sklearn online learning
在 sklearn官方文档里以 online 为关键字进行检索

在线学习是可以通过小批量的数据迭代更新模型的权重,增量训练方法看 partial_fit,于是检索了一下 partial_fit,介绍如下:

不同与使用fit方法,partial_fit 方法不需要清空模型(不用清空模型原来就学习好的权重),只需要每次用小批量的数据进行 partial_fit,每个 batch 的数据的 shape 应保持一致。在可迭代训练的模型中(可以进行增量学习的模型),partial_fit 通常只执行一次迭代
通常,在使用 partial_fit 时,模型的参数不应该改变(每次使用 partial_fit 的模型参数保持一致)
partial_fit 使用的时候要返回对象
模型
这里使用逻辑回归模型,用 SGD 的方式进行模型训练,这里主要是为了说明 online learning 如何实现,所以尽量简化特征工程
数据集
https://www.kesci.com/home/dataset/5dd78542f41512002ceb25f3/document
实践
以用户行为数据为例,在原始数据集中取出 1/10作为增量学习的数据,测试进行增量学习之后的,模型特征对应的权重的改变,and 模型预测精度的改变。
具体步骤
- 进行简单的 预处理&特征工程
- 划分增量学习的数据(1/10) 和 另一部分数据(9/10)
- 讲另一部分数据(9/10)划分训练集和测试集,使用训练集训练 LR 模型(
fit) - 使用
partial_fit进行模型增量学习,并查看模型的特征权重、精度是否改变
import numpy as np
import pandas as pd
import warningswarnings.filterwarnings('ignore')
book_ratings = pd.read_csv('BX-Book-Ratings1.csv', sep=';', encoding='utf-8')
# books = pd.read_csv('BX-Books1.csv', sep=';')
users = pd.read_csv('BX-Users1.csv', sep=';')
book_ratings.sample(10)
| User-ID | ISBN | Book-Rating | |
|---|---|---|---|
| 535703 | 129110 | 0786886021 | 0.0 |
| 592016 | 142715 | 0679447652 | 0.0 |
| 745769 | 180495 | 0375413634 | 0.0 |
| 1146107 | 275922 | 0142001740 | 9.0 |
| 871705 | 210959 | 0445405198 | 5.0 |
| 836389 | 202113 | 0684838230 | 8.0 |
| 174358 | 37905 | 0140158618 | 8.0 |
| 1101442 | 264321 | 0812558626 | 7.0 |
| 586585 | 141651 | 3478086833 | 0.0 |
| 11062 | 626 | 3889820050 | 0.0 |
users.sample(10)
| User-ID | Location | Age | |
|---|---|---|---|
| 258196 | 258197 | seattle, washington, usa | 41.0 |
| 36019 | 36020 | wuxi, jiangsu, china | 24.0 |
| 15591 | 15592 | newark, delaware, usa | 23.0 |
| 267320 | 267321 | scottsbluff, nebraska, usa | 28.0 |
| 109842 | 109843 | braga, braga, portugal | 22.0 |
| 121294 | 121295 | madrid, n/a, spain | 56.0 |
| 16077 | 16078 | waldorf, maryland, usa | 37.0 |
| 75283 | 75284 | vidalia, georgia, usa | NaN |
| 195592 | 195593 | melbourne, victoria, australia | 26.0 |
| 177463 | 177464 | hanover, michigan, usa | 52.0 |
# 空值情况
book_ratings.isnull().sum(), users.isnull().sum()
(User-ID 0ISBN 0Book-Rating 8dtype: int64, User-ID 0Location 0Age 110765dtype: int64)
users.shape
(278858, 3)
# 填充用户评分的空值为0
book_ratings.fillna(0.0, inplace=True)
# 用户的年龄用均值填充,由于缺失数量大,但是特征重要
users['Age'].fillna(users['Age'].mean(), inplace=True)
# 只要国家,不要详情的地区了
users['Location'] = users['Location'].str.split(',').apply(lambda str_list:str_list[-1])
users.Location.value_counts()
usa 139711canada 21657united kingdom 18538germany 17041spain 13126... toscana 1wood 1bosnia 1pasco 1galiza neghra 1
Name: Location, Length: 755, dtype: int64
# 国家也不要了
users.drop('Location', axis=1, inplace=True)
dataset = pd.merge(book_ratings, users, on='User-ID')
dataset[dataset['Book-Rating'] > 0].shape
(433664, 4)
# 处理标签
dataset['Book-Rating'].apply(lambda x:1 if x>0 else 0).value_counts()
