目录
1.宽度学习(Broad Learning System)
2.MNIST数据集
3.复刻MNIST数据集的预处理及训练过程
1.宽度学习(Broad Learning System)
对宽度学习的理解可见于这篇博客宽度学习(Broad Learning System)_颹蕭蕭的博客-CSDN博客_宽度学习
这里不再做详细解释
2.MNIST数据集
mnist数据集官网(下载地址):MNIST handwritten digit database, Yann LeCun, Corinna Cortes and Chris Burges
MNIST数据集有称手写体数据集,其中中训练集一共包含了 60,000 张图像和标签,而测试集一共包含了 10,000 张图像和标签。测试集中前5000个来自最初NIST项目的训练集.,后5000个来自最初NIST项目的测试集。前5000个比后5000个要规整,这是因为前5000个数据来自于美国人口普查局的员工,而后5000个来自于大学生。
MNIST数据集自1998年起,被广泛地应用于机器学习和深度学习领域,用来测试算法的效果,相当于该领域的"hello world!"
3.复刻MNIST数据集的预处理及训练过程
原bls代码下载地址:Broad Learning System
下载后,我先用原代码中带的数据和代码进行训练,运行结果如下:
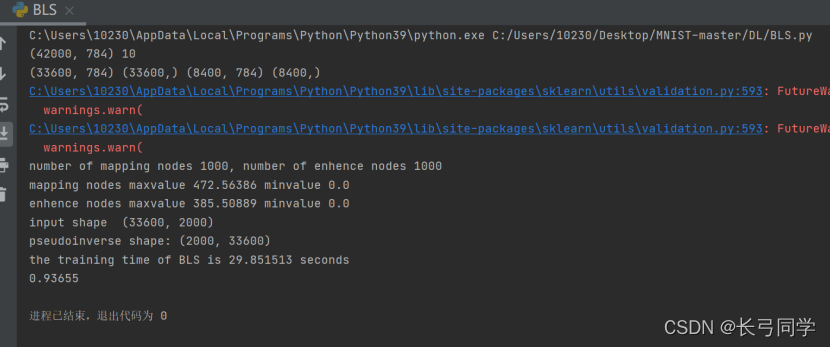
1.不含增量的bls代码:
2.含有增量的bls代码:
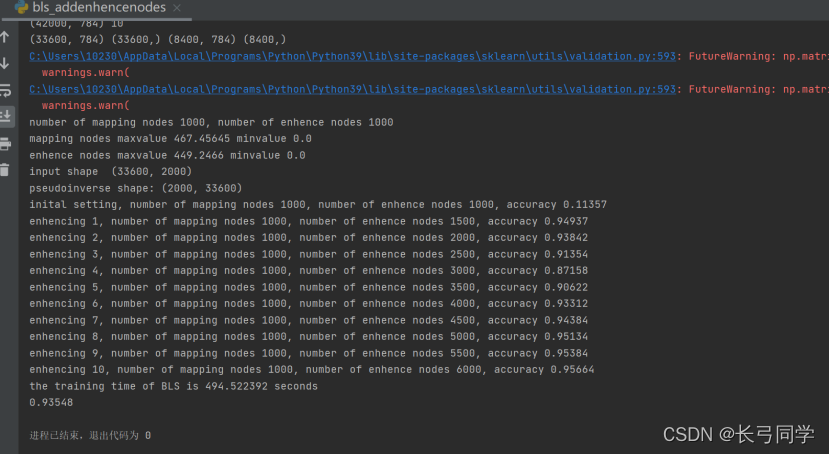
可以看到bls训练模型的时间非常短并且精确度达到0.93以上
然后我们回过头来看它用的训练集和测试集,它共输入三个csv文件,分别为test.csv,train.csv,sample_submission.csv
其中格式为:
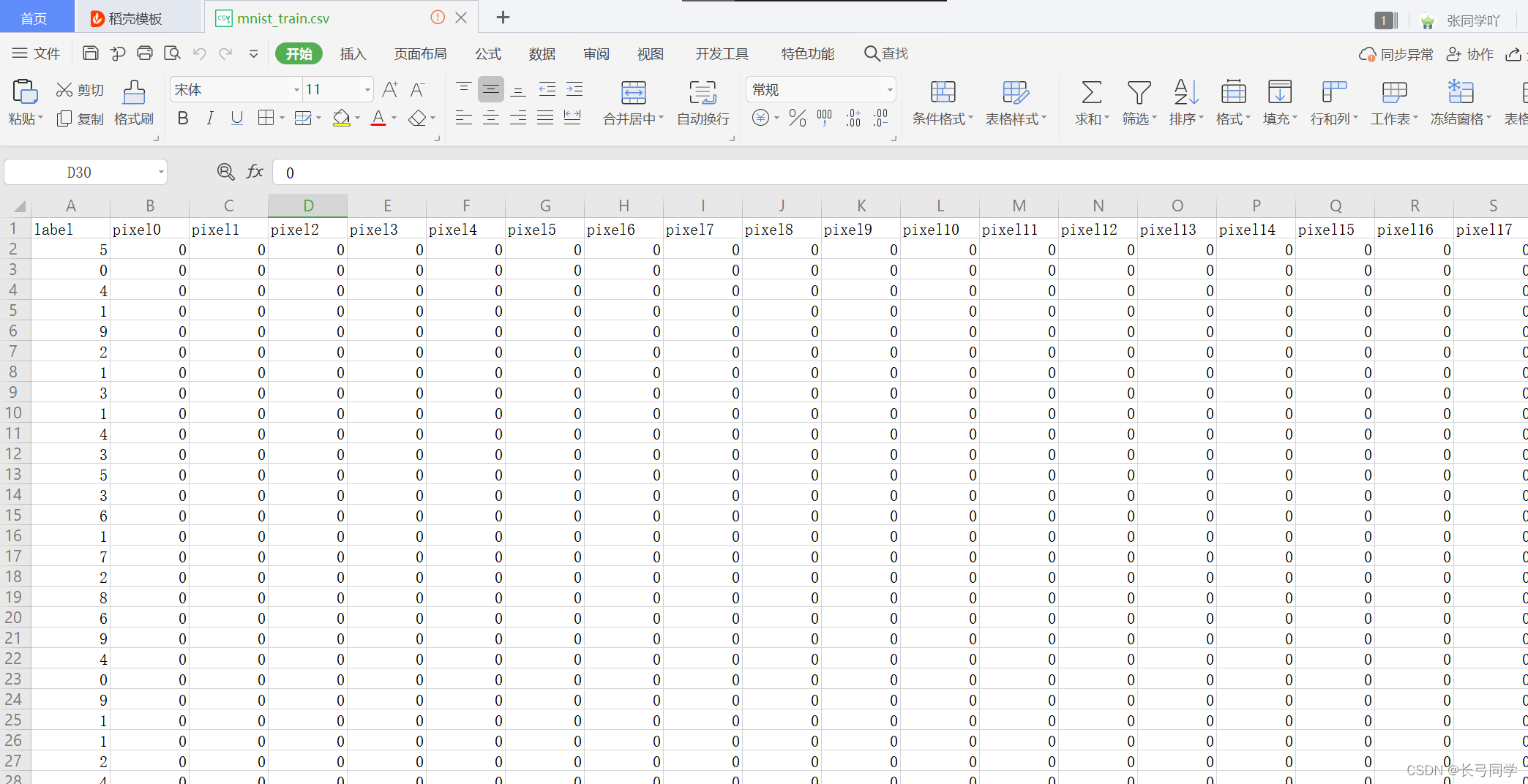
这就是我们处理完MNIST数据之后需要bls代码中训练的数据,统计得到以下信息
| 数据集 | 数据总数 |
| test.csv(测试集) | 28000张 |
| train.csv(训练集) | 42000张 |
其中sample_submission.csv是提交样例,它最后会用来保存训练出的模型对测试集打的标签为csv文件。
那么得到这些信息我们就可以开始处理我们的mnist数据集了,在官网下载完数据集后我们得到了四个文件:
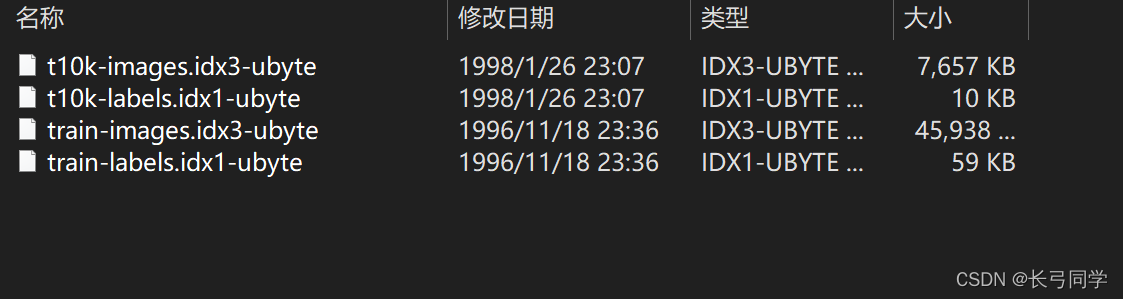
这个时候如果你是初学者,你就会奇怪明明是图像数据为什么下载完会是这四个东西?
