欢迎关注我的CSDN:https://blog.csdn.net/caroline_wendy
本文地址:https://blog.csdn.net/caroline_wendy/article/details/128382935
Paper:MAE - Masked Autoencoders Are Scalable Vision Learners
-
掩码的自编码器是可扩展的视觉学习器
-
Kaiming He,FAIR
Code:https://github.com/facebookresearch/mae
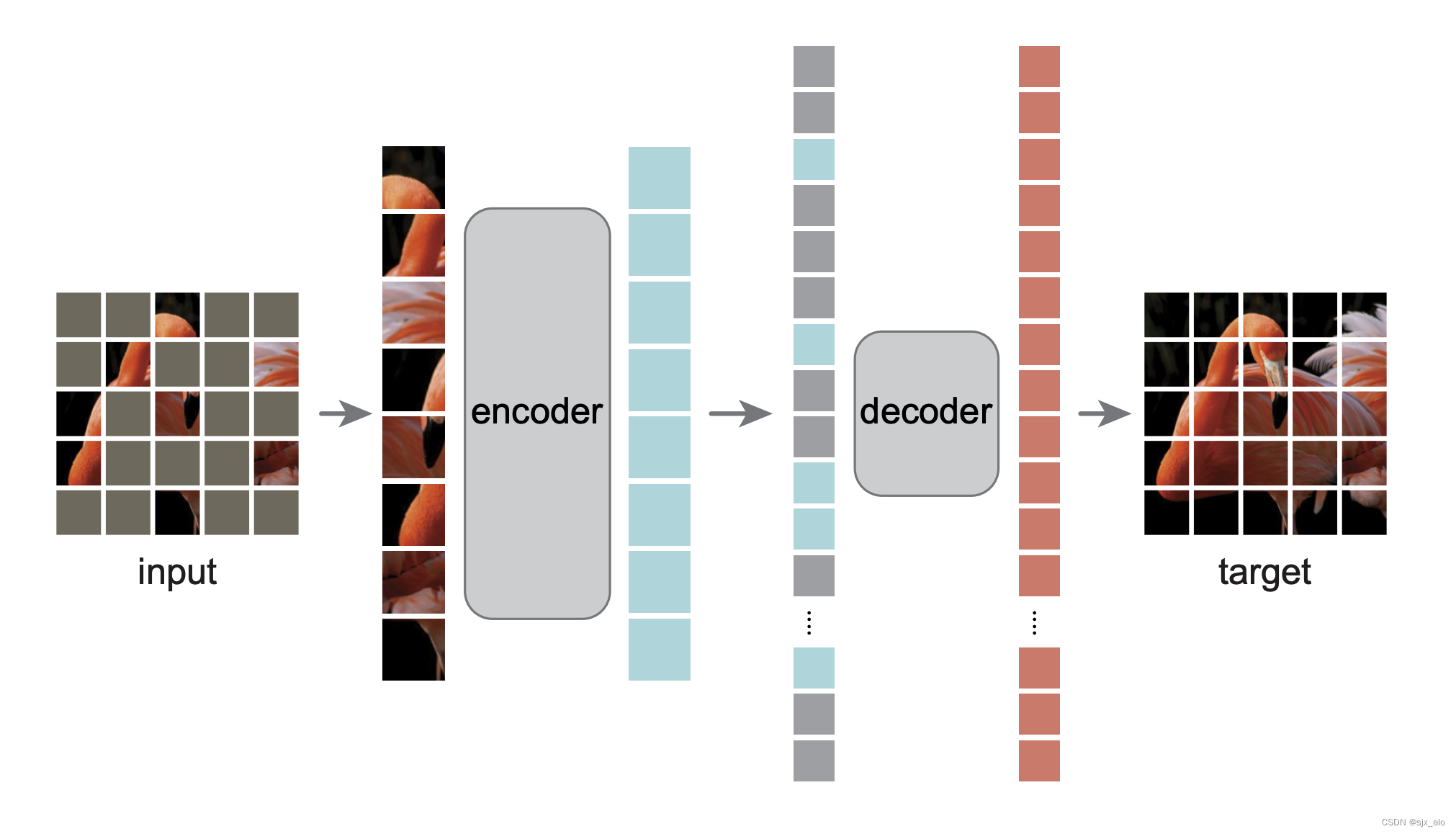
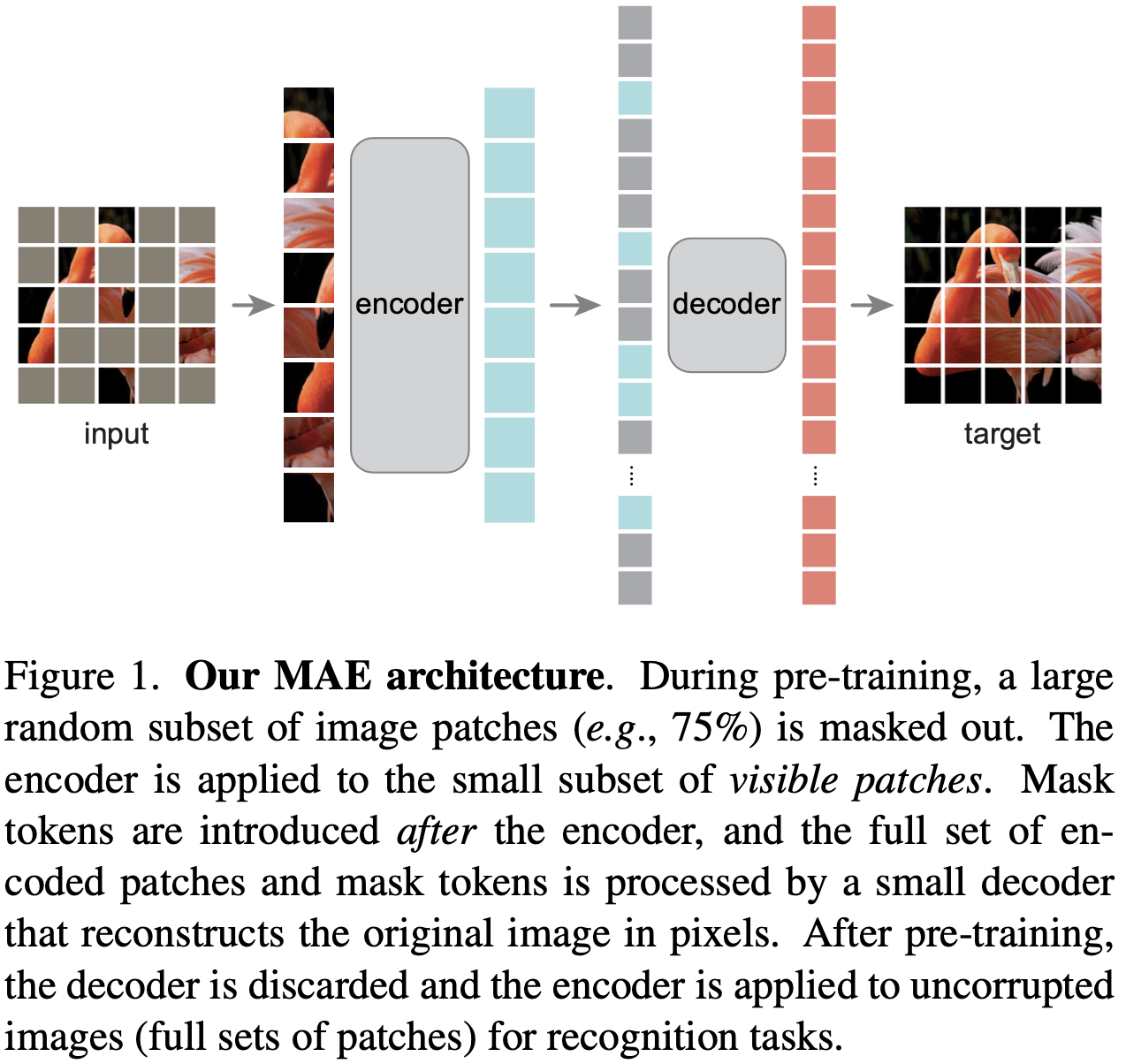
MAE结构:
ViT的不同类型:An Image is worth 16X16 words: Transformers for Image recognition at scale
- 一张图片相当于 16X16 个字: 用于大规模图像识别的Transformers,Google Research

源码框架
data preprocesss:
- Image2tensor: 读取图像
- RGB 3channels
PIL.Image.open + convert("RGB"),ortorchvision.datasets.ImageFolder- ImageFolder,需要固定的文件夹格式
- shape: (C, H, W), dtype: uint8
- unsigned integer 8bit, binary digit
- 挑选颜色,#000000(黑色) / #FFFFFF(白色),16进制,256=16x16
- min-max归一化,正态分布归一化
- augment: Crop/Resize/Flip,500x500,随机截取100x100 -> 224x224
- convert:
torchvision.transforms.ToPILImagetorchvision.transforms.PILToTensor,uint8转换为0~1之间的浮点数- [0, 1]
- normalize:
- image=(image-mean)/std, global-level,均值为0,方差为1,mv归一化
- imagenet1k:
mean [0.485,0.456,0.406],std [0.229, 0.224, 0.225]
model:
- encoder: 特征提取/分类任务,标准的ViT
- Image2patch2embedding
- position embedding,正余弦固定的embedding
- random masking (shuffle),随机mask,划分之后随机打散,取前面25%
- class token,添加class token
- Transformer Blocks (ViT-base / ViT-large / ViT-huge),MLP size是Hidden size的4倍,layers=blocks
- decoder:
- projection_layer
- unshuffle,还原到mask当中
- position embedding,解码器与编码器不同
- Transformer Blocks (shallow),轻量级的ViT
- regression layer,回归层MLP,把每个patch投影到像素空间
- mse loss function (norm pixel),重建相同图像
- forward functions
- forward encoder,编码器需要单细使用