0 716116
1 433664
Name: Book-Rating, dtype: int64
dataset['Book-Rating'] = dataset['Book-Rating'].apply(lambda x:1 if x>0 else 0)
dataset.head()
| User-ID | ISBN | Book-Rating | Age | |
|---|---|---|---|---|
| 0 | 276725 | 034545104X | 0 | 34.751661 |
| 1 | 276726 | 0155061224 | 1 | 34.751661 |
| 2 | 276727 | 0446520802 | 0 | 16.000000 |
| 3 | 276729 | 052165615X | 1 | 16.000000 |
| 4 | 276729 | 0521795028 | 1 | 16.000000 |
dataset.shape[0] /10
114978.0
user_item, data = dataset[['User-ID', 'ISBN']], dataset[['Book-Rating', 'Age']]
# 取出 1/10 作为后面要增量训练的数据
online_learning_train, train = data[:114978], data[114978:]
from sklearn.model_selection import train_test_splitX, y = train.drop(columns=['Book-Rating']), train['Book-Rating']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
from sklearn.linear_model import SGDClassifier
%%time
lr_sgd = SGDClassifier(loss='log', warm_start=True).fit(X_train, y_train)
Wall time: 5.49 s
X_train.shape, y_train.shape
((827841, 1), (827841,))
lr_sgd.score(X_test, y_test)
0.6276883084252589
lr_sgd.coef_
array([[-0.01391971]])
def get_batch(online_learning_train):for row in online_learning_train.iterrows():# 生成器,每次返回一个要训练的样本yield row[1]['Book-Rating'], row[1]['Age']batch_generator = get_batch(online_learning_train)
# for i in range(10):
# print(next(batch_generator))
# 增量更新模型label, feature = next(batch_generator)
lr_sgd.partial_fit([[feature]], [label])
SGDClassifier(alpha=0.0001, average=False, class_weight=None,early_stopping=False, epsilon=0.1, eta0=0.0, fit_intercept=True,l1_ratio=0.15, learning_rate='optimal', loss='log', max_iter=1000,n_iter_no_change=5, n_jobs=None, penalty='l2', power_t=0.5,random_state=None, shuffle=True, tol=0.001,validation_fraction=0.1, verbose=0, warm_start=True)
lr_sgd.coef_
array([[-0.01697226]])
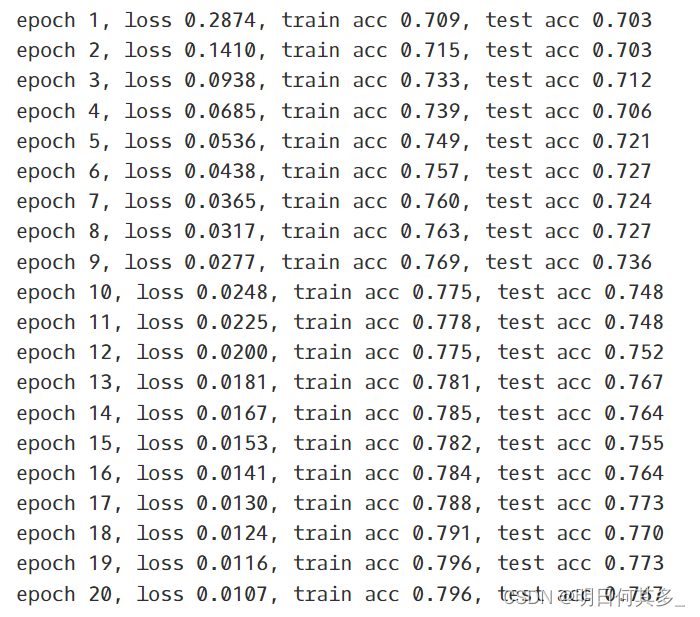
for i in range(20):label, feature = next(batch_generator)lr_sgd = lr_sgd.partial_fit([[feature]], [label])# 注意要返回这个对象print(lr_sgd.score(X_test, y_test))print(lr_sgd.coef_)
0.6276883084252589
[[-0.00304325]]
0.6276883084252589
[[-0.00588775]]
0.6276883084252589
[[-0.00175116]]
0.6135455472287049
[[0.00449768]]
0.6276883084252589
[[-0.00060454]]
0.6276883084252589
[[-0.00468685]]
0.6276883084252589
[[0.00109888]]
0.6250839530153024
[[0.00402928]]
0.4302066572929199
[[0.00872931]]
0.3764235773889767
[[0.01224813]]
0.4302066572929199
[[0.00875256]]
0.5881011398282768
[[0.00540715]]
0.42067346021714236
[[0.00906837]]
0.5847188600750866
[[0.00570941]]
0.6267026154686148
[[0.00249447]]
0.6276883084252589
[[-0.00058331]]
0.6276883084252589
[[-0.00353084]]
0.6276883084252589
[[-0.00635496]]
0.6276883084252589
[[-0.00906232]]
0.6276883084252589
[[-0.01165938]]



![[机器学习] LR与SVM的异同](https://images2015.cnblogs.com/blog/995611/201703/995611-20170325122219002-256516069.png)