这是因为为了方便使用,官方已经将70000张图片处理之后存入了这四个二进制文件中,因此我们要对这四个文件进行解析才能看到原本的图片。
此处用到struct包进行解析,详情见于Mnist数据集简介_查里王的博客-CSDN博客_mnist数据集
解析代码:
import os
import struct
import numpy as np# 读取标签数据集
with open('../data/train-labels.idx1-ubyte', 'rb') as lbpath:labels_magic, labels_num = struct.unpack('>II', lbpath.read(8))labels = np.fromfile(lbpath, dtype=np.uint8)# 读取图片数据集
with open('../data/train-images.idx3-ubyte', 'rb') as imgpath:images_magic, images_num, rows, cols = struct.unpack('>IIII', imgpath.read(16))images = np.fromfile(imgpath, dtype=np.uint8).reshape(images_num, rows * cols)# 打印数据信息
print('labels_magic is {} \n'.format(labels_magic),'labels_num is {} \n'.format(labels_num),'labels is {} \n'.format(labels))print('images_magic is {} \n'.format(images_magic),'images_num is {} \n'.format(images_num),'rows is {} \n'.format(rows),'cols is {} \n'.format(cols),'images is {} \n'.format(images))# 测试取出一张图片和对应标签
import matplotlib.pyplot as pltchoose_num = 1 # 指定一个编号,你可以修改这里
label = labels[choose_num]
image = images[choose_num].reshape(28, 28)plt.imshow(image)
plt.title('the label is : {}'.format(label))
plt.show()运行结果:
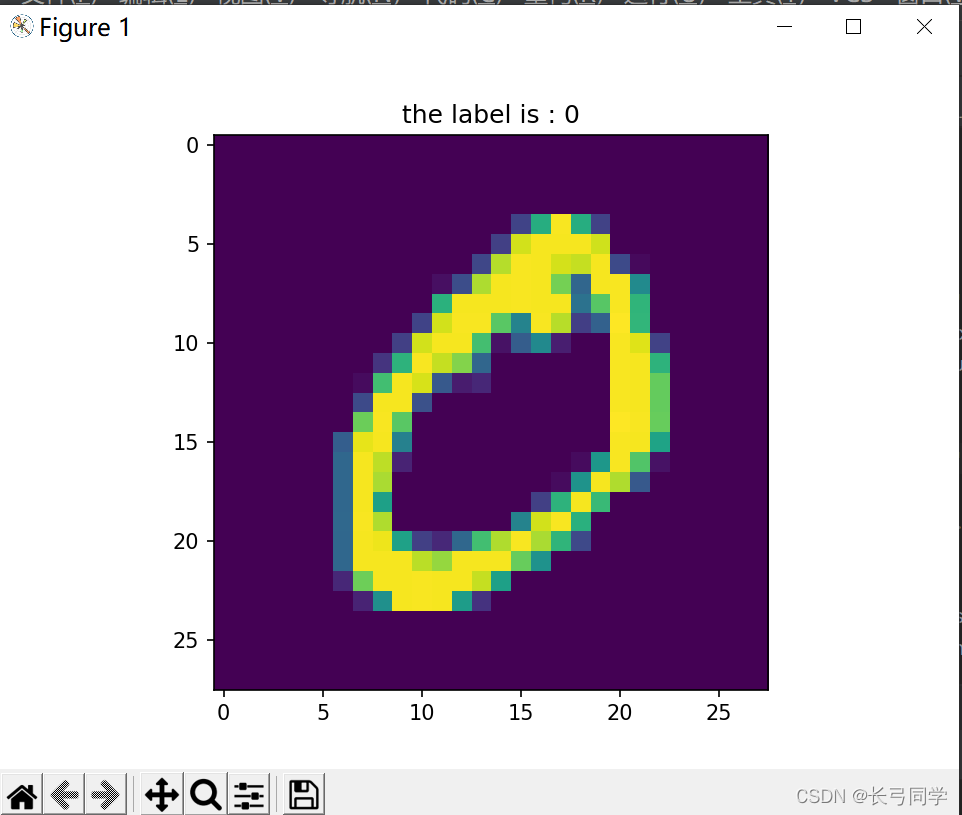
但是这并不是我们要的东西,我们需要的是将二进制文件解析后存入csv文件中用于训练。
在观察了原代码中所用的csv文件的格式以及bls代码中读取数据的方式后,我发现需要再存入之前对数据添加一个index,其中包括"label"和"pixel0~pixel784",其中pixel是一维数组的元素编码,由于mnist数据集是28*28的图片,所以,转为一维数组后一共有784个元素。
知道这个原理后,编写代码如下:
import csvdef pixel(p_array, outf):with open(outf, "w",newline='') as csvfile:writer = csv.writer(csvfile)# 先写入columns_namewriter.writerow(p_array)def convert(imgf, labelf, outf, n):f = open(imgf, "rb")o = open(outf, "a")l = open(labelf, "rb")f.read(16)l.read(8)images = []for i in range(n):image = [ord(l.read(1))]for j in range(28*28):image.append(ord(f.read(1)))images.append(image)for image in images:o.write(",".join(str(pix) for pix in image)+"\n")f.close()o.close()l.close()if __name__ == '__main__':p_array = []for j in range(0, 785):if j == 0 :b1 = "label"p_array.append(b1)else:b1 = 'pixel' + str(j - 1)p_array.append(b1)pixel(p_array,"../data/mnist_train.csv")pixel(p_array,"../data/mnist_test.csv")convert("../data/train-images.idx3-ubyte", "../data/train-labels.idx1-ubyte","../data/mnist_train2.csv", 42000)convert("../data/t10k-images.idx3-ubyte", "../data/t10k-labels.idx1-ubyte","../data/mnist_test2.csv", 28000)print("success!")代码运行结果;
