神经网络什么的早就不是新概念了,不过学了这么久,还一直在二维图像上打转,所以今天开始入手三维图像分割,先从可爱的VNET开始吧,从胖嘟嘟的外形看,这应该是个软柿子,那就试着捏一捏吧,Lets go!

先看一下论文吧:点击链接
摘要
卷积神经网络(CNNs)近年来被广泛应用于计算机视觉和医学图像分析领域。尽管它们很流行,但大多数方法只能处理二维图像,而大多数临床应用的医学数据由三维体组成。本文提出了一种基于体积全卷积神经网络的三维图像分割方法。我们的CNN是端到端的MRI容积描绘前列腺,并学习预测分割为整个体积一次。我们引入了一个新的目标函数,我们在训练中优化,基于骰子系数。这样我们就可以处理前景和背景体素数量严重失衡的情况。为了处理有限数量的带注释的可用于训练的卷,我们应用随机非线性变换和直方图匹配来扩充数据。我们的实验评估表明,我们的方法在具有挑战性的测试数据上取得了良好的性能,而只需要以前其他方法所需处理时间的一小部分。
1. Introduction and Related Work
最近在计算机视觉和模式识别方面的研究突出了卷积神经网络(CNNs)在解决分类、分割和目标检测等具有挑战性的任务方面的能力,实现了最先进的性能。这一成功归功于CNNs能够学习原始输入数据的层次化表示,而无需依赖手工制作的功能。当输入通过网络层处理时,结果特性的抽象级别会增加。较浅的层捕捉本地信息,而较深的层使用接收域更广的过滤器,从而捕捉全局信息[19]。
分割是医学图像分析中一个高度相关的任务。为了完成诸如视觉增强[10]、计算机辅助诊断[12]、干预[20]和从图像[1]中提取定量指标等任务,经常需要对感兴趣的器官和结构进行自动描绘。通常因为诊断和介入图像通常由三维图像组成,能够同时考虑整个体积内容进行体积分割,具有特殊的相关性。在这项工作中,我们的目标是分割前列腺磁共振成像的体积。这是一个具有挑战性的任务,因为前列腺在不同的扫描中由于变形和强度分布的变化而呈现出不同的外观。此外,MRI体积常受人工制品和由于场不均匀造成的畸变的影响。然而,前列腺切断术是一项重要的临床任务,在诊断期间需要评估前列腺体积[13],在治疗计划期间需要准确估计解剖边界[4,20]。
神经网络最近被用于医学图像分割。早期的方法是通过对图像进行分段分类来获得图像或卷中的解剖轮廓。这种分割是通过仅考虑局部环境而获得的,因此很容易失败,特别是在具有挑战性的模式,如超声,其中有大量错误分类的体素是预期的。连接分量分析等后处理方法通常不会有任何改进,因此,最近的研究建议将网络预测与马尔科夫随机场[6]、投票策略[9]或更传统的方法如水平集[2]结合使用。补丁式方法还存在效率问题。当密集提取的patch在CNN中被处理时,大量的计算是冗余的,因此整个算法运行时是高的。在这种情况下,可以采用更有效的计算方案。
迄今为止,完全卷积网络训练的端到端仅应用于计算机视觉[11,8]和显微图像分析[14]中的2D图像。 这些模型作为我们工作的灵感,采用了不同的网络架构,并经过培训,可以预测分割面具,划定感兴趣的结构,整个形象。 在[11]中,通过利用最内层提取的特征的描述能力,将预先训练的VGG网络架构[15]与其镜像,反卷积相结合,等效于片段RGB图像。 在[8]中,对在分类任务上进行预训练的三个完全卷积深度神经网络进行了细化以产生3个分割,而在[14]中提出了一种全新的CNN模型,特别适合于解决2D中的生物医学图像分析问题。
在这项工作中,我们提出了我们的医学图像分割方法,该方法利用完整卷积神经网络的能力,训练端到端,处理MRI体积。 与其他最近的方法不同,我们不会切片处理输入量,我们建议使用体积卷积。 我们提出了一种基于Dice系数最大化的新型目标函数,我们在训练期间进行优化。 我们在前列腺MRI测试体积上展示了快速准确的结果,并且我们提供了与在相同测试数据4上评估的其他方法的直接比较。
2 Method
在图2中,我们提供了卷积神经网络的示意图。我们执行卷积,旨在从数据中提取特征,并在每个阶段结束时通过使用适当的步幅来降低其分辨率。网络的左侧部分由压缩路径组成,而右侧部分解压缩信号直到达到其原始大小。使用适当的填充来应用卷积。
