目录
1. 设备驱动的作用
2. 有无操作系统时的设备驱动
2.1 无操作系统
2.1.1 硬件、驱动和应用程序的关系
2.1.2 单任务软件典型架构
2.2 有操作系统
2.2.1 硬件、驱动、操作系统和应用软件的关系
3. Linux设备分类
3.1 常规分类法
3.1.1 字符设备
3.1.2 块设备
3.1.3 网络设备
3.2 总线分类法
4. Linux设备驱动在整个软硬件系统中的位置
5. 内核空间与用户空间
5.1 硬件基础
5.2 软件使用
5.3 内核态与用户态
6. GNU C对ANSI C的常见扩展
6.1 零长度数组
6.2 case范围
6.3 语句表达式
6.4 typeof关键字
6.5 可变参数宏
6.6 当前函数名宏
6.7 特殊属性声明__attribute__
6.7.1 noreturn
6.7.2 unused
6.7.3 aligned
6.7.4 packed
6.7.5 section
6.7.6 format
6.8 内建函数
6.8.1 __builtin_constant_p
6.8.2 __builtin_expect
7. 内核编程其他主题
7.1 do {} while(0)
7.2 goto语句的使用
7.3 内核中的并发
7.4 当前进程的获取
7.4.1 before 2.6
7.4.2 from 2.6
7.5 浮点工具链
7.6 其他细节
1. 设备驱动的作用
② 完成设备的轮询、中断处理、DMA通信(CPU与外设通信的方式)
③ 进行物理内存向虚拟内存的映射(在开启硬件MMU的情况下)
2. 有无操作系统时的设备驱动
2.1 无操作系统
2.1.1 硬件、驱动和应用程序的关系
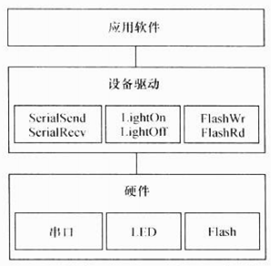
① 驱动包含的接口函数直接与硬件功能吻合,没有任何附加功能(向下)
② 设备驱动的接口被直接提交给应用软件工程师,应用软件直接访问设备驱动的接口(向上)
缺点:设备驱动和应用软件平等,驱动中包含了业务层面的处理,不符合高内聚,低耦合的要求
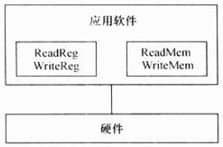
缺点:应用软件直接操作硬件寄存器,不单独设计驱动模块,代码不可复用
2.1.2 单任务软件典型架构
在一个无限循环中夹杂着对设备中断的检测或者对设备的轮询(前后台系统)
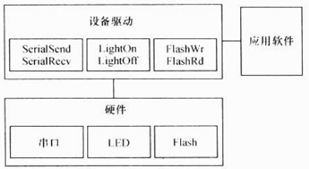
2.2 有操作系统
2.2.1 硬件、驱动、操作系统和应用软件的关系
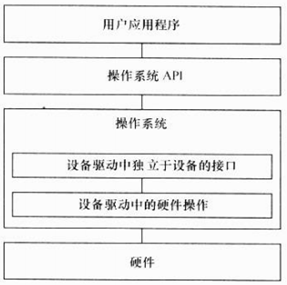
② 将驱动融于内核,需要设计面向操作系统内核的接口,这些接口由操作系统定义(向上)
在有操作系统的情况下,驱动的架构由相应的操作系统定义,必须按照相应的架构设计驱动
由于驱动都按照操作系统给出的独立于设备的接口设计,应用程序可以使用统一的系统调用接口来访问各种设备
e.g. 使用write和read函数可以访问各种字符设备和块设备,而不论设备的具体类型和工作方式
3. Linux设备分类
3.1 常规分类法
3.1.1 字符设备
3.1.2 块设备
说明:块设备以块为最小传输单位,不能按字节处理数据。而Linux则允许块设备传送任意数量的字节,因此块 & 字符设备的区别仅在于内核内部管理数据的方式不同,即内核和驱动之间的软件接口不同
3.1.3 网络设备
说明:与字符 & 块设备一样,网络设备也可以是一个纯粹的软件设备(e.g. 回环网卡)