得到经过二进制文件解析以及格式处理后的数据:
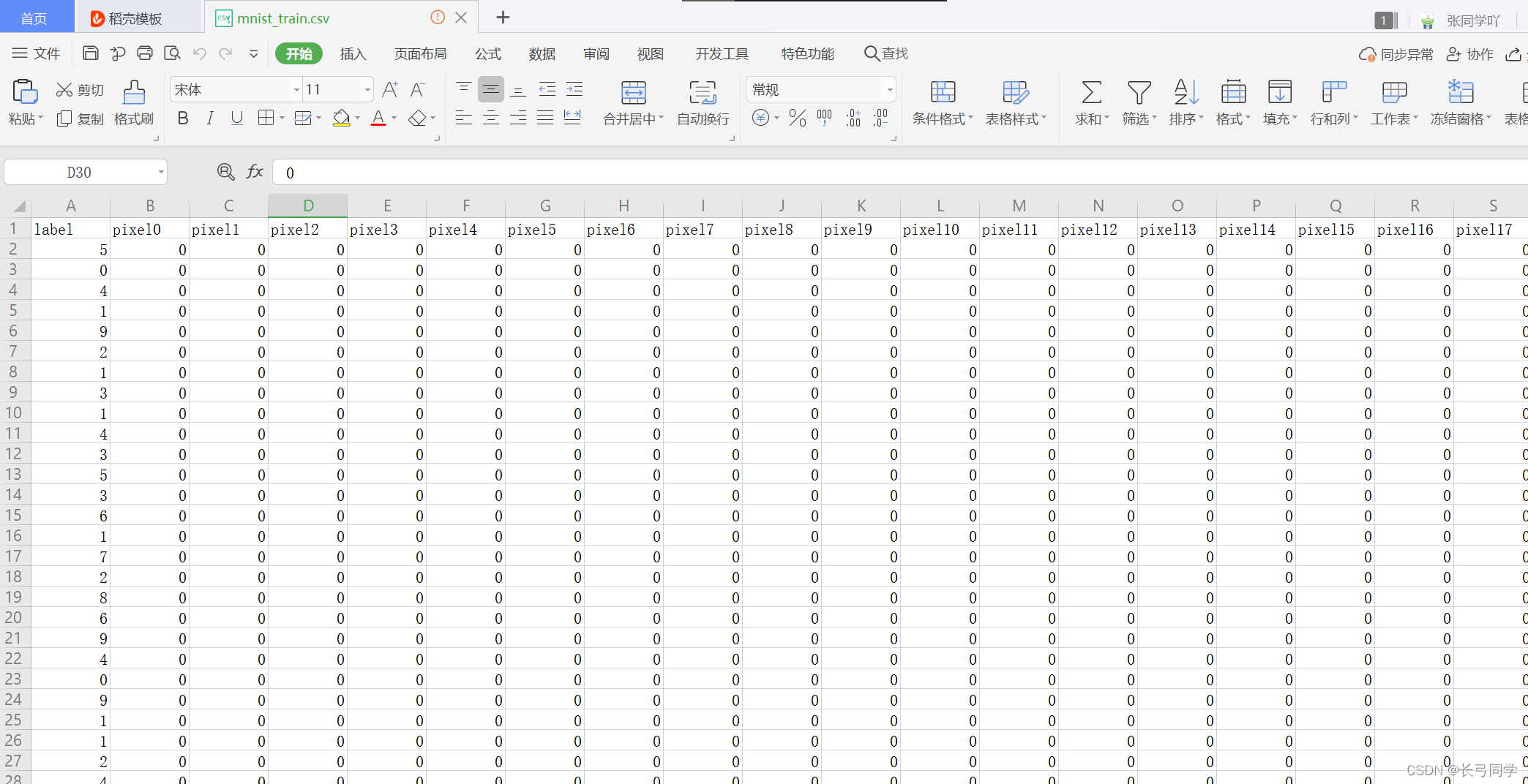
现在训练集文件格式与源代码格式一样了,但是,既然是复刻那么我们还有一个问题没有解决——数据总数不一样,根据源代码中信息,训练集有42000张,测试集28000张,但是我们的训练集有60000张,测试集有10000张,所以我们需要稍微处理一下我们数量,其实这个很简单,只要将训练集中的数据匀18000张给测试集就可以了,另外测试集中标签一行需要删除,因为测试集好比高考试卷,标签相当于答案,没有人会把高考答案告诉你然后让你考对不对。这个过程可以用python代码实现,只要加入一点点功能,编写功能代码如下:
(记得删除测试集中的标签)
import csv
def test_add(train_imgf,train_labelf,outf):f = open(train_imgf, "rb")o = open(outf, "a")l = open(train_labelf, "rb")f.read(16)l.read(8)images = []for i in range(42001, 60001):image = [ord(l.read(1))]for j in range(28 * 28):image.append(ord(f.read(1)))images.append(image)for image in images:o.write(",".join(str(pix) for pix in image) + "\n")f.close()o.close()l.close()def pixel(p_array, outf):with open(outf, "w",newline='') as csvfile:writer = csv.writer(csvfile)# 先写入columns_namewriter.writerow(p_array)def convert(imgf, labelf, outf, n):f = open(imgf, "rb")o = open(outf, "a")l = open(labelf, "rb")f.read(16)l.read(8)images = []for i in range(n):image = [ord(l.read(1))]for j in range(28*28):image.append(ord(f.read(1)))images.append(image)for image in images:o.write(",".join(str(pix) for pix in image)+"\n")f.close()o.close()l.close()if __name__ == '__main__':p_array = []for j in range(0, 785):if j == 0 :b1 = "label"p_array.append(b1)else:b1 = 'pixel' + str(j - 1)p_array.append(b1)pixel(p_array,"../data/mnist_train2.csv")pixel(p_array,"../data/mnist_test2.csv")convert("../data/train-images.idx3-ubyte", "../data/train-labels.idx1-ubyte","../data/mnist_train2.csv", 42000)convert("../data/t10k-images.idx3-ubyte", "../data/t10k-labels.idx1-ubyte","../data/mnist_test2.csv", 10000)test_add("../data/train-images.idx3-ubyte", "../data/train-labels.idx1-ubyte", "../data/mnist_test2.csv")print("success!")处理后,与提交案例一起加入bls训练,可以得到:
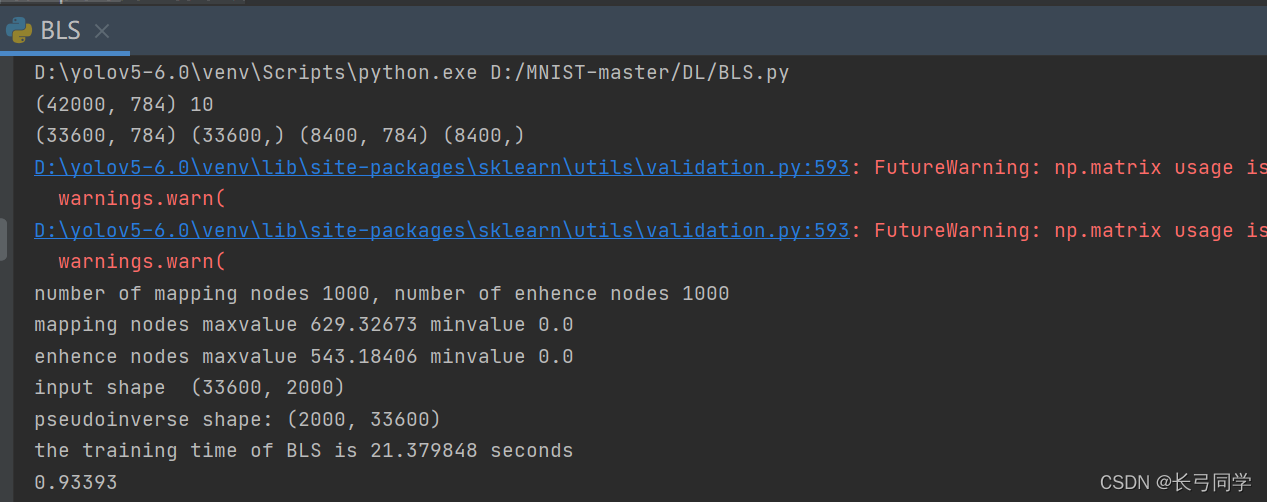
可以看到这与之前原始数据训练的结果几乎相同
4.补充(bls增量代码)
import numpy as np
import pandas as pd
import datetime
from sklearn import preprocessing # 用来转化为独热编码
from sklearn.model_selection import train_test_split
from scipy import linalg as LA # 用来求正交基
import joblib# 在第一次求权重时,并未使用岭回归,还是直接求了伪逆,对于小型数据集这种方法足够了def show_accuracy(predictLabel, Label):Label = np.ravel(Label).tolist()predictLabel = predictLabel.tolist()count = 0for i in range(len(Label)):if Label[i] == predictLabel[i]:count += 1return (round(count / len(Label), 5))class node_generator(object):def __init__(self, isenhance=False):self.Wlist = []self.blist = []self.function_num = 0self.isenhance = isenhancedef sigmoid(self, x):return 1.0 / (1 + np.exp(-x))def relu(self, x):return np.maximum(x, 0)def tanh(self, x):return (np.exp(x) - np.exp(-x)) / (np.exp(x) + np.exp(-x))def linear(self, x):return xdef generator(self, shape, times):# times是多少组mapping nodesfor i in range(times):W = 2 * np.random.random(size=shape) - 1if self.isenhance == True:W = LA.orth(W) # 求正交基,只在增强层使用。也就是原始输入X变成mapping nodes的W和mapping nodes变成enhancement nodes的W要正交b = 2 * np.random.random() - 1yield (W, b)def generator_nodes(self, data, times, batchsize, function_num):# 按照bls的理论,mapping layer是输入乘以不同的权重加上不同的偏差之后得到的# 若干组,所以,权重是一个列表,每一个元素可作为权重与输入相乘self.Wlist = [elem[0] for elem in self.generator((data.shape[1], batchsize), times)]self.blist = [elem[1] for elem in self.generator((data.shape[1], batchsize), times)]self.function_num = {'linear': self.linear,'sigmoid': self.sigmoid,'tanh': self.tanh,'relu': self.relu}[function_num] # 激活函数供不同的层选择# 下面就是先得到一组mapping nodes,再不断叠加,得到len(Wlist)组mapping nodesnodes = self.function_num(data.dot(self.Wlist[0]) + self.blist[0])for i in range(1, len(self.Wlist)):nodes = np.column_stack((nodes, self.function_num(data.dot(self.Wlist[i]) + self.blist[i])))return nodesdef transform(self, testdata):testnodes = self.function_num(testdata.dot(self.Wlist[0]) + self.blist[0])for