- forward decoder,接收encoder的输入
- forward loss,为整体前向推理服务
traning:
- dataset,构建数据集,类似于torchvision.datasets.ImageFolder,xy元组的生成器
data_loader,取sample拼成mini_batch- model,模型
- optimizer,优化器
- load_model,加载模型
model.state_dict()optimizer.state_dict(),parameter的辅助变量- epoch,影响学习率
train_one_epoch,核心的训练函数save_modelmodel.state_dict()optimizer.state_dict()- epoch/loss
- config
finetuning: 只需要用到编码器encoder,不需要使用解码器decoder
- strong augmentation,微调需要增加强增强
- bulder encoder + BN + MLP classifier head,注意额外增加BN
- interpolate(差值) position embedding,预训练和实际的patch数量不同
- load pre-trained model (strict=False),A模型加载B模型的参数,只要有相同的层,就会加载,不同的层会提示,使用随机。
- update all parameters
- AdamW optimizer
- label smoothing cross-entropy loss
linear probing:
- weak augmentation,增强较弱
- bulder encoder + BN(no affine仿射,去掉w和b) + MLP classifier head
- interpolate(差值) position embedding
- load pre-trained model (strict=False)
- only update parameter of MLP classifier head
- LARS(Layer-wise Adaptive Rate Scaling) optimizer
- 各个层更新参数所使用的学习率,根据当前情况有所调整,而不是所有层使用相同的学习率,也就是每层有自己的local lr。
- cross-entropy loss
evaluation:
with torch.no_grad()-> efficient- model.eval() -> accurate BN/dropout,BN和Dropout都起到正确作用
top_k:top_1ortop_5
源码:
main文件、engine文件、models文件
-
models_mae.py -
models_vit.py
models_mae.py
models_mae.py: 默认使用ViT-large,hidden_size=1024,mlp_ratio扩大4倍
img_size: 图像尺寸patch_size: patch尺寸self.cls_token: 可训练的类别tokenself.pos_embed: 固定的位置编码,不可训练,requires_grad=False,正余弦编码,cls_token也需要1个位置编码- 编码器encoder的Transformer Block,即self.blocks
- 编码器的embedding映射到解码器的embedding
self.mask_token表示被遮挡的patch- 解码器decoder也需要使用
cls_token - 回归的像素值,
patch_size**2 * in_chans,图像面积乘以通道 - 初始化
pos_embed和decoder_pos_embed,数据相同。 self.cls_token、self.mask_token,初始化整体分布def initialize_weights(self),初始化所以参数- patchify图像变成块、unpatchify块变成图像
def forward_encoder(self, x, mask_ratio):,前向处理encoderdef forward_decoder(self, x, ids_restore):,前向处理decoderx, mask, ids_restore = self.random_masking(x, mask_ratio),随机掩码操作- 随机噪声矩阵:
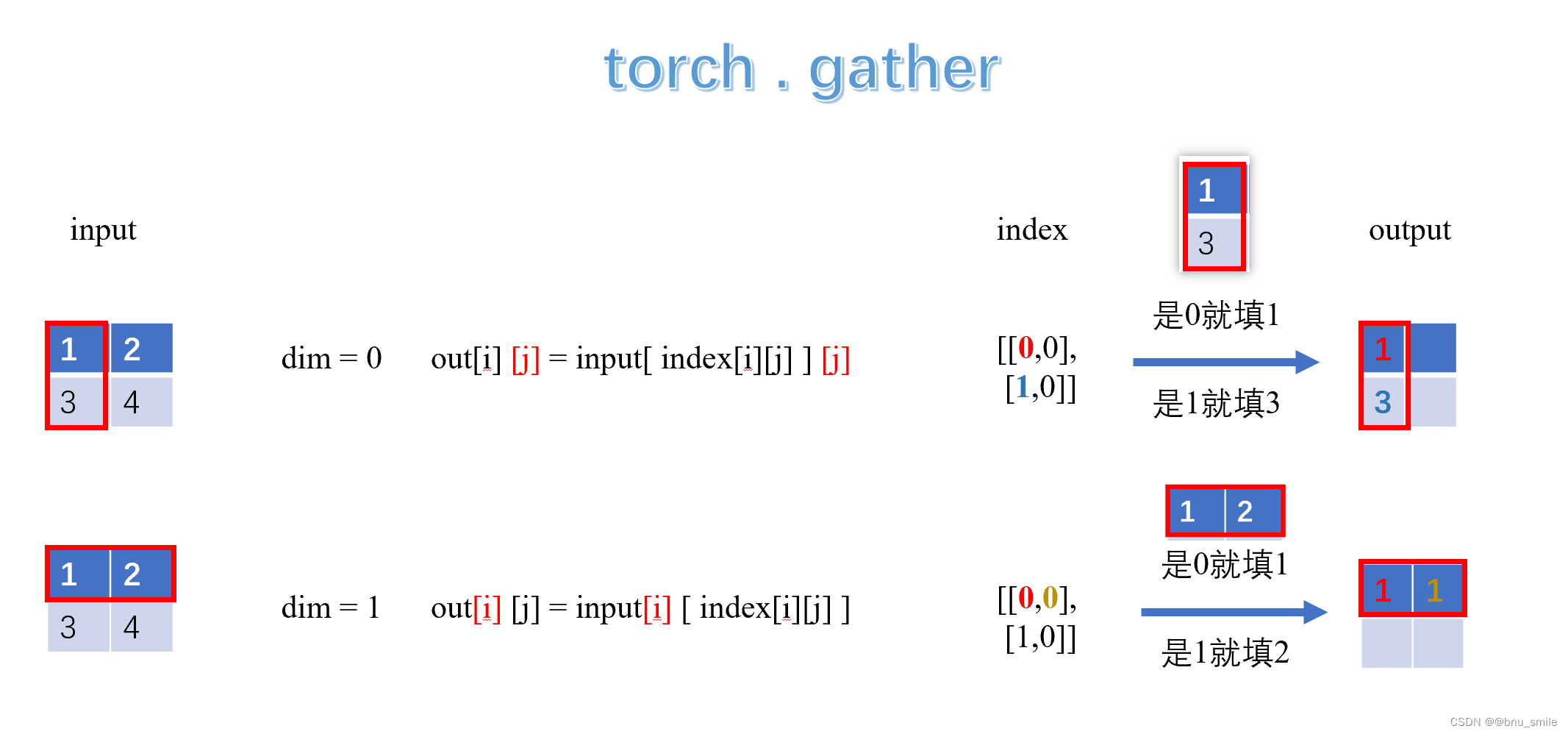
noise = torch.rand(N, L, device=x.device) # noise in [0, 1],噪声只是为了排序 ids_keep = ids_shuffle[:, :len_keep],序列长度需要保留的索引mask = torch.gather(mask, dim=1, index=ids_restore),获取被掩码的位置- 位置编码:
x = x + self.pos_embed[:, 1:, :]和cls_token = self.cls_token + self.pos_embed[:, :1, :] - 使用重复的
mask_token,mask_tokens = self.mask_token.repeat(x.shape[0], ids_restore.shape[1] + 1 - x.shape[1], 1) pos_embed和decoder_pos_embed,编码不同,维度不同,长度也不同。- L2 Loss:
loss = (pred - target) ** 2,支持归一化target,target = (target - mean) / (var + 1.e-6)**.5 - 只计算mask部分的loss,
loss = (loss * mask).sum() / mask.sum() # mean loss on removed patches
支持3种模式:
# set recommended archs
mae_vit_base_patch16 = mae_vit_base_patch16_dec512d8b # decoder: 512 dim, 8 blocks
mae_vit_large_patch16 = mae_vit_large_patch16_dec512d8b # decoder: 512 dim, 8 blocks
mae_vit_huge_patch14 = mae_vit_huge_patch14_dec512d8b # decoder: 512 dim, 8 blocks
获取random_mask的ids:
import torchx = torch.rand(5)
print(f"[Info] x: {x}")
idx_shuffle = torch.argsort(x)
print(f"[Info] idx_shuffle: {idx_shuffle}")
idx_restore = torch.argsort(idx_shuffle)
print(f"[Info] idx_restore: {idx_restore}")
main_pretrain.py
从命令行获取参数:
args = get_args_parser()