3.2 总线分类法
示例:I2C驱动 / USB驱动 / PCI驱动 / LCD驱动
这些驱动都可以归入常规分类法的3个基础类别,但由于这些设备比较复杂,Linux为其定义了各自的驱动体系结构(即内核提供了给定类型设备的附加层,我们编写的驱动是和这些附加层一起工作)
所谓给定类型设备的附加层,其实就是内核开发者实现了整个设备类型的共有特性,并提供给驱动程序实现者
e.g. USB设备由USB模块驱动,而USB模块和USB子系统一起工作。但USB设备本身在系统中可以表现为一个字符设备(e.g. USB串口)/ 块设备(e.g. USB读卡器)/ 网络设备(e.g. USB网卡)
4. Linux设备驱动在整个软硬件系统中的位置
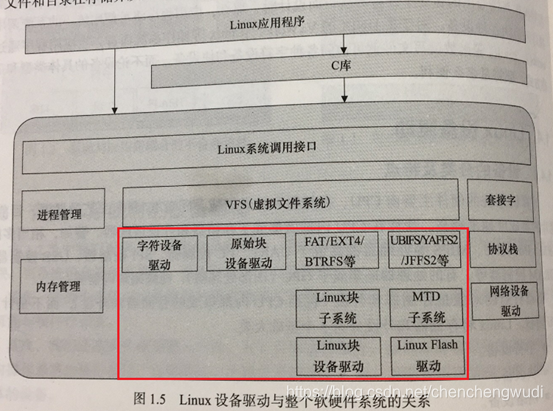
说明1:除网络设备外,字符设备和块设备都被映射为Linux文件系统中的文件,可以通过文件系统的系统调用接口(open / close / read / write)访问
① MTD子系统面向Nor & Nand Flash工作,在其上可建立Yaffs等文件系统
② Linux块子系统面向磁盘 & MMC/SD工作,在其上可建立FAT/EXT等文件系统
5. 内核空间与用户空间
5.1 硬件基础
操作系统能区分为内核空间与用户空间的硬件基础是CPU支持不同的工作模式
ARM:支持usr / fiq / irq / svc / sys / und / abt 七种模式(ARM v6架构)
5.2 软件使用
Linux利用CPU的这一特性实现内核态和用户态,但他只使用两级
X86:内核态(ring 0)、用户态(ring 3) // ring 1 现在被用于实现虚拟化
说明1:ARM Linux的系统调用实现原理是采用swi软中断从用户态切换至内核态
5.3 内核态与用户态
说明:内核态和用户态使用不同的地址空间(即有自己的内存映射),Linux只能通过系统调用和硬件中断从用户空间进入内核空间
① 执行系统调用的内核代码运行在进程上下文中,他代表调用进程执行操作,因此能够访问进程地址空间的所有数据
② 处理硬件中断的内核代码运行在中断上下文中,他和进程是异步的,与任何一个特定进程无关
通常,一个驱动程序模块中的某些函数作为系统调用的一部分,而其他函数负责中断处理
6. GNU C对ANSI C的常见扩展
6.1 零长度数组
struct var_data
{int len;char data[0];
};说明1:由于没有为data数组分配内存,因此sizeof(struct var_data) = sizeof(int)
说明2:char data[0]意味着通过var_data结构体类型变量的data[i]成员可以访问len之后的第i个地址中的内容。
e.g. 假设struct var_data的数据域就保存在struct var_data紧接着的内存区域,那么可以通过如下方式遍历这些数据。
struct var_data s;
...
for (i = 0; i < s.len; ++i) // 此时s.len中保存的就是实际的数据域字节数printf("%x\n", s.data[i]);典型应用场景:定义变长对象的头结构(e.g. 802.11帧头部,由于Information Elements的存在,帧长度可变~~)
补充:其实只有在数据域紧接着struct var_data分配时,零长度数组才有意义

