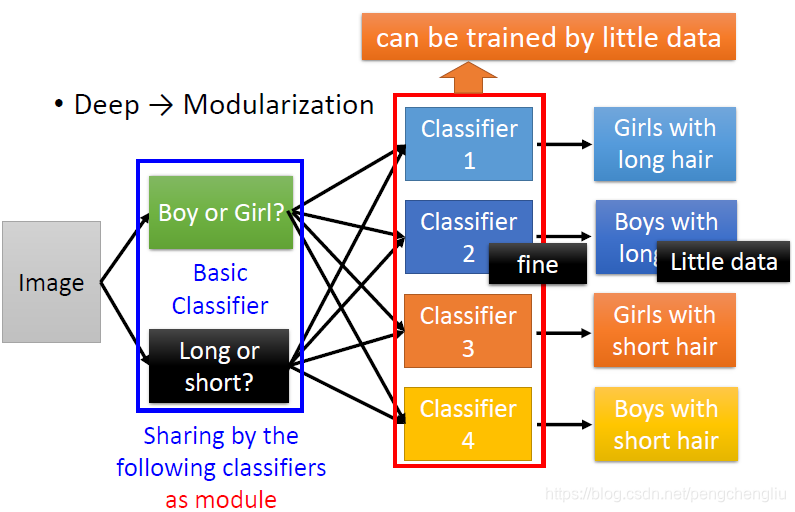
接下来呢,要解最后的问题,四个分类器只需要参考前面的basic 分类器就好了。每一个分类器都公用前面的basic 分类器。后面可以用前面的分类器。后面分类器的参数只需要很少的data就可以train好,因为真正复杂的事都被basic 分类器做了。
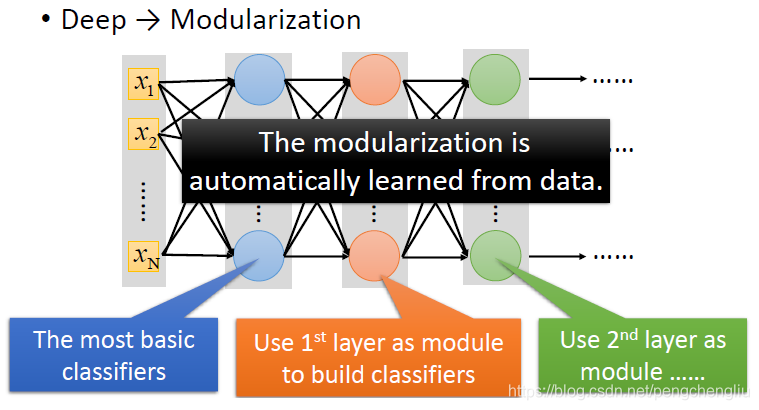
deep learning怎么跟模块化扯上关系呢?每一个神经元就是一个basic的分类器。第一层的是最basic的,第二层的把第一层的当做模块...以此类推。当然要强调的是说,在做deep learning的时候,怎么做模块化这件事情是machine自动学到的。 刚才我们说,模块化的好处是什么?模块化的好处是,让我们的模型变简单了。我们是把本来复杂的问题,变得比较简单。当我们把问题变简单的时候,就算training data没有那么多,我们也可以把这个task做好。如果deep learning做的是模块化的话,那其实,神奇的是,deep learning需要的data是比较少的。 这跟我们的认知是相反的。很多人会说没有big data,deep learning就不会work。其实,并不是这样。如果数据量非常多,比如有全世界的图片,再来做图像分类,就不需要deep learning了。所以deep learning在某种程度上是跟big data是相反的。就是因为没有足够的data,我们才用machine learning去举一反三。
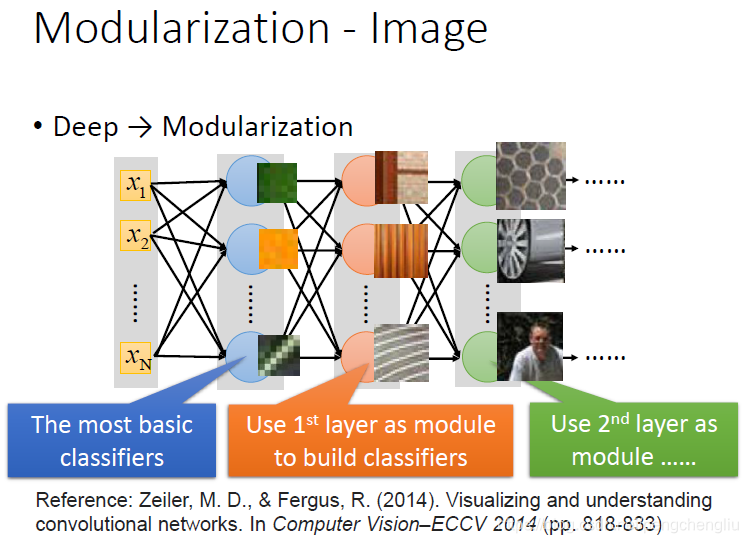
在图像上面,可以观察到类似模块化的现象。
在声音上面,deep learning 也显示模块化的思想。
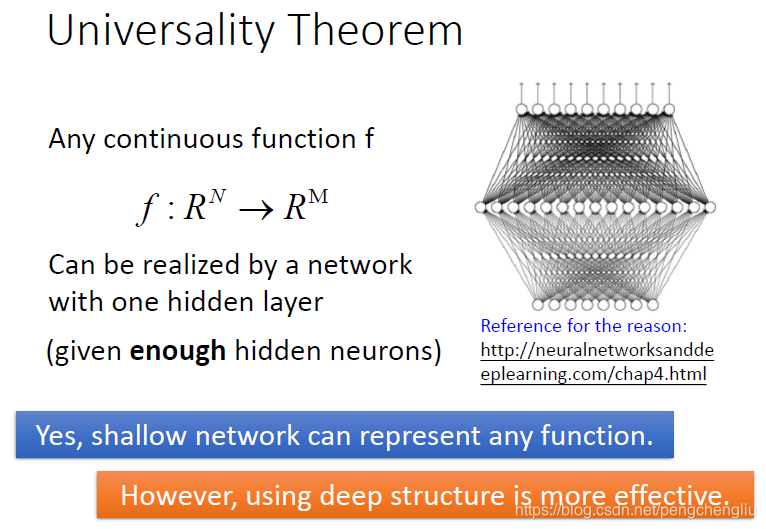
---------------------------------------------------------------------------------------------------------------------------- 我们回到很久以前提到过的University theory。