理解PG如何执行一个查询
PG服务器收到客户端发来的查询后,查询的文本交给解析器。解析器扫描查询并检查它的语法。若语法正确,解析器会将查询文本转换成解析树。解析树是一种以正式、明确的形式表示查询含义的数据结构。给定查询:
SELECT customer_name, balance FROM customers WHERE balance > 0 ORDER BY balance;解析器可能会提出这样的解析树:

解析器完成解析后,解析树移交给规划器/优化器。
计划器负责遍历分析树,并找到所有可能执行查询的计划。如果定义了一个有用的索引,该计划可能包括对整个表的顺序扫描和索引扫描。如果查询涉及两个或多个表,则规划器可推荐许多不同方法来连接这些表。执行计划是根据查询算子制定的。每个算子将一个或多个输入集转换成中间结果集。例如SeqScan算子将输入集(物理表)转换为结果集,过滤掉任何不符合查询约束的行。Sort算子通过一个或多个排序键对输入集重新排序来生成结果集。稍后更加详细描述每个查询算子。下面是一个简单执行计划示例:

可以看到复杂的查询分解为简单步骤。树底部的查询算子输入集是物理表。上层算子输入集是下层算子的结果集。生成所有可能的执行计划后,优化器将搜索成本最低的计划。每个计划都分配了一个估计的执行成本。成本估算以磁盘IO为单位进行衡量。从磁盘读取单个8192(8KB)块的成本为一个单元。CPU时间也是磁盘IO为单位来衡量,但通常是分数。例如处理单个元组需要的CPU时间量假定为单个磁盘IO的1/100th.你可以调整许多成本估算。每个算子都有不同的成本估算。例如,对整个表进行顺序扫描的成本计算为表中8K块的数量,加上一些CPU开销。
选择代价最低的执行计划后,查询执行器从计划的开头开始,并向最顶层的算子要结果集。每个算子将输入集转成结果集。当最顶层算子完成计算,其结果集返回客户端应用。
EXPLAIN
EXPLAIN语句让您深入了解 PostgreSQL 查询计划器/优化器如何决定执行查询。首先,您应该知道EXPLAIN语句只能用于分析SELECT、INSERT、DELETE、UPDATE和DECLARE...CURSOR命令。
EXPLAIN命令的语法是:
EXPLAIN [ANALYZE][VERBOSE] query;下面看一个简单例子:
perf=# EXPLAIN ANALYZE SELECT * FROM recalls;
NOTICE: QUERY PLAN:Seq Scan on recalls (cost=0.00..9217.41 rows=39241 width=1917)(actual time=69.35..3052.72 rows=39241 loops=1)
Total runtime: 3144.61 msec执行计划的格式起初可能有点神秘。对于执行计划中每个步骤,EXPLAIN打印以下信息:
1)需要的操作类型
2)估计的执行成本
3)如果指定EXPLAIN ANALYZE,则执行的实际成本。如省略ANALYZE关键字,则计划查询但不执行查询,不显示实际成本。
在这里个例子中,PG决定对recalls表(Seq Scan on recalls)。PG可以使用多个算子来执行查询。稍后更详细解释算子类型。
成本估算包含3个数据行。第一组数字(cost=0.00..9217.41)是对该操作的代价估计。代价根据磁盘读取来衡量。给出了2个数字,第一个数组表示操作返回结果集第一行的速度;第二个(通常最重要)表示整个操作需要执行多长时间。成本估算的第二个数据项(rows=39241)显示PG期望从此操作返回多少行。最后的数据项(width=1917)是对结果集中平均行的宽度(以字节为单位)的估计。
如果在EXPLAIN命令中加了ANALYZE关键字,PG将执行查询并显示实际执行成本。
下面一个简单案例。PostgreSQL 只需要一个步骤来执行这个查询(对整个表的顺序扫描)。许多查询需要多个步骤,EXPLAIN命令将显示每个步骤。让我们看一个更复杂的例子:
perf=# EXPLAIN ANALYZE SELECT * FROM recalls ORDER BY yeartxt;
NOTICE: QUERY PLAN:Sort (cost=145321.51..145321.51 rows=39241 width=1911)(actual time=13014.92..13663.86 rows=39241 loops=1)->Seq Scan on recalls (cost=0.00..9217.41 rows=39241 width=1917)(actual time=68.99..3446.74 rows=39241 loops=1)
Total runtime: 16052.53 msec该实例显示了2步查询计划。这种情况下,第一步实际上列在计划的末尾。当阅读查询计划时,务必记住计划中每个步骤都会产生一个中间结果集。每个中间结果集都会送入计划的下一步。
查看这个计划,PostgreSQL 首先通过对整个recalls表执行顺序扫描(Seq Scan)来产生中间结果集。该步骤应该需要大约 9,217 次磁盘页面读取,结果集将有大约 39,241 行,平均每行 1,917 字节。请注意,这些估计与第一个示例中产生的估计相同?在这两种情况下,您都在对整个表执行顺序扫描。
在顺序扫描完成构建其中间结果集后,它被送入计划的下一步。这个特定计划的最后一步是排序操作,它是满足我们的ORDER BY子句所必需的。排序操作对顺序扫描产生的结果集进行重新排序,并将最终结果集返回给客户端应用程序。
注:ORDER BY子句在所有情况下都不需要排序操作。规划器/优化器可能决定它可以使用索引来对结果集进行排序。
Sort操作需要一个算子--一个结果集。SeqScan操作需要一个算子--一个表。有些操作需要多个算子。下面时recalls和mfgs表之间的连接:
perf=# EXPLAIN SELECT * FROM recalls, mfgs
perf-# WHERE recalls.mfgname = mfgs.mfgname;
NOTICE: QUERY PLAN:Merge Join-> Sort-> Seq Scan on recalls-> Sort-> Seq Scan on mfgs发挥下想象力,你会发现这个查询计划实际上是一个树形结构:
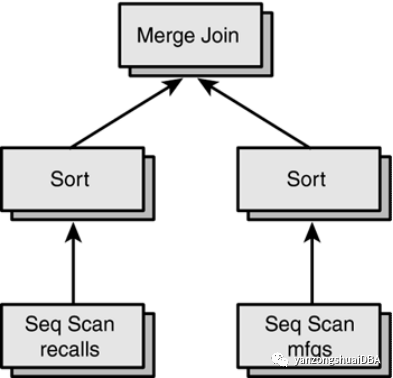
当PG执行这些查询计划时,从树的顶部开始。Merge Join操作需要输入2个结果集,因此PG必须在树种下移一级;假设首先遍历左孩子。每个Sort操作都需要一个输入结果集,因此查询执行器再次向下移动一个级别。在树底部,Seq Scan操作只是从表中读取一行并将改行返回给父节点。Seq Scan操作扫描整个表后,左侧的Sort操作可以完成。左侧的Sort完成后,Merge Join算子将评估其右孩子。这种情况下,右孩子的评估方式和左孩子相同。当2个Sort操作都完成时,将执行Merge Join运算,生成最终的结果集。到目前位置,在执行计划种已经看到了3个查询执行的算子。PG目前有19个查询算子。让我们更详细地看看每个。
Seq Scan
Seq Scan算子时最基本的查询算子。任何单表查询都可以使用Seq Scan算子执行。其工作原理是从表的开头开始扫描,直到表末尾。对于表中每一行,Seq Scan会执行查询约束(WHERE子句),如果满足约束,则将需要的列添加到结果集中。
注:查询约束:可能不会为输入集中的每一行评估整个WHERE子句。PostgreSQL 仅评估适用于给定行(如果有)的子句部分。对于单表SELECT ,将评估整个WHERE子句。对于多表连接,仅评估适用于给定行的部分。
正如本章前面看到的,一个表可能包含死记录和由于尚未提交而不可见的元组。Seq Scan不包括结果集中的死记录,但它必须读取死记录。这在大量更新的表中可能会很耗时。Seq Scan算子的成本估算为您提供了有关该算子如何工作的提示:
Seq Scan on recalls (cost=0.00..9217.41 rows=39241 width=1917)启动成本始终为0.00。这意味着可以立即返回Seq Scan算子的第一行,并且Seq Scan在返回第一行之前不会读取整个表。如果您针对使用Seq Scan运算符(并且没有其他运算符)的查询打开游标,第一个FETCH将立即返回?您不必等待整个结果集实现后即可FETCH第一行. 其他运算符(例如Sort)在返回第一行之前会读取整个输入集。
如果没有可用于满足查询的索引,则规划器/优化器会选择Seq Scan 。当规划器/优化器决定扫描整个表然后对结果集进行排序以满足排序约束(例如ORDER BY子句)时,也会使用Seq Scan 。
索引扫描
Index Scan算子通过遍历索引结构来工作。如果您为索引列指定起始值(例如WHERE record_id >= 1000),索引扫描将从适当的值开始。如果您指定一个结束值(例如WHERE record_id < 2000),则索引扫描将在找到大于结束值的索引条目后立即完成。
Index Scan算子比Seq Scan算子有两个优点。首先,Seq Scan必须读取表中的每一行——它只能通过评估每一行的WHERE子句从结果集中删除行。如果您提供开始和/或结束值,索引扫描可能不会读取每一行。其次,Seq Scan按表顺序返回行,而不是按排序顺序。索引扫描将按索引顺序返回行。
并非所有索引都是可扫描的。可以扫描B-Tree、R-Tree和GiST索引类型;哈希索引不能。
当规划器/优化器可以通过遍历一系列索引值来减小结果集的大小时,或者由于索引提供的隐式排序而可以避免排序时,它会使用索引扫描算子。
Sort
Sort算子对结果集进行排序。PostgreSQL 使用两种不同的排序策略:内存排序和磁盘排序。您可以通过调整sort_mem运行时参数的值来调整 PostgreSQL 实例。如果结果集的大小超过sort_mem,Sort会将输入集分发到已排序工作文件的集合中,然后再次将工作文件重新合并在一起。如果结果集适合sort_mem*1024字节,则使用 QSort 算法在内存中进行排序。
Sort算子永远不会减少结果集大下,它不会删除行或列。
与Seq Scan和Index Scan不同,Sort运算符必须先处理整个输入集,然后才能返回第一行。Sort算子有多种用途。显然,可以使用Sort来满足ORDER BY子句。一些查询运算符要求对其输入集进行排序。例如,Unique算子(我们稍后会看到)通过在读取已排序的输入集时检测重复值来消除行。排序也将用于一些连接操作、组操作和一些集合操作(例如INTERSECT和UNION)。
Unique
Unique算子从输入集中消除重复值。输入集必须按列排序,并且列必须唯一。例如下面命令:
SELECT DISTINCT mfgname FROM recalls;可能产生的执行计划:
Unique-> Sort-> Seq Scan on recalls此计划中的Sort算子按mfgname列对其输入集排序。Unique通过将每一行的唯一列与前一行进行比较来工作。如果值相同,则从结果集中删除重复项。Unique算子仅删除行,不会删除列,也不会更改结果集的顺序。Unique可以在处理完输入集之前返回结果集中的第一行。计划器/优化器使用Unique算子来满足DISTINCT子句。Unique还用于消除UNION中的重复项。
原文
https://etutorials.org/SQL/Postgresql/Part+I+General+PostgreSQL+Use/Chapter+4.+Performance/Understanding+How+PostgreSQL+Executes+a+Query/