i in range(1, len(self.Wlist)):testnodes = np.column_stack((testnodes, self.function_num(testdata.dot(self.Wlist[i]) + self.blist[i])))return testnodesdef update(self, otherW, otherb):# 权重更新self.Wlist += otherWself.blist += otherbclass scaler:def __init__(self):self._mean = 0self._std = 0def fit_transform(self, traindata):self._mean = traindata.mean(axis=0)self._std = traindata.std(axis=0)return (traindata - self._mean) / (self._std + 0.001)def transform(self, testdata):return (testdata - self._mean) / (self._std + 0.001)class broadNet(object):def __init__(self, map_num=10, enhance_num=10, DESIRED_ACC=0.99, EPOCH=10, STEP=1, map_function='linear',enhance_function='linear', batchsize='auto'):self.map_num = map_num # 多少组mapping nodesself.enhance_num = enhance_num # 多少组engance nodesself.batchsize = batchsizeself.map_function = map_functionself.enhance_function = enhance_functionself.DESIRED_ACC = DESIRED_ACCself.EPOCH = EPOCHself.STEP = STEPself.W = 0self.pseudoinverse = 0self.normalscaler = scaler()self.onehotencoder = preprocessing.OneHotEncoder(sparse=False)self.mapping_generator = node_generator()self.enhance_generator = node_generator(isenhance=True)def fit(self, data, label):if self.batchsize == 'auto':self.batchsize = data.shape[1]data = self.normalscaler.fit_transform(data)label = self.onehotencoder.fit_transform(np.mat(label).T)mappingdata = self.mapping_generator.generator_nodes(data, self.map_num, self.batchsize, self.map_function)enhancedata = self.enhance_generator.generator_nodes(mappingdata, self.enhance_num, self.batchsize,self.enhance_function)print('number of mapping nodes {0}, number of enhence nodes {1}'.format(mappingdata.shape[1],enhancedata.shape[1]))print('mapping nodes maxvalue {0} minvalue {1} '.format(round(np.max(mappingdata), 5),round(np.min(mappingdata), 5)))print('enhence nodes maxvalue {0} minvalue {1} '.format(round(np.max(enhancedata), 5),round(np.min(enhancedata), 5)))inputdata = np.column_stack((mappingdata, enhancedata))print('input