过去有个理论告诉我们说,任何的连续函数f都可以用一层神经网络来完成。只要那一层神经网路够宽的话。这是在90年代很多人放弃做deep learning的一个原因。只要一层隐藏层就可以表示任何的function,那deep learning的意义何在呢?所以很多人说deep 是没有必要的,我们就只要一个隐藏层就好。但是这个理论有个事情没有告诉我们。它只告诉我们可能性,没有告诉我们要做到这件事情有多有效率。 没错,只要有够多的参数,就可以描述任何的function。但是当我们用一个隐藏层来描述function的时候,它是没有效率的。当使用deep structure来描述的时候,是比较有效率的。 ---------------------------------------------------------------------------------------------------------------------------- 如果刚才模块化的概念没有听明白的话,我们举另外一个例子。 学过逻辑电路的可以看一下。就不讲了。
如果没学过的话,还有一个剪窗花的例子。也不讲了。
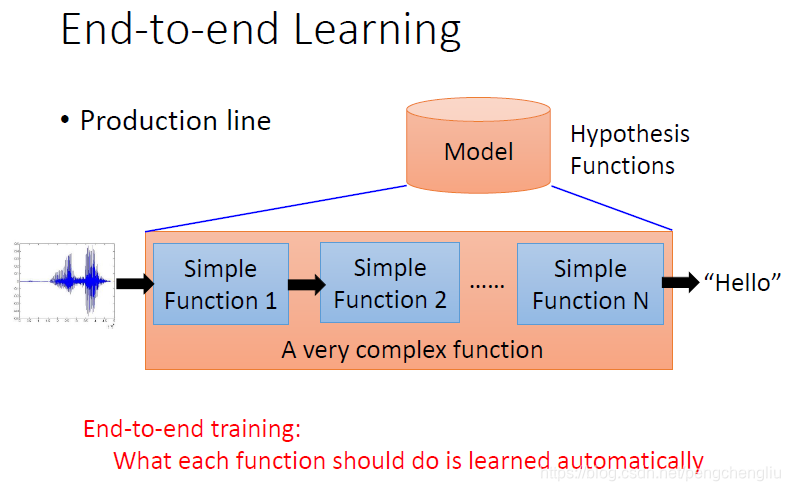
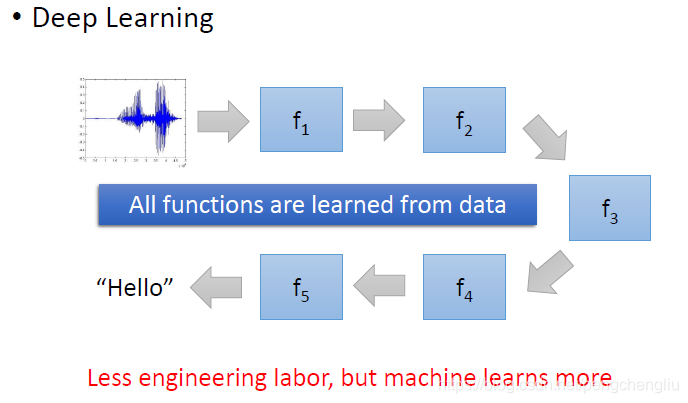
---------------------------------------------------------------------------------------------------------------------------- 当我们用deep learning的时候呢,另外一个好处是,我们可以做end-to-end learning.所谓的end-to-end learning,意思是这样。 比如说我们要处理的问题呢,非常复杂。比如语音识别。我们要解一个machine learning的问题,我们首先要找一个Model。当你要处理的问题很复杂的时候,你的model它会需要是一个生产线。这个model表示一个很复杂的function,是由很多个比较简单的function串叠在一起。比如说要做声音识别,先把声音信号送进来,然后通过很多个function一层一层的转换,最后变成文字。