args = args.parse_args()
main(args)
固定随机种子:
seed = args.seed + misc.get_rank()
torch.manual_seed(seed)
np.random.seed(seed)
数据增强:
transform_train = transforms.Compose([transforms.RandomResizedCrop(args.input_size, scale=(0.2, 1.0), interpolation=3), # 3 is bicubictransforms.RandomHorizontalFlip(),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])])
dataset_train = datasets.ImageFolder(os.path.join(args.data_path, 'train'), transform=transform_train)
print(dataset_train)
DataLoader:
data_loader_train = torch.utils.data.DataLoader(dataset_train, sampler=sampler_train,batch_size=args.batch_size,num_workers=args.num_workers,pin_memory=args.pin_mem,drop_last=True,
)
逻辑:misc = miscellaneous混杂的
misc.init_distributed_mode(args),分布式模式的初始化torch.distributed.barrier(),放在最后一行,等待所有进程初始化完成device = torch.device(args.device),初始化设备- 有效的batch_size,
eff_batch_size = args.batch_size * args.accum_iter * misc.get_world_size(),累计更新 - 包裹DDP:
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[args.gpu], find_unused_parameters=True) - 传入参数组:
param_groups = optim_factory.add_weight_decay(model_without_ddp, args.weight_decay) - 训练单轮:
train_one_epoch model.train(True),accum_iter累计更新步骤with torch.cuda.amp.autocast():,支持自动混合精度的计算loss_scaler,loss的更新逻辑
更新日志:
if args.output_dir and misc.is_main_process():if log_writer is not None:log_writer.flush()with open(os.path.join(args.output_dir, "log.txt"), mode="a", encoding="utf-8") as f:f.write(json.dumps(log_stats) + "\n")
注释掉:model_mae.py中qk_scale参数,准备训练集,类似ImageFolder的组织形式,即可训练。
main_finetune.py
逻辑:
- 构建训练集和测试集:
dataset_train = build_dataset(is_train=True, args=args)、dataset_val = build_dataset(is_train=False, args=args) - 使用
build_transform,构建transform,训练(is_train=True)较多,验证(is_train=False)较少。 - DataLoader:
data_loader_train和data_loader_val。 mixup_fn,用于CV的数据增强技巧。models_vit.py中定制的VisionTransformer,参数格式一样,输出略有不同。msg = model.load_state_dict(checkpoint_model, strict=False),导入预训练的模型。- 确保新增参数没有导入:
assert set(msg.missing_keys) == {'head.weight', 'head.bias', 'fc_norm.weight', 'fc_norm.bias'} interpolate_pos_embed(model, checkpoint_model),位置编码进行差值。- Loss - MixUp: SoftTargetCrossEntropy(), smoothing: LabelSmoothingCrossEntropy(), plain: CrossEntropyLoss()
- 加载模型: misc.load_model(args=args, model_without_ddp=model_without_ddp, optimizer=optimizer, loss_scaler=loss_scaler)
load_model(加载模型)逻辑:
def load_model(args, model_without_ddp, optimizer, loss_scaler):if args.resume:if args.resume.startswith('https'):checkpoint = torch.hub.load_state_dict_from_url(args.resume, map_location='cpu', check_hash=True)else:checkpoint = torch.load(args.resume, map_location='cpu')model_without_ddp.load_state_dict(checkpoint['model'])print("Resume checkpoint %s" % args.resume)if 'optimizer' in checkpoint and 'epoch' in checkpoint and not (hasattr(args, 'eval') and args.eval):optimizer.load_state_dict(checkpoint['optimizer'])args.start_epoch = checkpoint['epoch'] + 1if 'scaler' in checkpoint:loss_scaler.load_state_dict(checkpoint['scaler'])print("With optim & sched!")
与main_linprobe.py的不同:把编码器固定,只训练分类层,同时数据增强较弱。
for _, p in model.named_parameters():p.requires_grad = False
for _, p in model.head.named_parameters():p.requires_grad = True
That’s all.