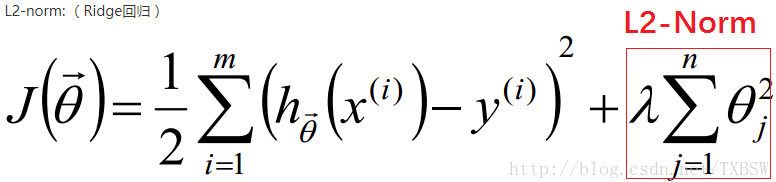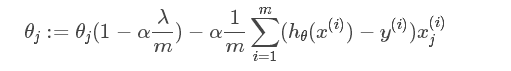前言
今天还是机器学习的基础知识内容,也是最基础的哈。首先说一下什么是正则化,其实它就是一个减少方差的策略。那么什么是方差呢?在这里也引入一个和方差相辅相成的概念--偏差。
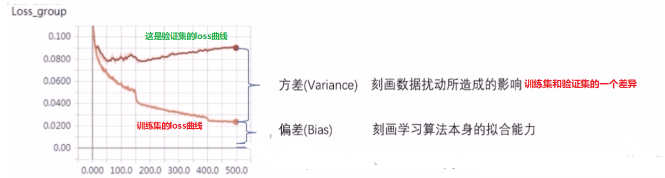
- 偏差度量了学习算法的期望预测与真实结果的偏离程度, 即刻画了学习算法本身的拟合能力
- 方差度量了同样大小的训练集的变动所导致的学习性能的变化,即刻画了数据扰动所造成的影响
我们通常所说的过拟合现象,也就是指的高方差,就是模型在训练集上训练的超级好,几乎全部都能拟合。 但是这种情况如果换一个数据集往往就会非常差, 正则化的思想就是在我们的目标函数中价格正则项, 即:
![]()
在这里正则项有两种,分别是L1和L2,先来看一下两者的表达式:

如果加上这种正则项,就是希望我们的代价函数小,同时也希望我们这里的小,这样就说明每个样本的权重都很小,这样模型就不会太多的关注某种类型的样本, 模型参数也不会太复杂,有利于缓解过拟合现象。
L1正则化
先看一下带L1正则化的损失函数:
![]()

ps:懒得打了,直接贴一位大佬总结的话吧,反正我是超级赞同的,写的很好。不过在这里我需要强调的一点就是正则化就是相当于给原来的损失函数加了一个约束,同时满足损失函数最小值的参数可能有很多选择,加了正则化之后就会选择同时满足损失函数和正则化函数的参数值。


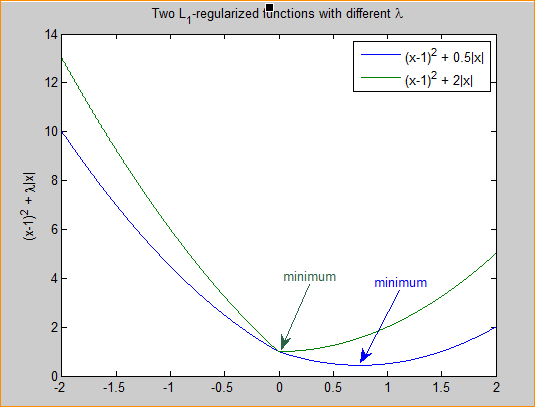
在这里需要注意的是,因为L1正则化图形的缘故,满足最优解的参数往往都在坐标轴上面,所以L1正则项往往能够使得模型产生稀疏的解,这是因为加上L1之后,我们参数的解往往会发生在坐标轴上导致某些参数的值为0。
L2正则化
先看一下L2正则化的损失函数:
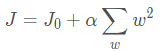
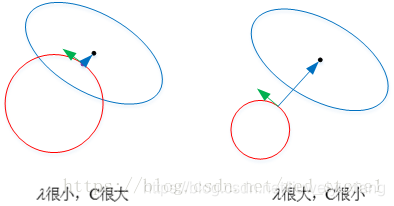
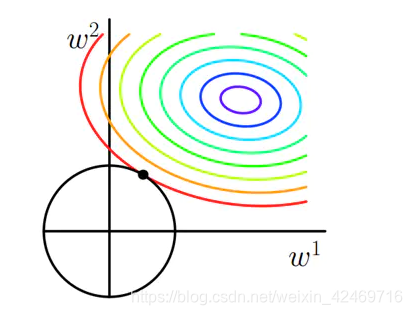
下图所示,这是L2正则。彩色的圈还是Cost等高线,下面黑色的圆圈是L2正则等高线() , 和上面的分析一样,如果我们在A’, B’, C’点确定最优解的话,依然是C’点, 因为它在Cost相等的情况下正则最小。但是我们发现L2正则下不过出现某个参数为0的情况,而是w1和w2都比较小。所以L2正则项的最优的参数值很小概率出现在坐标轴上,因此每一维的参数都不会是0。当最小化||w||时,就会使每一项趋近于0。
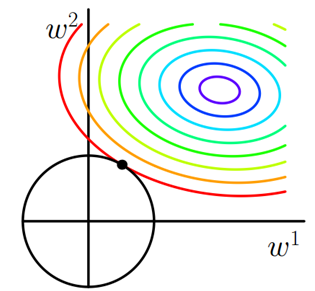
在Pytorch中, L2正则项又叫做weight decay(权值衰减)。那么为啥这个东西叫做权值衰减呢? 怎么衰减了? 我们这样看:首先,我们原来的时候, 参数的更新公式是这样的:
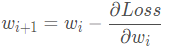
而现在,我们的Obj加上了一个L2正则项 , 那么参数的更新方式也就变成了下面这个:
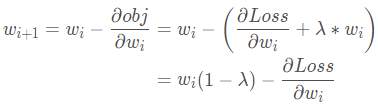
我们知道λ 的取值是0-1的,那么就是说每一次迭代之后,这个参数本身也会发生一个衰减。也就是说我们加上L2正则项与没有加L2正则项进行一个对比的话,加入L2正则项,这里的
就会发生数值上的一个衰减。故这就是这个L2正则项称为权值衰减的原因。
对于L2的代码实现,在API中为了求解方便,L2正则化项并不是加入损失函数中一起求导的,而是将损失函数求导完毕之后,再加上weight_decay的。可能有小伙伴疑问了,我为什么要管这些,直接调用API不久好了么,其实确实是这样,但是在优化器选择上面Adam+L2就会出现问题,不管是动量预测还是环境感知都不准确,所以才出现了新的优化器--AdamW。由此可见了解底层原理还是挺重要的。
接下来看一位大佬调试出来的代码,看看“后台”是如何运行的:

好了,L2正则化的使用和内部实现机制就到这里吧,要知道L2正则化干啥用,怎么用差不多就行了。 一般是在模型过拟合的时候用到这个方式, 当然除了L2正则化,在模型发生过拟合的时候还有其他的方式,比如Dropout,也是常用的一种方式。
总结
L1正则化的特点:
不容易计算, 在零点连续但不可导, 需要分段求导
L1模型可以将 一些权值缩小到零(稀疏)
执行隐式变量选择。 这意味着一些变量值对结果的影响降为0, 就像删除它们一样
其中一些预测因子对应较大的权值, 而其余的(几乎归零)
由于它可以提供稀疏的解决方案, 因此通常是建模特征数量巨大时的首选模型
它任意选择高度相关特征中的任何一个, 并将其余特征对应的系数减少到0
L1范数对于异常值更具提抗力L2正则化的特点:
容易计算, 可导, 适合基于梯度的方法
将一些权值缩小到接近0
相关的预测特征对应的系数值相似
当特征数量巨大时, 计算量会比较大
对于有相关特征存在的情况, 它会包含所有这些相关的特征, 但是相关特征的权值分布 取决于相关性。
对异常值非常敏感
相对于L1正则会更加准确
参考: 系统学习Pytorch笔记九:正则化与标准化大总结