当做end-to-end learning的时候,就是说,只给你的model input和output,不告诉它说中间每一个function要怎么分工,让它自己去学每一个点要做什么事情。在deep learning里,要做这件事情的时候,就是叠一个很深的神经网络,每一层就是生产线上的一个点,就是一个简单的函数,每一层就会自己学到应该做什么事情。
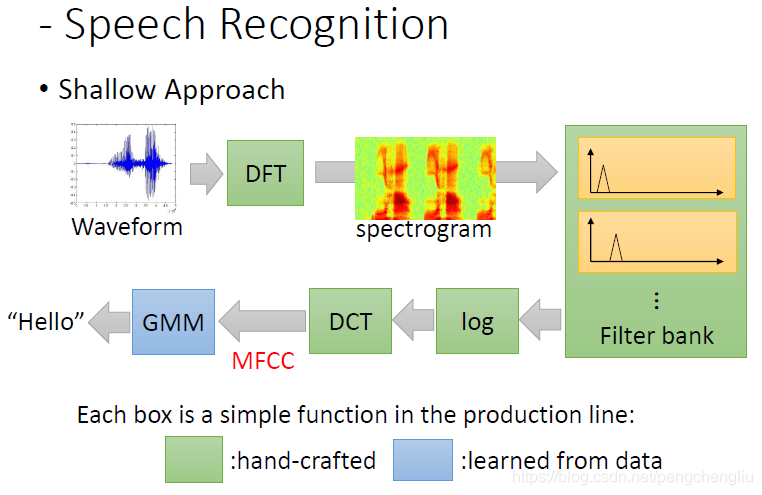
比如说,在声音识别里面,还没有用deep learning 的时候,怎么做呢?现有一段声音信号,然后先做DFT,变成spectrogram,然后再做Filter bank,再取log,然后再做DCT,得到MFCC,再把MFCC丢掉GMM里面,得到结果。在整个生产线上面呢,只有最后的GMM是由training data学出来的,其他的都是手工做的。其他的部分都是古圣先贤花了好几十年研究出来的。
但是有了deep learning以后,我们就可以把手工的这些步骤用神经网络取代掉。比如可以把DCT拿掉,直接从log后面加deep learning。甚至可以从spectrogram开始用深度学习做,把后面的都拿掉。 有人挑战说,能不能叠一个很深很深的网络,直接输入是声音信号,输出是文字,中间完全不用做什么傅里叶变换。如果傅里叶变换都不用做,就可以不用学信号系统了。后来这件事情的结局是这样的,Google拼死learn了一个很大的网络,输入就是声音信号,输出是文字。最后可以做到跟有做傅里叶变换的结果打平。但是也仅仅是打平,这说明傅里叶变换很强,或许它已经是信号处理的极限了,machine learning learn出来的结果,其实也就是傅里叶变换。所以,信号系统还是必要的。
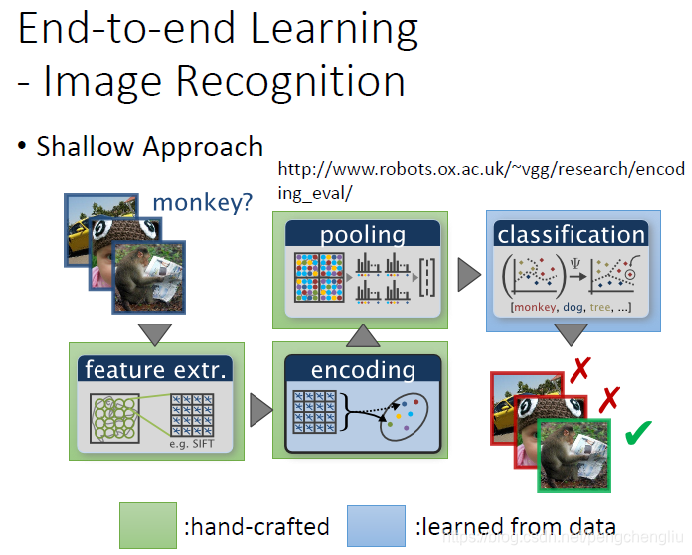
刚才是声音的例子,图像也差不多,就不多说了。过去图像处理也是很多的人工的步骤,但现在也就直接用一个很深的网络,输入是像素,输出是文字。
----------------------------------------------------------------------------------------------------------------------------