shape ', inputdata.shape)# 求伪逆self.pseudoinverse = np.linalg.pinv(inputdata)# 新的输入到输出的权重print('pseudoinverse shape:', self.pseudoinverse.shape)self.W = self.pseudoinverse.dot(label)# 查看当前的准确率Y = self.predict(data)accuracy = self.accuracy(Y, label)print("inital setting, number of mapping nodes {0}, number of enhence nodes {1}, accuracy {2}".format(mappingdata.shape[1], enhancedata.shape[1], round(accuracy, 5)))# 如果准确率达不到要求并且训练次数小于设定次数,重复添加enhance_nodesepoch_now = 0while accuracy < self.DESIRED_ACC and epoch_now < self.EPOCH:Y = self.addingenhance_predict(data, label, self.STEP, self.batchsize)accuracy = self.accuracy(Y, label)epoch_now += 1print("enhencing {3}, number of mapping nodes {0}, number of enhence nodes {1}, accuracy {2}".format(len(self.mapping_generator.Wlist) * self.batchsize,len(self.enhance_generator.Wlist) * self.batchsize,round(accuracy, 5),epoch_now))def decode(self, Y_onehot):Y = []for i in range(Y_onehot.shape[0]):lis = np.ravel(Y_onehot[i, :]).tolist()Y.append(lis.index(max(lis)))return np.array(Y)def accuracy(self, predictlabel, label):# print('predictlabel shape', predictlabel.shape)bbb# print('label shape:', label.shape)labels = []for i in range(len(label)):labels.append(np.argmax(label[i]))labels = np.ravel(labels).tolist()predictlabel = predictlabel.tolist()count = 0for i in range(len(labels)):if labels[i] == predictlabel[i]:count += 1return (round(count / len(labels), 5))def predict(self, testdata):# print(self.W.shape)testdata = self.normalscaler.transform(testdata)test_inputdata = self.transform(testdata)return self.decode(test_inputdata.dot(self.W))def transform(self, data):mappingdata = self.mapping_generator.transform(data)enhancedata = self.enhance_generator.transform(mappingdata)return np.column_stack((mappingdata, enhancedata))def addingenhance_nodes(self, data, label, step=1, batchsize='auto'):if batchsize == 'auto':batchsize = data.shape[1]mappingdata = self.mapping_generator.transform(data)inputdata = self.transform(data)localenhance_generator = node_generator()extraenhance_nodes = localenhance_generator.generator_nodes(mappingdata, step, batchsize, self.enhance_function)D = self.pseudoinverse.dot(extraenhance_nodes)C = extraenhance_nodes - inputdata.dot(D)BT = np.linalg.pinv(C) if (C == 0).any() else np.mat((D.T.dot(D) + np.eye(D.shape[1]))).I.dot(D.T).dot(self.pseudoinverse)self.W = np.row_stack((self.W - D.dot(BT).dot(label), BT.dot(label)))self.enhance_generator.update(localenhance_generator.Wlist, localenhance_generator.blist)self.pseudoinverse = np.row_stack((self.pseudoinverse - D.dot(BT), BT))def addingenhance_predict(self, data, label, step=1, batchsize='auto'):self.addingenhance_nodes(data, label, step, batchsize)test_inputdata = self.transform(data)return self.decode(test_inputdata.dot(self.W))if __name__ == '__main__':# load the datatrain_data = pd.read_csv('../train.csv')test_data = pd.read_csv('../test.csv')samples_data = pd.read_csv('../sample_submission.csv')label = train_data['label'].valuesdata = train_data.drop('label', axis=1)data = data.valuesprint(data.shape, max(label) + 1)traindata, valdata, trainlabel, vallabel = train_test_split(data, label, test_size=0.2, random_state=0)print(traindata.shape, trainlabel.shape, valdata.shape, vallabel.shape)bls = broadNet(map_num=20, # 初始时多少组mapping nodesenhance_num=20, # 初始时多少enhancement nodesEPOCH=20, # 训练多少轮map_function='sigmoid',enhance_function='sigmoid',batchsize=200, # 每一组的神经元个数DESIRED_ACC=0.95, # 期望达到的准确率STEP=10 # 一次增加多少组enhancement nodes)starttime = datetime.datetime.now()bls.fit(traindata, trainlabel)endtime = datetime.datetime.now()joblib.dump(bls, "model_allin.pkl")print('the training time of BLS is {0} seconds'.format((endtime - starttime).total_seconds()))predictlabel = bls.predict(valdata)print(show_accuracy(predictlabel, vallabel))predicts = bls.predict(test_data)# save as csv filesamples = samples_data['ImageId']result = {'ImageId': samples,'Label': predicts}result = pd.DataFrame(result)result.to_csv('../output/bls_addenhancenodes.csv', index=False)