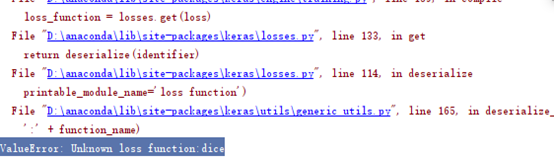
[深度学习论文笔记]3D AGSE-VNet: An Automatic Brain Tumor MRI Data Segmentation Framework
3D-AGSE-VNet:一种自动脑肿瘤MRI数据分割框架
Published: Jul 2021
Abstract by BMC Medical Imaging
论文:https://arxiv.org/abs/2107.12046
摘要:
脑胶质瘤是最常见的脑恶性肿瘤,发病率高,死亡率超过3%,严重危害人类健康。临床上获取脑肿瘤的主要方法是MRI。从多模态MRI扫描图像中分割脑肿瘤区域有助于治疗检查、诊断后监测和患者疗效评估。然而,临床上常见的脑肿瘤分割操作仍然是手工分割,导致其耗时长,不同操作人员之间的性能差异大,迫切需要一种一致、准确的自动分割方法。随着深度学习的不断发展,研究人员设计了许多自动分割算法;但是,仍然存在一些问题:1)分割算法的研究大多停留在二维平面上,这将在一定程度上降低三维图像特征提取的精度。2) MRI图像具有灰度偏移场,因此很难精确分割轮廓。
针对上述挑战,作者提出了一种脑肿瘤MRI数据自动分割框架AGSE-VNet。在研究中,压缩和激励SE模块被添加到每个编码器,注意引导过滤器AG模块被添加到每个解码器,利用信道关系自动增强信道中的有用信息以抑制无用信息,并利用注意机制引导边缘信息,去除噪声等无关信息的影响。
使用BraTS2020来评估方法。验证的重点是整个肿瘤(WT)、肿瘤核心(TC)和增强肿瘤(ET)的Dice得分分别为0.68、0.85和0.70。结论尽管MRI图像强度不同,但AGSE-VNet不受肿瘤大小的影响,能更准确地提取三个区域的特征,取得了令人印象深刻的效果,为脑肿瘤患者的临床诊断和治疗做出了突出贡献。
问题动机:
胶质瘤是原发性脑肿瘤的常见类型之一,约占颅内肿瘤的50%。根据WHO分类标准,胶质瘤可根据不同症状分为四级,其中I级和II级为低级别胶质瘤(LGG),III级和IV级为高级别胶质瘤(HGG)。由于胶质瘤的高死亡率,它可以出现在大脑的任何部位和任何年龄的人,具有不同的组织亚区和不同程度的侵袭性。因此,它引起了医学界的广泛关注。由于胶质母细胞瘤(glioblastoma,GBM)细胞浸没在健康的脑实质中并浸润周围组织,因此它们可以在蛋白质纤维附近快速生长和扩散,并且恶化过程非常迅速。因此,早期诊断和治疗至关重要。
目前,临床上获取脑肿瘤的方法主要有计算机断层扫描(CT)、正电子发射断层扫描(PET)和磁共振成像(MRI)。其中,MRI已成为脑诊断和治疗计划的首选医学成像方法。因为它提供了具有高对比度软组织和高空间分辨率的图像,它很好地代表了颅神经软组织的解剖结构和病变图像。同时,MRI图像可以通过一次扫描获得不同空间内脑肿瘤的多序列信息。该信息包括四个序列:T1加权(T1)、T1加权对比增强(T1-CE)和T2加权(T2)、流体衰减反转恢复(FLAIR)。然而,从MRI图像手动分割肿瘤需要专业的先验知识,这既耗时又费力,而且容易出错,这非常依赖于医生的经验。因此,开发一种准确、可靠、全自动的脑肿瘤分割算法具有很强的临床意义。
随着计算机视觉和模式识别技术的发展,卷积神经网络被用来解决许多具有挑战性的任务。例如,分类、分割和目标检测能力都有了很大的提高。此外,深度学习技术在医学图像处理中显示出巨大的潜力。迄今为止,学术界和工业界对医学图像分割进行了大量的研究。VNet在单模态图像中具有良好的分割性能,但在多模态分割中仍存在一些不足。在本文中,受Anne-Marie等人提出的【`Project & Excite’ Modules for Segmentation of V olumetric Medical Scans】将(PE)模块集成到3D U-net的启发,作者提出了一种自动脑肿瘤MRI数据分割框架,称为3D AGSE VNet。网络结构如图1所示。
本文的主要贡献是:
1) 提出了一种基于VNet的组合分段模型,集成了SE模块和AG模块。
2) 使用体积输入,三维卷积用于处理MRI图像。
3) 取得了良好的分割效果,具有潜在的临床应用价值。
模型方法:
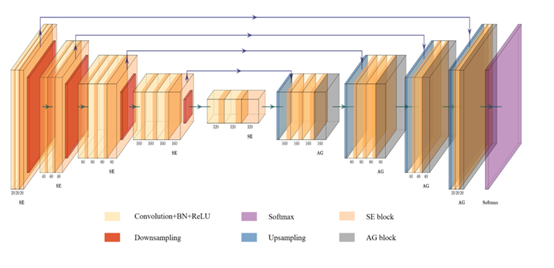
图1:拟议的3D AGSE VNet的总体架构。
虽然许多专家学者提出了多种深度学习网络结构,并在脑肿瘤分割领域取得了良好的效果。然而,由于脑胶质瘤固有的各向异性,MRI图像显示高度不均匀和不规则形状。其次,深度学习的分割方法需要大规模的标注数据,而脑肿瘤数据一般较小且复杂,其固有的高度异质性会导致脑肿瘤区域和肿瘤区域的子区域之间的类内差异、类与非肿瘤区域之间的差异等,这些问题都影响了脑肿瘤分割的准确性。(挑战)
在本文中,为了应对上述挑战,作者采用了一种组合模型,将“压缩和激励”(SE)模块和“注意引导过滤器”(AG)模块集成到用于3D MRI脑胶质瘤图像分割的VNet模型中,它是一种端到端的网络结构。以体积输入的形式将数据输入模型,并使用三维卷积来处理MRI图像。当图像与不同的编码器块一起压缩时,分辨率减半,通道数增加。在图像被卷积之后,执行压缩模块。通过学习,自动获得每个特征通道的重要性。然后根据此重要级别提升有用功能,并取消当前任务中不太有用的功能。每个解码器接收下采样对应阶段的特征并对图像进行解压缩,上采样时集成AG模块,注意模块用于消除噪声和无关背景的影响,而引导图像滤波用于引导图像特征和结构信息(边缘信息),值得一提的是,模型中采用了跳跃连接的思想,避免了梯度的消失。此外,还使用分类损失函数作为模型的优化函数,有效地解决了像素不平衡的问题。
在多模态脑肿瘤分割挑战(BraTS)2020数据集上测试了该模型的性能,并将其与参与挑战的其他团队的结果进行了比较。结果表明,该模型具有良好的分割效果,具有临床应用的潜力。
本文的创新之处在于:
1)巧妙利用渠道关系,利用全局信息增强渠道中的有用信息,抑制渠道中的无用信息。
2) 增加了注意机制,网络结构也充满了跳跃连接。通过下采样提取的信息可以快速捕获,以提高模型的性能。
3) 使用分类dice损失函数解决前景体素和背景体素之间的不平衡问题。
任务是分割3D MRI脑肿瘤图像的多个序列。为了获得良好的分割性能,提出了一种称为AGSE VNet的新网络结构,它将SE(挤压和激励)模块与AG(注意引导过滤器)模块集成到网络结构中,允许网络利用全局信息有选择地增强有用的特征通道,抑制无用的特征通道,巧妙地解决了特征映射的相互依赖性,有效地抑制了图像的背景信息,提高了模型分割的精度。
挤压和激励模块:
图2是SE模块的示意图,主要包括压缩模块和激励模块。该模块的核心是通过显式建模信道之间的相互依赖关系,自适应地重新校准信道的特征响应。

图2.SE网络模块图
图中Ftr标准卷积运算,如公式(1)所示,输入为X,输出为U,
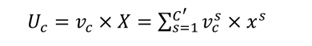
Vc表示每个通道作用于相应的通道特征, 是一个三维空间卷积是挤压操作。 如公式(2)所示,特征U首先通过压缩操作。它沿空间梯度对特征进行压缩,并将特征映射聚合为W×H维的特征映射作为特征描述符。
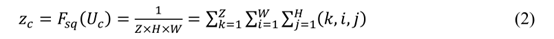
每个三维特征通道成为一个实数,它响应特征通道上的全局分布,在一定程度上,此时的实数更接近全局感受野。此操作将转换的输入hwc变成11c的输出。
注意引导过滤器模块:
注意引导过滤器(AG)模块结合了注意模块和引导图像过滤。注意引导过滤器过滤低分辨率特征图和高分辨率特征图,从不同分辨率的特征图中恢复空间信息和合并结构信息。图3是注意块的示意图,其中O及I是注意力引导过滤器的输入,以及通过计算获得的注意力图。注意块在这种方法中非常关键。有效解决了背景对前景的影响,具有突出前景、减少背景的效果。对于给定的特征映射O及Il, 使用1×1×1通道的卷积进行线性变换,然后通过元素相加将两个转换后的特征图与ReLU层组合,然后使用1×1×1通道。卷积再次进行线性变换,而sigmoid最常用于激活最终的注意力特征图T.