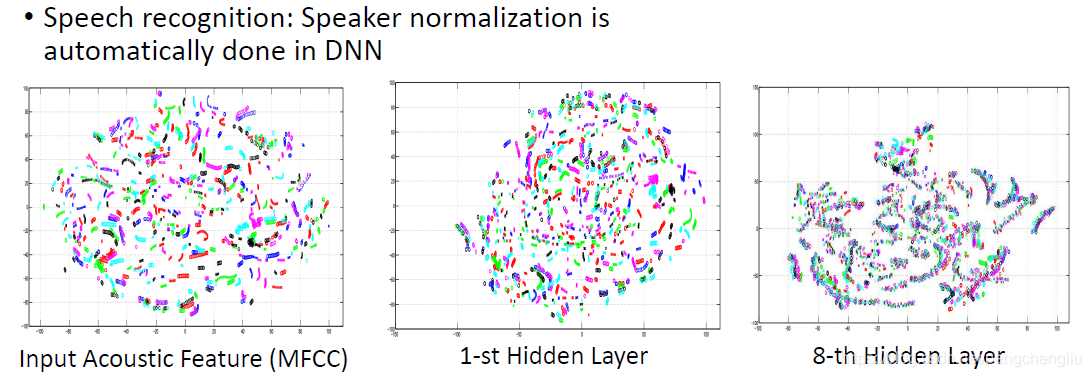
deep learning还有什么好处呢? 通常我们task,是非常复杂的。有时候非常像的input,会有很不一样的output。比如白色的狗和北极熊看起来很像,但是output不一样。有时候非常不一样的东西,看起来是一样的。比如下面两个都是火车。 如果,网络只有一层的话,只能做简单的transform,没有办法把一样的东西变成不一样,没法把不一样的东西变得很像。 要让原来input很不一样的东西变成一样,需要做很多层次的转换。举例来说,看下面的例子。这来自12年的一篇文章。做的事情是,把MFCC投影到二维平面上,不同颜色代表不同人说的话。这些人说的话是一样的。看左图,同样的句子,不同的人说声音信号很不一样。如果今天learn 一个神经网络,只看第一层的hidden layer的output,你会说不同的人说的同一个句子还是很不一样。但是如果看第8个隐藏层的输入的话,会发现不同人说的同一个句子在一起了。也就是说,dnn在转换的时候把本来看起来很不像的东西,就把他们连在一起了。本来很不像,经过8个layer的变换以后,就变得很像了。
刚才是语音的例子,如果用手写数字辨识的例子,输入是这样。如果把28*28的像素投影到二维平面的话,看起来是input这样。你会发现4跟9几乎是叠在一起的。几乎没有办法分开。第一个隐藏层的output,还是很像,没有分的太开。看第二个hidden layer,会发现逐渐分开。第三个分的更开。所以要让本来看的很像的分的很开,也需要好多层才能办到这件事。
----------------------------------------------------------------------------------------------------------------------------
其实还有更多,用deep learning的理由了。比如这个人,第一个PPT是Do deep net really need to be deep?第二页PPT就写了个yes,然后留了很多时间让大家问问题。哈哈
还有一些其他的解释,可以自己去看。
|