1. 介绍
有三种不同的方法来评估一个模型的预测质量:
estimator的score方法:sklearn中的estimator都具有一个score方法,它提供了一个缺省的评估法则来解决问题。
Scoring参数:使用cross-validation的模型评估工具,依赖于内部的scoring策略。见下。
Metric函数:metrics模块实现了一些函数,用来评估预测误差。见下。
2. scoring参数
模型选择和评估工具,例如: grid_search.GridSearchCV 和 cross_validation.cross_val_score,使用scoring参数来控制你的estimator的好坏。
3.从metric函数定义你的scoring策略
sklearn.metric提供了一些函数,用来计算真实值与预测值之间的预测误差:
以_score结尾的函数,返回一个最大值,越高越好
以_error结尾的函数,返回一个最小值,越小越好;如果使用make_scorer来创建scorer时,将greater_is_better设为False
许多metrics并没有给出在scoring参数中可配置的字符名,因为有时你可能需要额外的参数,比如:fbeta_score。这种情况下,你需要生成一个合适的scorer对象。最简单的方法是调用make_scorer来生成scoring对象。该函数将metrics转换成在模型评估中可调用的对象。一个典型的用例是,将一个库中已经存在的metrics函数进行包装,使用定制参数,比如对fbeta_score函数中的beta参数进行设置:

4.分类metrics
sklearn.metrics模块实现了一些loss, score以及一些工具函数来计算分类性能。一些metrics可能需要正例、置信度、或二分决策值的的概率估计。大多数实现允许每个sample提供一个对整体score来说带权重的分布,通过sample_weight参数完成。一些二分类(binary classification)使用的case:
- matthews_corrcoef(y_true, y_pred)
- precision_recall_curve(y_true, probas_pred)
- roc_curve(y_true, y_score[, pos_label, …])
一些多分类(multiclass)使用的case:
- confusion_matrix(y_true, y_pred[, labels])
- hinge_loss(y_true, pred_decision[, labels, …])
一些多标签(multilabel)的case:
- accuracy_score(y_true, y_pred[, normalize, …])
- classification_report(y_true, y_pred[, …])
- f1_score(y_true, y_pred[, labels, …])
- fbeta_score(y_true, y_pred, beta[, labels, …])
- hamming_loss(y_true, y_pred[, classes])
- jaccard_similarity_score(y_true, y_pred[, …])
- log_loss(y_true, y_pred[, eps, normalize, …])
- precision_recall_fscore_support(y_true, y_pred)
- precision_score(y_true, y_pred[, labels, …])
- recall_score(y_true, y_pred[, labels, …])
- zero_one_loss(y_true, y_pred[, normalize, …])
还有一些可以同时用于二标签和多标签(不是多分类)问题:
- average_precision_score(y_true, y_score[, …])
- roc_auc_score(y_true, y_score[, average, …])
在以下的部分,我们将讨论各个函数
4.1 二分类/多分类/多标签
对于二分类来说,必须定义一些metrics(f1_score,roc_auc_score)。在这些case中,缺省只评估正例的label,缺省的正例label被标为1(可以通过配置pos_label参数来完成)
将一个二分类metrics拓展到多分类或多标签问题时,我们可以将数据看成多个二分类问题的集合,每个类都是一个二分类。接着,我们可以通过跨多个分类计算每个二分类metrics得分的均值,这在一些情况下很有用。你可以使用average参数来指定。
- macro:计算二分类metrics的均值,为每个类给出相同权重的分值。当小类很重要时会出问题,因为该macro-averging方法是对性能的平均。另一方面,该方法假设所有分类都是一样重要的,因此macro-averaging方法会对小类的性能影响很大。
- weighted: 对于不均衡数量的类来说,计算二分类metrics的平均,通过在每个类的score上进行加权实现。
- micro: 给出了每个样本类以及它对整个metrics的贡献的pair(sample-weight),而非对整个类的metrics求和,它会每个类的metrics上的权重及因子进行求和,来计算整个份额。Micro-averaging方法在多标签(multilabel)问题中设置,包含多分类,此时,大类将被忽略。
- samples:应用在 multilabel问题上。它不会计算每个类,相反,它会在评估数据中,通过计算真实类和预测类的差异的metrics,来求平均(sample_weight-weighted)
- average:average=None将返回一个数组,它包含了每个类的得分.
多分类(multiclass)数据提供了metric,和二分类类似,是一个label的数组,而多标签(multilabel)数据则返回一个索引矩阵,当样本i具有label j时,元素[i,j]的值为1,否则为0.
4.2 accuracy_score
accuracy_score函数计算了准确率,不管是正确预测的fraction(default),还是count(normalize=False)。
在multilabel分类中,该函数会返回子集的准确率。如果对于一个样本来说,必须严格匹配真实数据集中的label,整个集合的预测标签返回1.0;否则返回0.0.
预测值与真实值的准确率,在n个样本下的计算公式如下:


4.3 分类报告
classification_report函数构建了一个文本报告,用于展示主要的分类metrics。 下例给出了一个小示例,它使用定制的target_names和对应的label:

4.4 Jaccard相似度系数score
jaccard_similarity_score函数会计算两对label集之间的Jaccard相似度系数的平均(缺省)或求和。它也被称为Jaccard index.
第i个样本的Jaccard相似度系数(Jaccard similarity coefficient),真实标签集为yi,预测标签集为:y^j,其定义如下:


4.5 准确率,召回率与F值
准确率(precision)可以衡量一个样本为负的标签被判成正,召回率(recall)用于衡量所有正例。
F-meature(包括:Fβ和F1”),可以认为是precision和recall的加权调和平均(weighted harmonic mean)。一个Fβ值,最佳为1,最差时为0. 如果β=1那么Fβ和F1相等,precision和recall的权重相等。
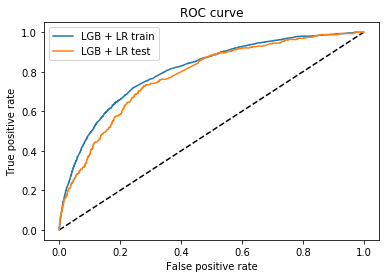
precision_recall_curve会根据预测值和真实值来计算一条precision-recall曲线。
average_precision_score则会预测值的平均准确率(AP: average precision)。该分值对应于precision-recall曲线下的面积。
sklearn提供了一些函数来分析precision, recall and F-measures值:
- average_precision_score:计算预测值的AP
- f1_score: 计算F1值,也被称为平衡F-score或F-meature
- fbeta_score: 计算F-beta score
- precision_recall_curve:计算不同概率阀值的precision-recall对
- precision_recall_fscore_support:为每个类计算precision, recall, F-measure 和 support
- precision_score: 计算precision
- recall_score: 计算recall
注意:precision_recall_curve只用于二分类中。而average_precision_score可用于二分类或multilabel指示器格式
4.6 Hinge loss
hinge_loss函数会使用hinge loss计算模型与数据之间的平均距离。它是一个单边的metric,只在预测错误(prediction erros)时考虑。(Hinge loss被用于最大间隔分类器上:比如SVM)如果label使用+1和-1进行编码。y为真实值,w为由decision_function得出的预测决策。 hinge loss的定义如下:


4.7 Log loss
Log loss也被称为logistic回归loss,或者交叉熵loss(cross-entropy loss),用于概率估计。它通常用在(multinomial)的LR和神经网络上,以最大期望(EM:expectation-maximization)的变种的方式,用于评估一个分类器的概率输出,而非进行离散预测。
对于二元分类,true label为:y∈0,1 概率估计为:p=Pr(y=1)每个样本的log loss是对分类器给定true label的负值log似然估计(negative log-likelihood):

当扩展到多元分类(multiclass)上时。可以将样本的true label编码成1-of-K个二元指示器矩阵Y,如果从label K集合中取出的样本i,对应的label为k,则yi,k=1,P为概率估计矩阵,pi,k=Pr(ti,k=1)。整个集合的log loss表示如下:

log_loss函数,通过给定一列真实值label和一个概率矩阵来计算log loss,返回值通过estimator的predict_proba返回。





![[机器学习] LR与SVM的异同](https://images2015.cnblogs.com/blog/995611/201703/995611-20170325122219002-256516069.png)