网络的左侧分为不同的阶段,以不同的分辨率运行。每个阶段包括一到三个卷积层。与[3]中提出的方法类似,我们制定每个阶段,使其学习剩余函数:每个阶段的输入是(a)在卷积层中使用并通过非线性处理,(b)添加到该阶段的最后一个卷积层的输出,以便能够学习剩余功能。正如我们的经验观察所证实的那样,这种架构可确保在不学习剩余功能的类似网络所需的时间的一小部分内进行收敛。
在每个阶段中执行的卷积使用具有5×5×5体素大小的体积核。随着数据沿压缩路径前进不同阶段,其分辨率降低。这是通过使用施加步幅2的2×2×2体素宽内核的卷积来执行的(图3)。由于第二操作通过仅考虑非重叠的2×2×2体积块来提取特征,因此所得特征图的大小减半。这种策略的作用类似于汇集层,由[16]和其他阻止在CNN中使用最大池操作的工作,在我们的方法中被卷积的替换。此外,由于特征通道的数量在V-Net的压缩路径的每个阶段加倍,并且由于模型作为剩余网络的形成,我们采用这些卷积操作使特征映射的数量加倍,因为我们降低他们的分辨率PReLu非线性应用于整个网络。
用卷积替换池化操作也会导致网络根据具体的实现,在训练期间可以有更小的内存占用,因为没有开关将池化层的输出映射回其输入需要用于反向传播 通过仅应用去卷积而不是取消汇集操作,可以更好地理解和分析[19]。
下采样允许我们减小作为输入呈现的信号的大小,并增加在后续网络层中计算的特征的感知域。网络左侧部分的每个阶段计算的许多特征比前一层的特征高两倍。网络的右侧部分提取特征并扩展较低分辨率特征图的空间支持,以便收集和组合必要的信息以输出双通道体积分割。由最后一个卷积层计算的具有1×1×1内核大小并产生与输入体积相同大小的输出的两个特征图通过应用soft-max体素被转换为前景和背景区域的概率分割。在CNN右边部分的每个阶段之后,采用去卷积运算以增加输入的大小(图3),接着是一到三个卷积层,涉及一半前一层采用的5×5×5内核数。 与网络的左侧部分类似,在这种情况下,我们也会在卷积阶段学习残差函数。
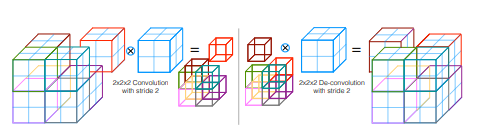
图3:具有适当步幅的卷积可用于减小数据的大小。 相反,去卷积通过将每个输入体素通过内核投影到更大的区域来增加数据大小。
与[14]类似,我们将从CNN左侧部分的早期阶段提取的特征转发到右侧部分。 这在图2中通过水平连接示意性地表示。 通过这种方式,我们可以收集在压缩路径中丢失的细粒度细节,并且我们可以提高最终轮廓预测的质量。 我们还观察到,当这些连接改善了模型的收敛时间。
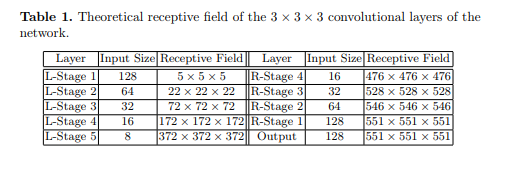
我们在表1中报告了每个网络层的接收字段,显示了CNN的最里面部分已经捕获了整个输入卷的内容。 我们认为这个特征在分割不良可见解剖结构时很重要:在最深层计算的特征一次感知整个感兴趣的解剖结构,因为它们是根据空间支撑远大于解剖结构的典型尺寸的数据计算出来的。 寻求描绘,并因此施加全球约束。
3 Dice loss layer
网络预测由两个具有与原始输入数据相同分辨率的卷组成,通过软最大层处理,该软最大层输出每个体素属于前景和背景的概率。在医疗量中,例如我们的在这项工作中的处理,感兴趣的解剖结构仅占据扫描的非常小的区域并不罕见。这经常导致学习过程陷入损失函数的局部最小值,从而产生其预测强烈偏向背景的网络。结果,前景区域经常丢失或仅部分检测到。以前的几种方法都采用了基于损失函数
在样本重新加权中,前景区域在学习期间比背景区域更重要。在这项工作中,我们提出了一个基于骰子系数的新的目标函数,它是一个介于0和1之间的数量,我们的目标是最大化。两个二进制卷之间的骰子系数D可写为
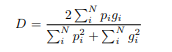
其中总和在N个体素上运行,预测的二进制分割体积pi∈P和地面真实二元体积gi∈G。可以区分这种Dice的形式,产生相对于预测的第j个体素计算的梯度。 使用这个公式我们不需要为不同类别的样本分配权重以在前景体素和背景体素之间建立正确的平衡,并且我们获得的结果我们实验观察到的结果比通过优化多项式逻辑的同一网络计算的结果好得多。 样本重新加权损失(图6)。