6.2 case范围
switch (ch)
{
case '0'...'9':ch -= '0';break;
case 'a'...'f'ch -= 'a' - 10;break;
case 'A'...'F':ch -= 'A' - 10;break;
}6.3 语句表达式
#definf MIN(x, y) ((x) < (y) ? (x) : (y))这种宏定义方式已经考虑得比较全面,但不能避免调用时的副作用,比如,
int x = 10;
int y = 20;// int z = ((x++) < (y++) ? (x++) : (y++))
// 由于副作用变量错误地累加了2次
int z = MIN(x++, y++);#define MIN(type, x, y) \
({type _x = (x); type _y = (y); _x < _y ? _x : _y})// int z = {int _x=x++; int _y=y++; _x < _y ? _x : _y};
int z = MIN(int, x++, y++);6.4 typeof关键字
typeof(x)可以获得x的类型,借助这个宏,可以重写上面的MIN 宏(内核代码中的实现)
#define MIN(x, y) ({ \
const typeof(x) _x = (x); \
const typeof(y) _y = (y); \
(void) (&_x == &_y); \
_x < _y ? _x : _y})说明:(void)(&_x == &_y) 的作用是判断参与比较的两个值类型是否一致
_x 和_y 的地址值当然不可能相同,但是如果两个变量的类型不同,此处进行地址比较就会使得编译器警告:comparison of distinct pointer types lacks a cast
6.5 可变参数宏
#define pr_debug(fmt, args...) printk(fmt, ##args)说明:pre_debug宏中的args表示其余的参数,可以是零个或多个
pre_debug("%s:%d\n", filename, line);
// 展开为
printk("%s:%d\n", filename, line);使用##是为了处理args参数个数为零个的情况,此时前面的逗号变得多余,使用##后,GNU C处理器会丢弃前面的逗号
pre_debug("success!\n");
// 展开为
printk("success!\n");printk("success!\n",);##的作用是对标记(token)进行连接,在上例中fmt和args均为token。如果token为空,则不进行连接,并且删除掉多余的逗号
此处的关键如何删除掉多余的逗号,作为验证,我们定义如下2个宏,
#define pr_debug_a(fmt, args...) printf(fmt, args)
#define pr_debug_b(fmt, args...) printf(fmt, ##args)// 以如下相同的方式调用上述宏
pr_debug_a("hello");
pr_debug_b("hello");![]()
验证结果在预期之中,不加##号的宏会有多余的逗号,编译时将会失败。下面来验证一下是不是##号将多余的逗号删除的,我们定义如下的宏,
#define test(args...) , ##args// 以如下方式调用上述宏
test();
test("hello");![]()
可见##号在可变参数args为空的情况下,确实可以删除之前多余的逗号;如果args不为空,宏也能正常工作
脑洞验证再进行一步,##号能删除多个逗号吗 ? 我们定义如下的宏
#define test(args...) ,, ##argstest();![]()
那么##号可以删除其他符号吗 ? 经过验证,如果换成其他符号或token,预处理均会失败
#define test(args...) ; ##args // 预处理失败
#define test(args...) a ##args // 预处理失败6.6 当前函数名宏
GNU C中使用宏__FUNCTION__ 保存函数在源代码中的名字,C99中新增了__func__ 宏表示当前函数名。
6.7 特殊属性声明__attribute__
用途:声明函数、变量和类型的特殊属性,以便进行手工的代码优化和定制代码检查的方法
语法:在需要修饰的声明后面添加__attribute__((ATTRIBUTE)),其中ATTRIBUTE为属性说明,如果存在多个属性,以逗号分隔
6.7.1 noreturn
用于函数,表示函数从不返回。编译器可以据此优化代码(e.g. 不为函数返回准备寄存器),并消除不必要的警告信息
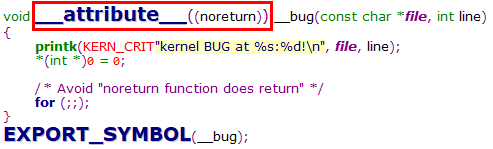
6.7.2 unused
用于函数和变量,表示该函数或变量可能不会被用到,可避免编译器产生的警告
6.7.3 aligned
用于变量、结构体或联合体,指定变量、结构体或联合体的对齐方式,以字节为单位
struct example_struct
{char a;int b;long c;
}__attribute__((aligned(4))); // 以4字节对齐