图3.注意方框示意图
图4是AG模块的结果的示意图。输入是引导特征图(I) 以及过滤后的特征映射(O), 输出为高分辨率特征图(O~),这是I及O一起结合的结果, 如式(5)所示。

图4:注意引导滤波器块结构图。
结构详解:
1、下采样
网络结构共分为编码器和解码器,如图5所示,其中图a为编码器,编码区主要进行压缩路径,图b为解码器,解码区进行解压缩。下采样由四个编码器块组成,每个编码器块包括2-3层卷积、压缩和激励层以及下采样层,SE模块的处理过程如图5(a)右侧所示。特征提取通过步长为2的卷积进行。卷积如下(9)(10)所示:

i是输入大小,is是填充后的输出大小,s是步长,p是填充尺寸,k是卷积内核大小,并且o是输出大小。

图5:使用AGSE VNet的编码器块和解码器块的体系结构
当图像与不同的编码器块一起压缩时,其分辨率将减半,通道数将增加一倍。这是通过用步长为2的333进行卷积来实现的。卷积操作后,执行压缩和激励模块,巧妙地解决了通道之间的关系,提高了通道中的有效信息传输。值得一提的是,所有卷积层都采用了归一化和dropout处理,ReLU激活函数也应用于网络结构中的各个位置。此外,模型中还采用了跳跃连接的方法,避免了梯度随着网络结构的加深而消失。
2、上采样:
在对模型进行下采样后,引入AG模块来解决从低分辨率特征地图到高分辨率特征图的空间信息恢复和结构信息融合问题。AG模块与SE模块类似。在不改变输入和输出维度的基础上,功能得到了增强。因此,作者将VNet模型中的拼接模块替换为AG模块,并将其集成到解码器中。
每个解码器块包括上采样层、AG模块和三层卷积,AG模块的处理流程如图5(b)右侧的框中所示。解码器解压缩图像。在上采样中,本文采用步长为2的反卷积来填充图像特征信息。反卷积如公式(11)所示:
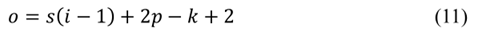
每个解码器块接收下采样的对应级的特征。网络结构最后一层使用的卷积核保持输出通道数与类别数一致。最后,通过sigmoid函数将通道值转换为概率值输出,并将体素转换为脑肿瘤坏疽区域。每个解码块采用跳转连接的思想。由编码器和解码器处理后的特征映射如图6所示,其中图6(a)是由编码器处理的特征映射,图6(b)是由解码器处理的特征映射。

图6:编码器和解码器处理的特征图。
3、跳跃连接:
Vnet为了进一步弥补在编码器的下采样中丢失的信息,在网络的编码器和解码器之间使用concat来融合两个过程中相应位置的特征映射。特别是,本文中采用的方法使用AG(注意引导滤波器块)模块而不是concat,因此解码器可以在上采样期间获取信息。利用更多的高分辨率信息,可以更好地恢复原始图像中的细节信息,提高分割精度。
在网络中引入了相邻层特征重构和跨层特征重构。跨层特征重构模块基于编解码结构。在网络通信过程中,随着网络的不断深入,相应特征图的接受域会越来越大,但保留的详细信息会越来越少。基于编码器-解码器的对称结构,拼接层用于拼接编码器过程中从下采样中提取的特征映射和解码器过程中从上采样中获得的新特征,以执行信道维拼接。保留更重要的特征信息有利于获得更好的分割效果。相邻层特征重构是在具有相同尺寸特征图的每对相邻卷积层之间建立分支,即利用拼接层对上一层和下一层卷积得到的特征图进行卷积。获取通道大小的目的是最大限度地利用所有先前层中的特征信息。
损失函数:
目前,医学图像分割面临着前景区域与背景区域不平衡的问题。在任务中也面临着这样的挑战。因此,作者选择分类损失函数作为模型的优化函数。Heavy通过调整每个预测类别的权重来解决此问题。作者将坏疽、水肿和增强肿瘤的重量设置为1,背景重量设置为0.1。分类损失函数如公式(12)所示:

G:one-hot编码的真实标签
P: 预测值,是softmax计算后得到的概率结果
实验与结果:
数据集:
在本研究中,使用BraTS 2020挑战的数据集来训练和测试模型。数据集包括两种类型,即低级别胶质瘤(LGG)和胶质母细胞瘤(HGG),每种类型有四种模式图像:T1加权(T1)、T1加权对比增强(T1-CE)和T2加权(T2)、液体衰减反转恢复(FLAIR)。脑肿瘤的标签包括坏疽区、水肿区和强化区。任务是分割由嵌套标签形成的三个子区域,即增强肿瘤(ET)、整个肿瘤(WT)和肿瘤核心(TC)。
训练集中有369个案例,验证集中有125个案例。与这些情况对应的标签不用于训练,其功能主要用于训练后评估模型。
实现细节:
在深度学习训练中,超参数的设置非常重要,它将决定模型的性能。但通常在训练中,超参数的初始值是由经验设定的。在AGSE VNet模型的训练中,初始学习率设置为0.0001,dropout设置为0.5,训练次数约为350000,然后将学习率调整为0.00003。每次遍历数据集时,数据集将减半,并对数据进行混洗,以增强模型的鲁棒性和泛化能力。
实验环境在Tensorflow 1.13.1上进行,运行时平台处理器为Intel(R)Core(TM)i7-9750H CPU@2.60GHz,32GB RAM,Nvidia GeForce RTX 2080,64位Windows 10。开发软件平台为PyCharm,python版本为3.6.9。
预处理:
不同对比度的问题,这可能会导致梯度在训练过程中消失,因此作者使用标准化处理图像,从图像像素。通过减去平均值并除以标准偏差,对图像数据进行归一化。计算如下:由于数据集有四种模态,T1、T1-CE、T2和FLAIR,因此计算如下:

μ代表图像的平均值, 代表标准差,X代表图像矩阵,X^是标准化图像矩阵。
归一化后,将具有相同对比度的四种模式的图像合并,形成具有四个通道的三维图像。组合图像大小为原始图像大小。标签的大小为其像素值包含4个不同的值。通道0为正常组织区,1为坏疽区,2为水肿区,3为肿瘤强化区。然后,将图像和mask分割为多个块并执行面片操作。每个案例生成175个大小为128×128×64的图像。最后,将其保存在NumPy中相应的文件夹中。npy格式(https://numpy. org/doc/stable/reference/)。预处理后的图像如图7所示。
图7.预处理结果。
结果:
数据集包括一个训练集和一个测试集。训练集包含369个案例,测试集包含125个案例。肿瘤的表面包括坏疽区、水肿区、强化区和背景区。标签分别对应于1、2、4和0。这些标签被合并成三个嵌套的子区域,即增强肿瘤(ET)、整个肿瘤(WT)和肿瘤核心(TC),对于这些子区域,使用敏感性、特异性、dice系数和Hausdorff95距离四个指标来衡量模型的性能。使用BraTS 2020的数据集进行训练和验证,获得的平均指数如表1所示。从表1中,观察到该模型对WT区域具有更好的分割效果。训练集和验证集的Dice和灵敏度分别为0.846、0.849、0.825和0.833,显著优于其他区域。

表1:训练集和验证集的定量评估。
在此基础上,对实验结果进行了统计分析。图8和图9是训练集和测试集四个评价指标的散点图和方框图,反映了结果的分布特征。从方框图可以看出,各种指标的异常值较少,结果波动最小。方框图中的水平线表示这组数据的中间值。可以观察到,Dice、敏感性和特异性三个指标处于较高水平,这表明提出的模型的分割效果位于较高的区域。在四个指标的结果中,敏感性结果都集中在较高的水平上。可以看出,波动范围很小。观察左侧的散点图,可以看出数据都聚集在较高的位置,表明模型是背景区域具有较高的预测水平,可以有效缓解前景像素与背景不平衡的问题

图8.训练集中四个指标的散点图和方框图的集合。

图9.验证集中四个指标的散点图和方框图的集合
从训练集中随机选择了几个切片,并将实际情况与模型预测的结果进行比较,如图10(a)所示,第一行是原始图像,第二行是标签,第三行是模型预测的肿瘤分区。同时,还选择了其中两个显示在图10(b)中。其中,绿色区域代表整个肿瘤(WT),红色区域代表肿瘤核心(TC),黄色和红色结合的区域代表增强肿瘤(ET)。在最后两列中显示了分割结果的3D图像。通过对分割结果的比较,可以发现模型对脑肿瘤的分割有很好的效果,尤其是对整个肿瘤(WT)区域的分割效果非常好。然而,肿瘤核心(TC)的分割预测稍有偏差,由于肿瘤核心的小特征可能不适合提取。


图10:在训练集中显示分割结果。
训练完成后,在验证集中随机选择几个分割切片进行显示,如图11(a)所示。同样,在图11(b)中,还展示了分割结果的三维图像,并注释了ET区域的准确值,从图中可以看出,模型对不同强度的MRI图像具有良好的分割效果,能够准确地分割肿瘤子区域,这在脑肿瘤图像分割中具有一定的潜力。


图11.验证集中分割结果的显示。
提出了AGSE VNet模型来分割3D MRI脑肿瘤图像,并在BraTS 2020数据集上获得了更好的分割结果。为了进一步验证分割效果,将实验方法与参加比赛的其他优秀团队提出的方法进行比较。训练集的比较结果如表2所示,验证集的比较结果如表3所示。从表中的结果可以看出,模型在整个肿瘤(WT)区域表现良好,并获得了相对优异的结果,表明本文提出的方法在图像分割中具有一定的潜力。

表2:训练集中各项指标的结果

表3:验证集中各项指标的结果
讨论:
本文提出的方法巧妙地解决了通道之间的相互依赖问题,并能自动从通道中提取有效特征以抑制无用特征通道。在编码器提取特征后,通过注意模块过滤低分辨率特征图和高分辨率特征图,从不同分辨率的特征图中恢复空间信息和融合结构信息,该方法不受肿瘤大小和位置的影响。对于不同强度的MRI图像,可以自动识别肿瘤区域,对肿瘤子区域进行特征提取和分割,取得了良好的分割效果。这对放射科医生和肿瘤学家是有益的,他们可以快速预测肿瘤的状况并帮助患者治疗。对比表2和表3的结果,发现模型在整个肿瘤(WT)区域表现良好,但在增强肿瘤(ET)和肿瘤核心(TC)区域表现不佳,这可能是因为ET区域的目标较小,特征模糊且难以提取。同时,将该方法与一些经典的脑肿瘤分割算法进行了比较。结果如表4所示。在2018年的BraTS Challenge中,zhou等人[One-Pass Multi-Task Networks With Cross-Task Guided Attention for Brain Tumor Segmentation]通过学习关节特征的共享参数和区分特定任务参数的组合特征,提出了一种轻量级的一步多任务分割模型,有效地缓解了肿瘤类型的不平衡因素,抑制了不确定信息,提高了分割效果。在Zhao等人提出的方法中,开发了一种新的分割框架,使用完全卷积神经网络以像素为单位为图像指定不同的标签,使用条件随机位置构造的递归神经网络优化FCNNs的输出结果,该方法在BraTS 2016数据集上进行了验证,取得了良好的分割效果。Pereira等人提出了一种卷积神经网络的自动定位方法,该方法在BraTS 2015数据集中取得了良好的效果。
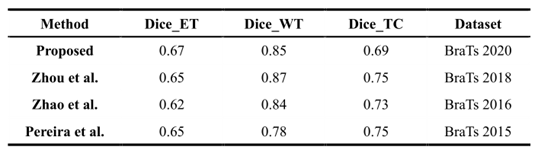
表4:提出的AGSE VNet模型与经典方法的比较
通过对表4的分析,发现模型在分割方面具有一定的优势,在TC区域精度上仍然存在差异,并且该模型存在局限性。在未来的工作中,将针对这种情况提出解决方案,例如在模型提取出感兴趣的区域后如何进一步分割该区域,为了提高增强肿瘤(ET)和肿瘤核心(TC)区域的准确性,可以捕获更多的特征信息。此外,许多顶级方法中提出的算法都有其卓越的性能。如何结合这些算法的优点并将它们集成到模型中是未来工作的重点。在临床治疗中,它帮助专家更快、更准确地了解患者的现状,节省专家时间,实现了医学自动分割质量的飞跃。
此外,为了验证模型抵抗噪声干扰的鲁棒性,在测试数据的频域(k空间)中添加了高斯噪声,以模拟真实的噪声污染。比较结果如图12所示。从有噪和无噪分割结果中,发现AGSE VNet模型对三个区域的分割结果没有太大差异。这些结果表明,当存在噪声时,模型在泛化方面具有显著的优势。

图12.无噪声和添加噪声的分割结果比较。
总结:
实现了一种很好的3D-MRI脑肿瘤图像分割方法,该方法可以自动分割增强肿瘤(ET)、整个肿瘤(WT)和肿瘤核心(TC)三个区域。在BRATS2020数据集上进行了实验,取得了良好的结果。基于VNet对AGSE-VNet模型进行了改进。有五个编码器块和四个解码器块。每个编码器块有一个压缩块和激励块,每个解码器有一个滤波器块。在输入比和输出比不变的情况下,这种设计可以嵌入到模型中,而不会影响网络结构的大小失配。SE模块处理模型后,网络学习全局信息并选择增强通道中的有用信息,然后使用注意力过滤块的注意机制快速捕获其依赖项并增强模型的性能。其次,我们还引入了一种新的损失函数分类dice,为未使用的掩模设置不同的权重,将背景区域的权重设置为0.1,将感兴趣的肿瘤区域设置为1,巧妙地解决了前景和背景之间的体素不平衡问题.在BraTS上的结果发现,模型仍然不同于用于增强肿瘤(ET)和肿瘤核心(TC)区域分割的顶级方法。这可能是因为这两个区域的特征较小且难以提取。如何提高这两个区域的精度是今后的工作方向。
脑肿瘤的自动分割在医学领域一直是一个长期的研究课题。如何设计一种时间短、精度高的自动分割算法,并形成一个完整的系统是当前众多研究者的研究方向。因此,必须继续优化细分模型,以实现自动细分领域的质的飞跃。