
相关文章

何凯明最新一作MAE解读系列1
导读
凯明出品,必属精品。没有花里胡哨的修饰,MAE就是那么简单的强大,即结构简单但可扩展性能强大。MAE通过设计一个非对称的编码解码器,在预训练阶段,通过高比例的掩码原图,将可见部分输入到编码器中&…

基于CIFAR数据集 进行 MAE实现及预训练可视化 (CIFAR for MAE,代码权重日志全部开源,自取)
基于CIFAR数据集 进行 MAE实现及预训练可视化 (CIFAR for MAE,代码权重日志全部开源,自取) 文章目录 基于CIFAR数据集 进行 MAE实现及预训练可视化 (CIFAR for MAE,代码权重日志全部开源,自取&a…

PyTorch笔记 - MAE(Masked Autoencoders) PyTorch源码
欢迎关注我的CSDN:https://blog.csdn.net/caroline_wendy 本文地址:https://blog.csdn.net/caroline_wendy/article/details/128382935 Paper:MAE - Masked Autoencoders Are Scalable Vision Learners 掩码的自编码器是可扩展的视觉学习器 …

何凯明新作MAE 学习笔记
【MAE与之前AI和CV领域最新工作的关系】
学习MAE视频【李沐】 He, K., Chen, X., Xie, S., Li, Y., Dollr, P., & Girshick, R. (2021). Masked autoencoders are scalable vision learners. arXiv preprint arXiv:2111.06377.
【Transformer】
Transforme纯注意力&…
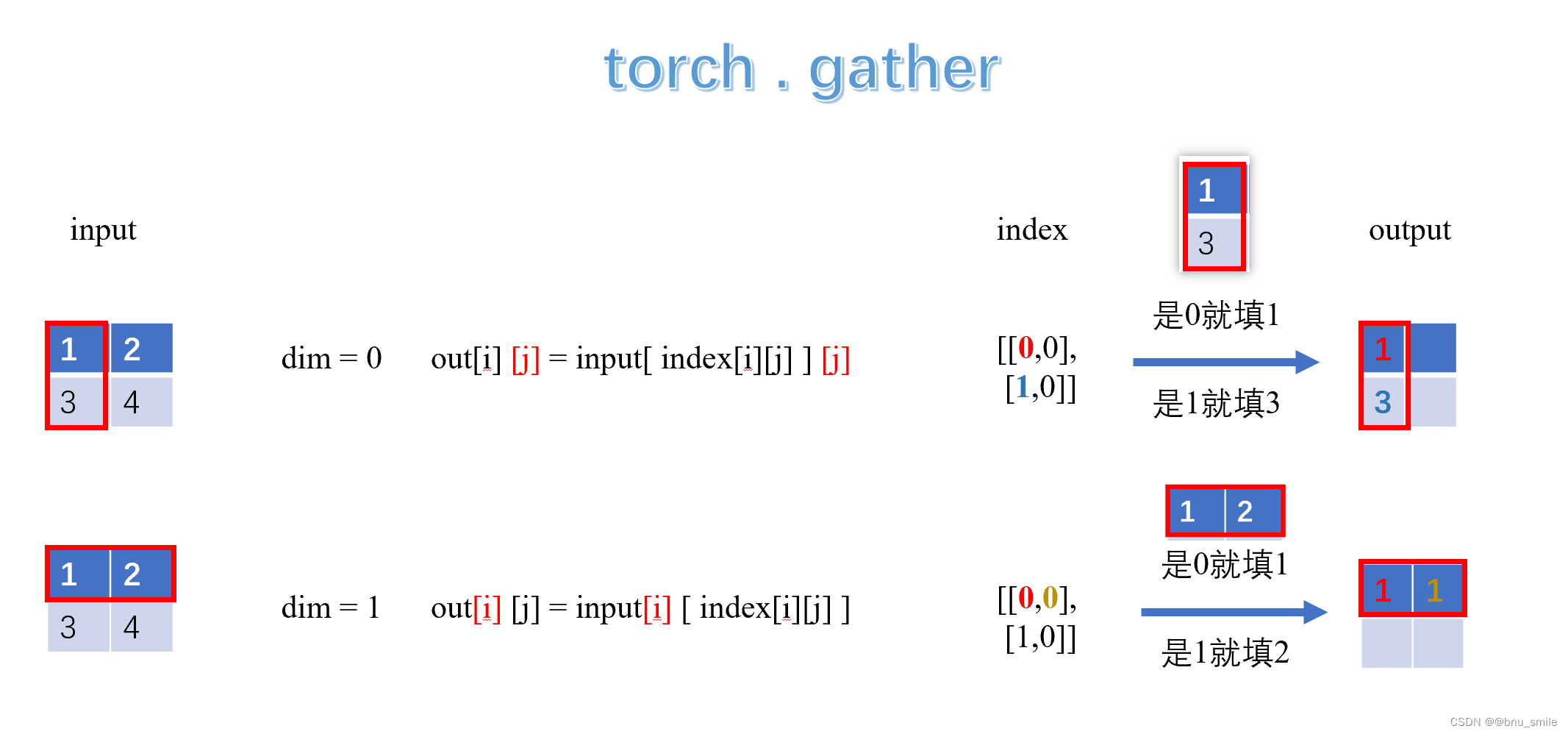
MAE 代码实战详解
MAE 代码实战详解 if__name__"__main__"model.forwardmodel.forward.encordermodel.forward.decordermodel.forward.loss大小排序索引-有点神奇torch.gather if__name__“main”
MAE 模型选择