分析:如果将__attribute__((aligned(n)))作用于一个类型(n必须为2的幂次方),那么该类型变量在分配地址空间时,其存放的地址一定按照n字节对齐;并且其占用的空间也是n的整数倍
从验证结果看,此处按16B对齐是整个结构体的起始地址,并不是结构体中每个成员
6.7.4 packed
用于变量和类型,用于变量或结构体时表示使用最小可能的对齐;用于枚举、结构体或联合体类型是表示该类型使用最小的内存


说明:可见对整个结构体类型使用packed属性后,不再对齐和补齐(但实际编程时不建议使用,因为非对齐的内存访问效率较低)
6.7.5 section
__attribute__((section("section_name")))6.7.6 format
用于函数,表示函数使用printf / scanf风格的参数,指定format属性可以让编译器根据格式串检查参数类型
![]()
该属性说明printk的第1个参数是格式串,从第2个参数开始会根据printf函数的格式串规则检查参数
6.8 内建函数
GNU C提供了大量的内建函数,其中大部分是标准C库函数的GNU C编译器内建版本(如memcpy等),他们与对应的标准C库函数功能相同
不属于库函数的其他内建函数的命名通常以__builtin开始
6.8.1 __builtin_constant_p
__builtin_constant_p(EXP)用于判断一个值是否为编译时常数,如果参数EXP的值是常数该函数返回1,否则返回0

6.8.2 __builtin_expect
__builtin_expect(EXP, C)用于为编译器提供分支预测信息,其返回值是整数表达式EXP的值,C的值必须是编译时常数
由于代码中的分支语句会中断流水线,所以可以使用likely & unlikely宏暗示分支容易成立还是不容易成立
![]()
说明:可以使用-ansi -pedantic编译选项禁用GNU C语法
7. 内核编程其他主题
7.1 do {} while(0)
#define SAFE_FREE(p) do {free(p); p = NULL;} while(0) // 此处没有分号哦~~if (p)SAFE_FREE(p);
else... // do something说明:此时的宏展开不会有问题。如果仅仅使用花括号,仍可能有潜在风险
#define SAFE_FREE(p) {free(p); p = NULL;} if (p)SAFE_FREE(p); // 调用后添加分号,是通常的使用习惯
else... // do somethingif (p){free(p); p = NULL;} ;
else... // do something由于分号的存在,{free(p); p = NULL} ; 表示2 条语句(复合语句 + 空语句),所以else 无法配对,导致编译失败。
问题根源:C 语言中规定语句以分号结束,但有一点例外,就是复合语句是以右花括号结束(})
7.2 goto语句的使用
关键:在错误处理时,注销 / 释放资源的顺序和注册 / 申请资源的顺序相反
if (register_a() != 0)goto err;
if (register_b() != 0)goto err1;
if (register_c() != 0)goto err2;//错误处理书写技巧:从err 写起,逐层向上~~
err2:unregister_b();
err1:unregister_a();
err:
return ret;7.3 内核中的并发
理解关键:内核代码几乎始终不能假定在给定代码段中能够独占CPU
7.4 当前进程的获取
如果当前执行的内核操作由某个进程发起,那么可以通过全局项current来获得当前进程
7.4.1 before 2.6
实现为指向struct task_struct的指针(include/sched.h)
![]()
![]()
补充:虽然before 2.6版本中的current是一个指向task_struct结构的全局变量,但是内核态在获取当前进程时,依然是通过进程内核栈计算得到,下图为Linux 2.4版本的示例

7.4.2 from 2.6
② 为支持SMP,开发了一种能找到运行在相关CPU上的当前进程的机制
③ 实现时不依赖特定架构,将指向task_struct结构的指针隐藏在内核栈中
![]()

说明1:sp变量声明方式
asm("sp"):如果将该变量存储在寄存器中,则使用sp寄存器
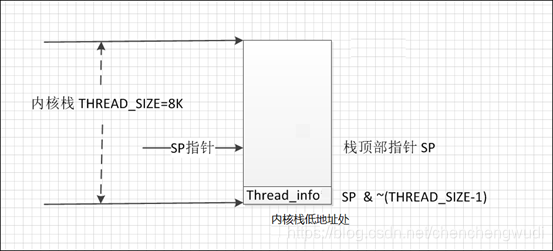
首先看一下内核栈的结构,内核给每个线程分配8KB(THREAD_SIZE)的栈,虽然以联合体的方式存在,但是在栈的低地址处存放的是thread_info

因此内核栈的布局如下图所示,

当内核线程执行到current_thread_info时,其SP堆栈指针指向调用进程所对应的内核线程的栈顶,通过sp & ~(THREAD_SIZE - 1)对齐,就能到达内核栈的低地址处,进而获取thread_info结构的地址
7.5 浮点工具链
② 与软浮点兼容,但是使用FPU硬件:-mfloat-abi=softfp
说明:由于目前主流的ARM芯片都自带VFP或者NEON等浮点处理单元(FPU),所以对硬浮点的需求更加强烈。在工具链前缀中包含"hf"的为支持完全硬浮点的工具链,比如arm-linux-gnueabihf-gcc