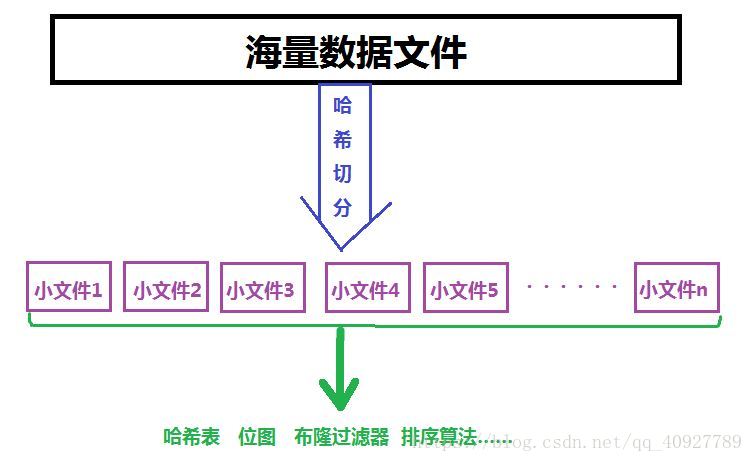
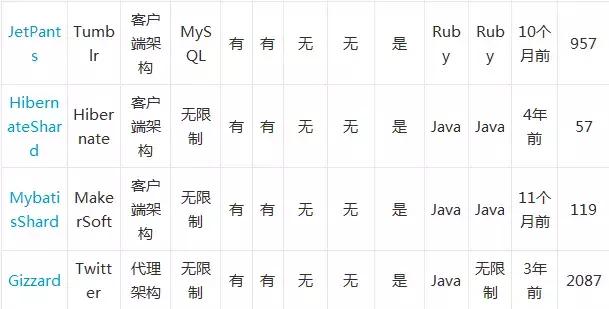
生活中我们经常会遇到一些海量数据处理的问题,那么怎样的问题就算是海量数据了呢?来看以下这几个问题:
- 给定一个大小超过 100G 的文件, 其中存在 IP 地址, 找到其中出现次数最多的 IP 地址 。
- 给定100亿个整数, 找到其中只出现一次的整数(位图变形, 用两位来表示次数)。
- 有两个文件, 分别有100亿个query(查询词, 字符串), 只有1G内存, 找到两个文件的交集。
- 给上千个文件, 每个文件大小为1K - 100M, 设计算法找到某个词存在在哪些文件中。
首先第一个问题很明确有100G的数据;第二个问题100亿个整数所占的空间大小是:100亿*4byte = 40G;第三个问题100亿也就是10G……要知道我们日常使用的电脑也就是4G、8G的内存大小,远不能满足这里的100G、40G……的数据处理的需求。但是我们又必须要处理类似这样的问题,难道就束手无策了么!!!
为了解决类似这样的问题,我们可以借助之前学的哈希表,位图,布隆过滤器这样的数据结构,接下来我们来了解一下相关知识。
哈希表
详情请移步:哈希表
位图
详情请移步:位图
布隆过滤器
详情请移步:布隆过滤器
哈希切分
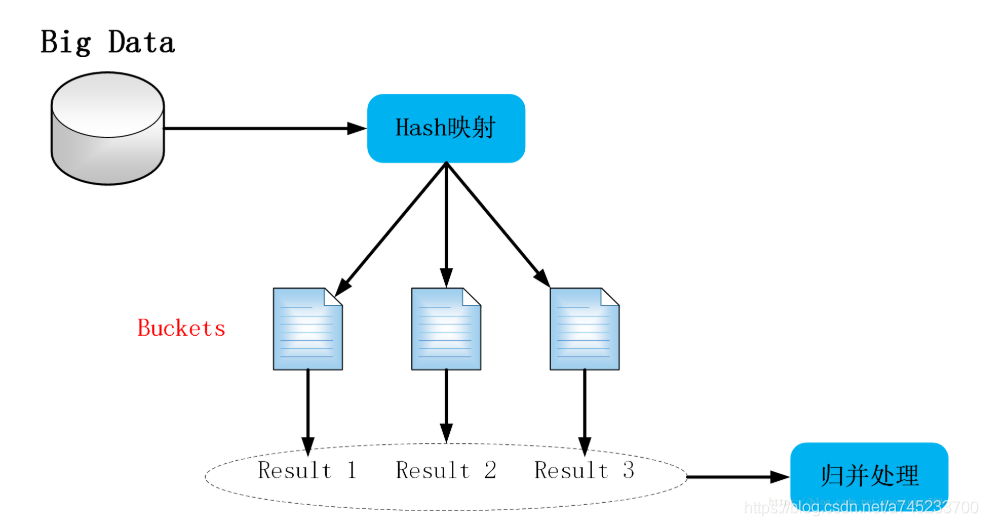
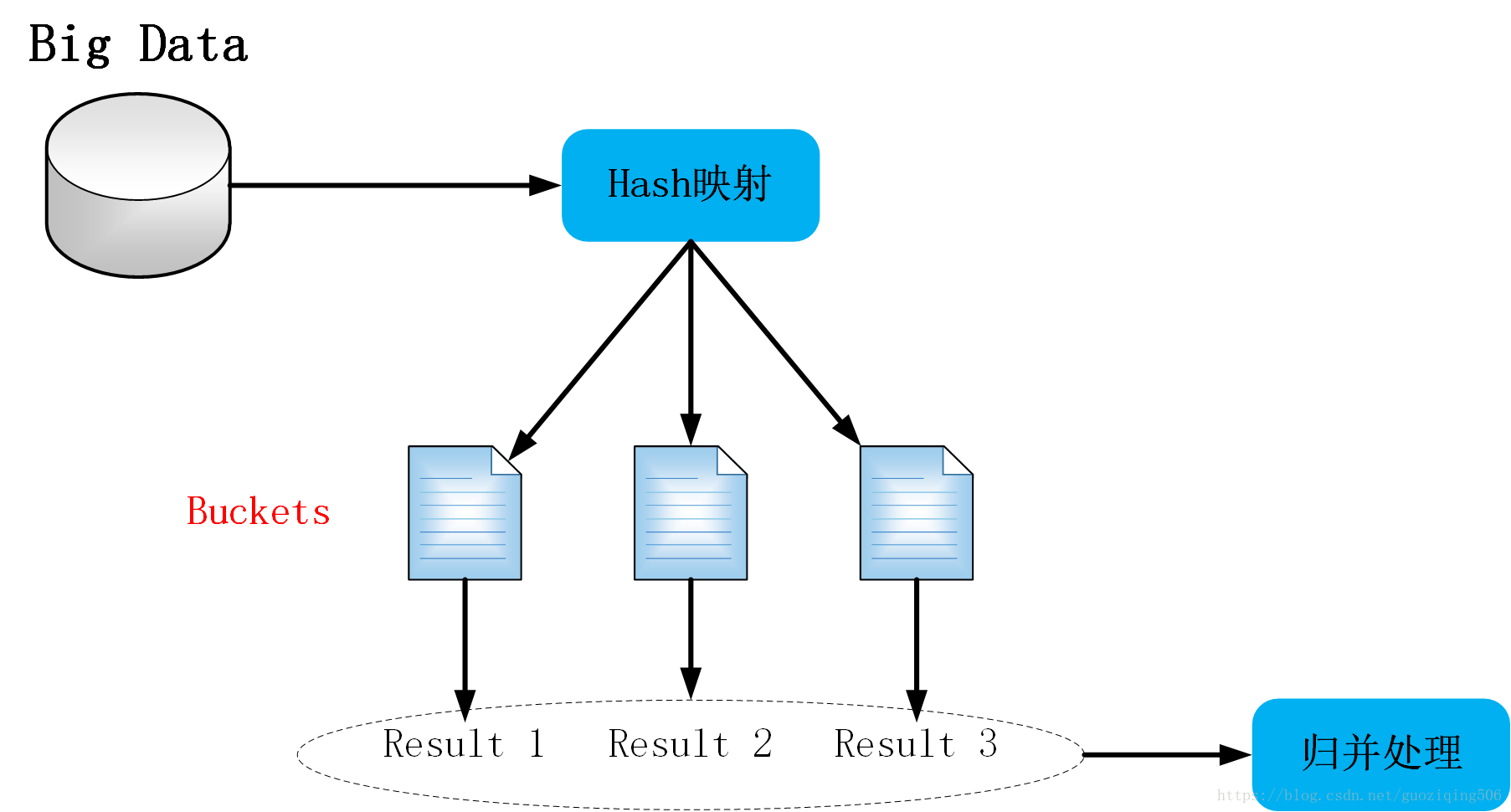
所谓的切分就很好理解,就是将一个东西切分开,将一个整体划分为多个更小的小整体。那么这里的哈希切分又是什么操作呢?提到哈希我们就要想到这其中使用了哈希函数,同样 的哈希切分,也需要用到哈希函数,只不过我们这里使用哈希函数的目的在于将一个大文件分割成多个小文件。具体做法就是,我们通过哈希函数计算大文件中的每一个数据的哈希地址,将哈希地址相同的数据存放到同一个地方,所以这里的哈希地址也就是我们新的存放数据的地方(小文件)的编号,这就叫做哈希切分,哈希切分达到的最终的目的就是将相同规律(比如说相同的IP地址,相同的单词)的数据一定是存放在同一个文件中,但同时该文件中也会有其他的不符合同一规律的数据。