3.1 Training
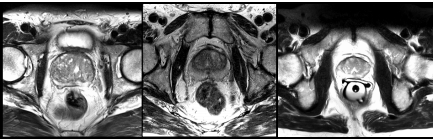
我们的CNN在MRI上进行前列腺扫描数据集的端到端训练。 图1中示出了这种卷的典型内容的示例。由网络处理的所有卷具有128×128×64体素的固定大小和1×1×1.5毫米的空间分辨率。
由于需要一个或多个专家手动追踪可靠的地面实况注释并且存在与其获取相关的成本,因此不容易获得注释的医疗量。 在这项工作中,我们发现有必要增加原始训练数据集,以便在测试数据集上获得稳健性和更高的精度。
在每次训练迭代期间,我们通过使用通过2×2×2网格控制点和B样条插值获得的密集变形场作为输入向网络输入随机变形的训练图像版本。 在每次优化迭代之前,已经“在运行中”执行了这种增强,以便减轻过度的存储需求。 另外,我们通过使用直方图匹配将每次迭代中使用的训练体积的强度分布适配于属于数据集的其他随机选择的扫描,来改变数据的强度分布。
3.2 Testing
先前看不见的MRI体积可以通过网络以前馈方式对其进行分割。 在soft-max之后,最后一个卷积层的输出由背景和前景的概率图组成。 具有较高概率(> 0.5)属于前景而不是背景的体素被认为是解剖结构的一部分。
4 Results

我们在50个MRI体积上训练我们的方法,以及从“PROMISE2012”挑战数据集[7]获得的相对手动地面实况注释。 该数据集包含使用不同设备和不同采集协议在不同医院获取的医疗数据。 该数据集中的数据代表临床变异性和临床环境中遇到的挑战。 如前所述,我们通过在每次训练迭代中执行的随机变换,对馈送到网络的每个小批量大量增加该数据集。 我们实施中使用的小批量每个包含两个卷,主要是由于模型在培训期间的高内存需求。 我们使用0.99的动量和0.0001的初始学习率,每25K迭代减少一个数量级。
我们在30个MRI体积上测试了V-Net,描绘了前列腺的真实注释是秘密的。 本文的这一部分报告的所有结果都是在提交通过我们的方法获得的细分后直接从挑战的组织者处获得的。 该测试集代表了真实临床环境中前列腺扫描中遇到的临床变异性[7]。
我们根据骰子系数,预测描绘的Hausdorff距离与地面实况注释以及根据“PROMISE 2012”[7]的组织者计算的挑战数据获得的得分来评估方法表现。 结果如表2和图5所示。
我们的实现5是在python中实现的,使用了Caffe6 [5]框架的自定义版本,该框架能够通过CuDNN v3执行体积卷积。 所有培训和实验均在配备64 GB内存的标准工作站,工作频率为3.30GHz的Intel(R)Core(TM)i7-5820K CPU和具有8 GB视频内存的NVidia GTX 1080上运行。 我们让我们的模型训练48小时,或大约30K迭代,我们能够在大约1秒钟内分割出以前看不见的音量。 首先使用ANT框架的N4偏置场校正函数对数据集进行归一化[17],然后重新采样到1×1×1.5 mm的常见分辨率。 我们通过改变控制点的位置将随机变形应用于用于训练的扫描,其中随机量从高斯分布获得,具有零均值和15个体素标准偏差。 定性结果见图4。
5 Conclusion
我们基于体积卷积神经网络提出并接近,该网络以快速和准确的方式执行MRI前列腺体积的分割。 我们引入了一种新的目标函数,我们在训练期间根据预测分割和地面实况注释之间的Dice重叠系数进行优化。 当背景和前景像素的数量非常不平衡时,我们的Dice损失层不需要样本重新加权,并且指示用于二进制分割任务。 虽然我们将我们的架构激发到[14]中提出的架构,但我们将其分为学习残差的阶段,并且根据经验观察,它们可以改善结果和收敛时间。 未来的工作将通过将网络分成多个GPU来分割包含其他模态(如超声波和更高分辨率)的多个区域的卷。
6 Acknowledgement
我们要感谢NVidia公司向我们的团队捐赠了特斯拉K40 GPU,Geert Litjens博士将他的一些时间用于评估PROMISE 2012数据集和Iro Laina女士的基本事实。 她对这个项目的支持。