def mae_vit_base_patch16_dec512d8b(**kwargs):model MaskedAutoenco…
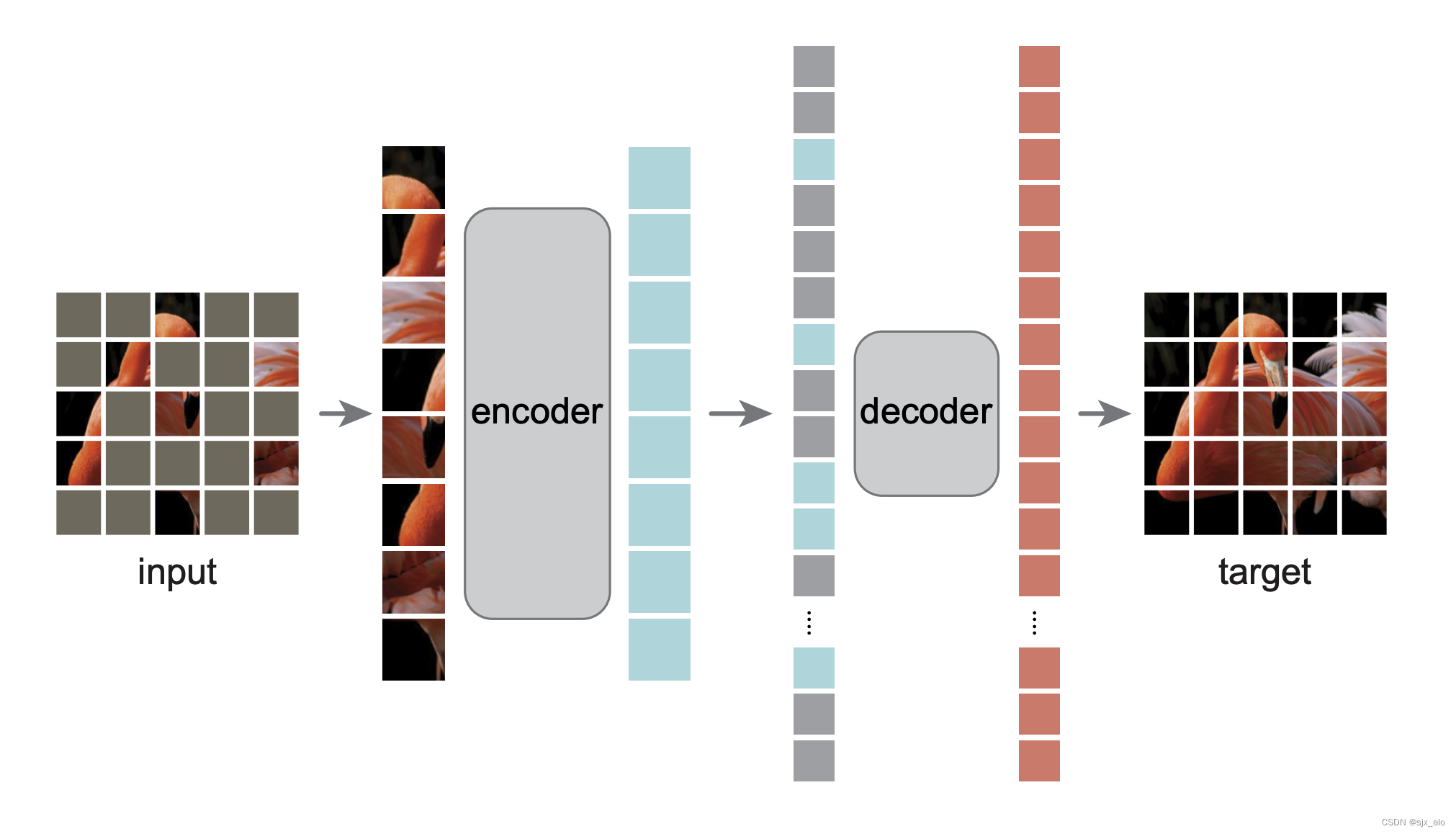
MAE(Masked Autoencoders) 详解
MAE详解 0. 引言1. 网络结构1.1 Mask 策略1.2 Encoder1.3 Decoder 2. 关键问题解答2.1 进行分类任务怎么来做?2.2 非对称的编码器和解码器机制的介绍2.3 损失函数是怎么计算的?2.4 bert把mask放在编码端,为什么MAE加在解码端? 3. …
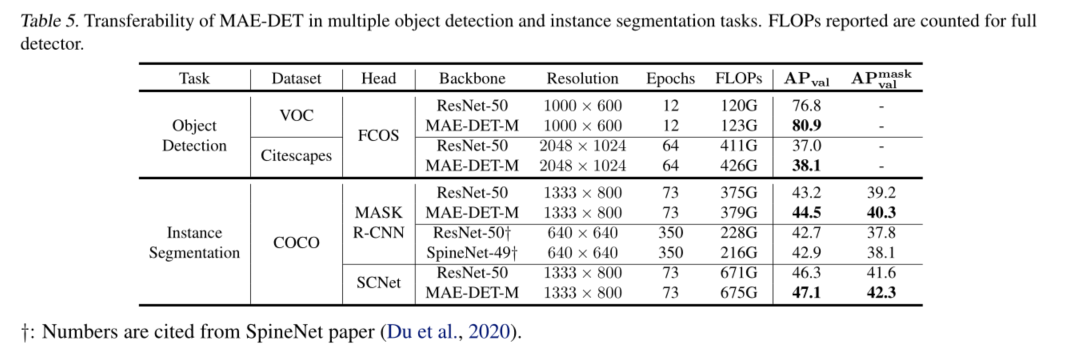
MAE-DET学习笔记
MAE-DET学习笔记
MAE-DET: Revisiting Maximum Entropy Principle in Zero-Shot NAS for Efficient Object Detection
Abstract
在对象检测中,检测主干消耗了整个推理成本的一半以上。最近的研究试图通过借助神经架构搜索(NAS)优化主干架构…


RMSE(均方根误差)、MSE(均方误差)、MAE(平均绝对误差)、SD(标准差)
RMSE(Root Mean Square Error)均方根误差
衡量观测值与真实值之间的偏差。
常用来作为机器学习模型预测结果衡量的标准。 MSE(Mean Square Error)均方误差
MSE是真实值与预测值的差值的平方然后求和平均。
通过平方的形式便于…
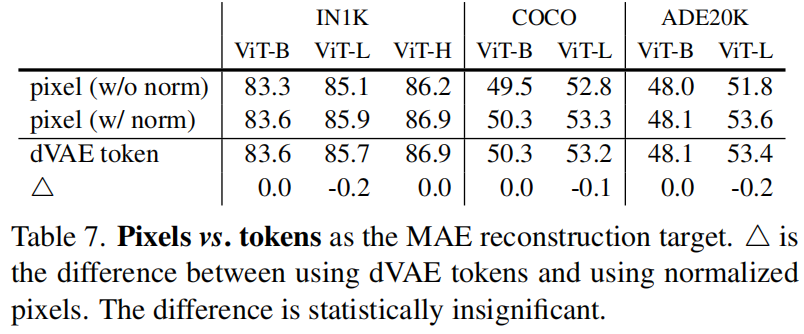
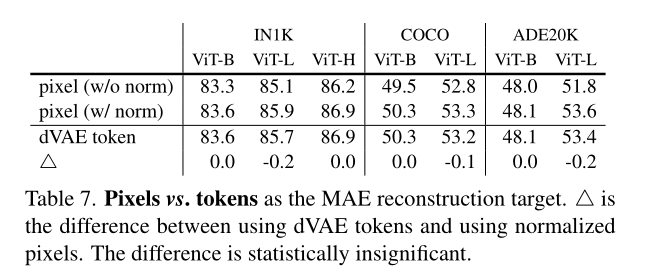
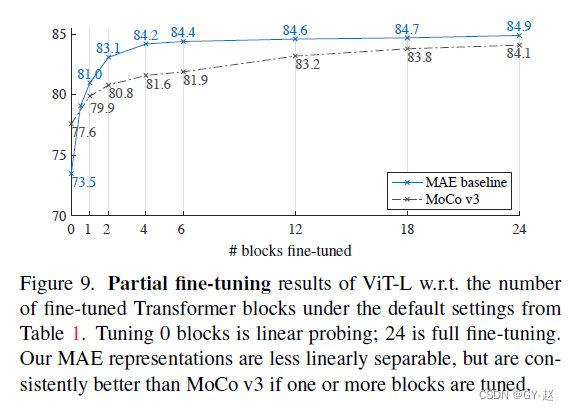
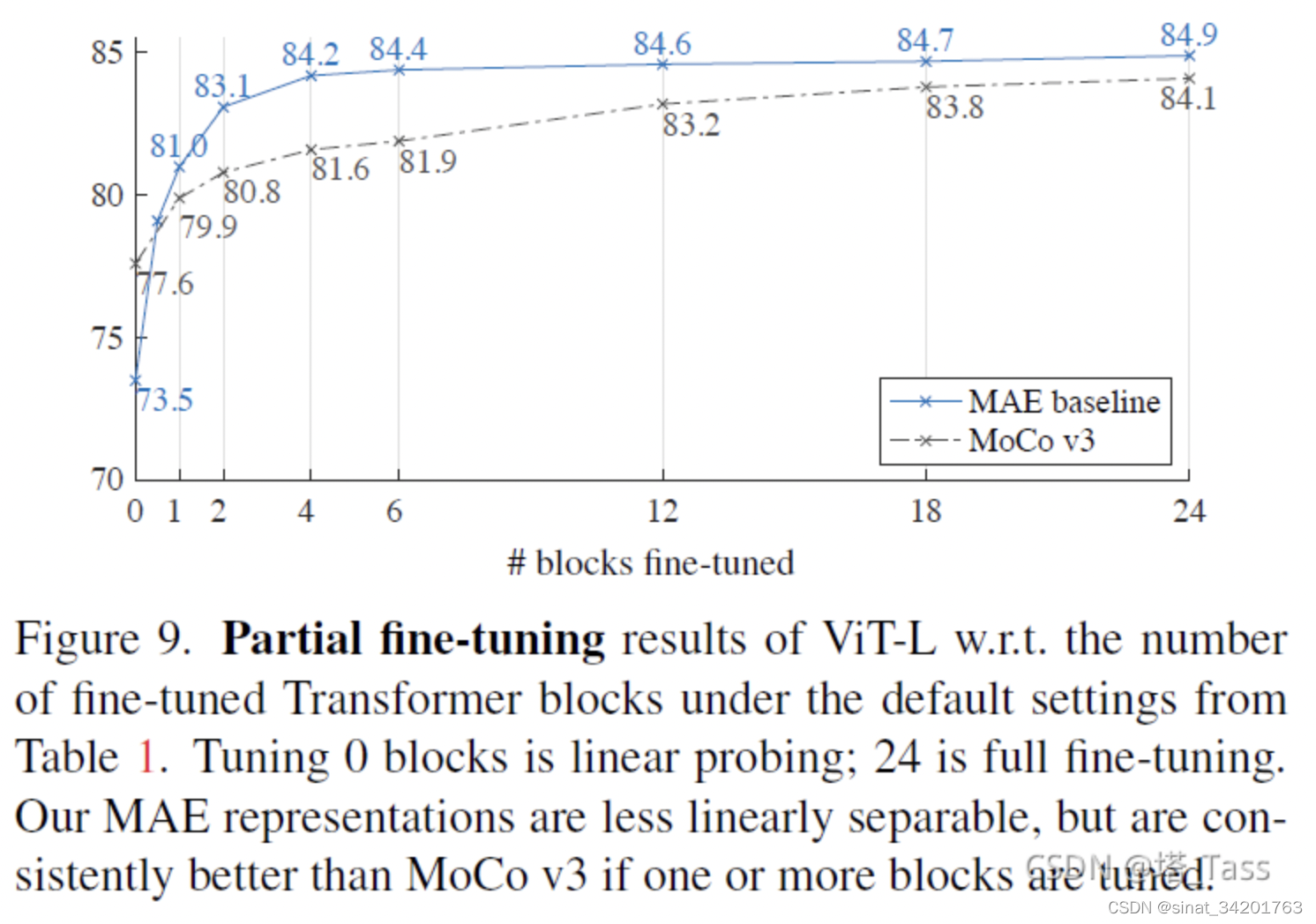
【深度学习】详解 MAE
目录
摘要
一、引言
二、相关工作
三、方法
四、ImageNet 实验
4.1 主要属性
4.2 与先前结果的对比
4.3 部分微调
五、迁移学习实验
六、讨论与结论
七、核心代码 Title:Masked Autoencoders Are Scalable Vision LearnersPaper:https://arx…


深度学习:MAE 和 RMSE 详解
平均绝对误差MAE(mean absolute error) 和均方根误差 RMSE(root mean squared error)是衡量变量精度的两个最常用的指标,同时也是机器学习中评价模型的两把重要标尺。 那两者之间的差异在哪里?它对我们的生活有什么启示…
RMSE、MAE等误差指标整理
1 MAE Mean Absolute Error ,平均绝对误差是绝对误差的平均值 for x, y in data_iter:ymodel(x)d np.abs(y - y_pred)mae d.tolist()#maesigma(|pred(x)-y|)/m
MAE np.array(mae).mean() MAE/RMSE需要结合真实值的量纲才能判断差异。
下图是指,假如g…


linux的crontab用法与实例
linux的crontab用法与实例
crontab的适用场景
在Linux系统的实际使用中,可能会经常让系统在某个特定时间执行某些任务的情况,比如定时采集服务器的状态信息、负载状况;定时执行某些任务/脚本来对远端进行数据采集或者备份等操作。 首先通过…