了解完相关知识,现在我们就来解决一下先前提到的4个海量数据问题的处理。
1、给定一个大小超过 100G 的文件, 其中存在 IP 地址, 找到其中出现次数最多的 IP 地址(hash文件切分) 。
答:首先我们看到100G的数据,肯定是不能直接处理的。
那么我们就可以考虑使用哈希切分的方法,先将这100G的数据进行切分,切分完成以后就会有多个小文件,按照题目的要求,我们切分完以后,IP相同的一定都在同一个文件中。现在我们就可以借助哈希表,哈希表存在一个键值对(key和value:初始化均为0)。依次遍历每一个小文件,读取其中的数据,通过哈希函数计算哈希地址,如果当前数据还没有存入(对应的key为0)则将对应的哈希地址的key置为1,value值加1。如果发现数据已经被存入过了,则就直接将对应位置的value(出现次数)值加1即可。所有的小文件中的数据遍历完成以后,所有的ip地址已经存入到哈希表中;最后一步,根据哈希表中的value(ip地址出现的次数)进行排序,记录当前出现次数最多的ip地址即可。
2、给定100亿个整数, 找到其中只出现一次的整数(位图变形, 用两位来表示次数)。
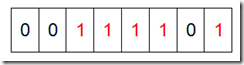
答:此时我们可以采用位图来解决。之前我们实现的位图是用一位bit位来标识一个数据是否存在(bit位为1)或者不存在(bit位为0),显然我们继续采用这样的设计并不能解决我们的问题,此时我们只需要扩展一下,用两个bit位。两个bit位就有4种状态:00->表示没有出现,01->表示出现一次,10和11则表示出现的次数超过1次。接下来我们就将处理数据(对应到位图当中),处理完成以后显然我们就可以很轻松的知道谁是只出现一次的数据。
3、有两个文件, 分别有100亿个query(查询词, 字符串), 只有1G内存, 找到两个文件的交集(hash文件切分 + 布隆过滤器)。
答:首先我们分析过数据规模很大,没有办法直接处理。那么我们先采用哈希切分减小问题规模。采用哈希切分将两个文件切分成多个文件,切分完毕以后,就有两组多个小文件
(f1.1,f1.2,f1.3,f1.4,f1.5……和f2.1,f2.2,f2.3,f2.4,f2.5……)
接下来我们将其中一组所有小文件的数据采用布隆过滤器存储,然后在处理第二组所有的小文件中的数据,可想而知,当我们在处理第二组小文件中的数据,如果遇到了相同的数据我们一定就会发现(这里布隆过滤器的作用就是判断某字符串是否存在于一堆数据中),那么当我们发现遇到相同的query就直接将该query放入一个保存最终结果的文件中即可,第二组所有的小文件中的数据处理完毕我们也就找出了这两个文件的交集。
4、给上千个文件, 每个文件大小为1K - 100M, 设计算法找到某个词存在在哪些文件中(倒排索引)。
这里我们先来看一下倒排索引。(注意这里说的倒排和正排索引只是一个相对的概念,一个叫正排索引那么剩下的这一个就叫做倒排索引)

答:1、首先我们先将每个文件的数据对应的存到一个布隆过滤器中(注意:数据存储完毕以后我们将得到上千个布隆过滤器,每一个文件对应一个布隆过滤器)。
2、然后我们在读取每一个布隆过滤器中的词,并且记录每一个词对应的所在文件,用一个文件(info)保存词和其所对应的文件信息。(倒排索引)
3、现在我们已经得到了所有的词,那么将这些词分为几个小部分,分别存储到布隆过滤器中(如果单词数量足够大,又u只将其存储到一个布隆过滤器中的话,可能内存会不够用)。
4、现在我们拿到一个单词需要判断他存在于哪些文件中,那么我们就先在存储单词的布隆过滤器查找(布隆过滤器的基本操作:查找某个字符串是否存在),该单词是否存在:
4.1如果不存在则取下一个存储单词的布隆过滤器查找,如果所有的布隆过滤器都查找完了并且都没有找到该单词,那就说明该单词在这上千个文件中没有出现过;
4.2如果我们在某一个存储单词的布隆过滤器中找到了该单词,就说明该单词在这上千个文件中出现过。
5、此时我们就可以去info文件中查找到该单词,那么也就知道该单词在哪些文件中出现过了。
总结一下,处理海量数据的思路,如下图: