NewBeeNLP·干货
作者:DOTA
大家好,这里是 NewBeeNLP。
最近因为工作上的一些调整,好久更新文章和个人的一些经验总结了,下午恰好有时间,看了看各渠道的一些问题和讨论,看到一个熟悉的问题,在这里来分享一下。
在排序算法里有三种优化目标:pairwise,pointwise,listwise,每个方法都有其优缺点。
pairwise是每次取一对样本,预估这一对样本的先后顺序,不断重复预估一对对样本,从而得到某条query下完整的排序。pair-wise损失在训练模型时,直接用两个物品的顺序关系来训练模型,就是说优化目标是物品A排序要高于物品B,类似这种优化目标。
对于pointwise而言,每次仅仅考虑一个样本,预估的是每一条和query的相关性,基于此进行排序。最简单的损失函数定义是Point-wise,就是输入用户特征和单个物品特征,对这个物品进行打分,物品之间的排序,就是谁应该在谁前面,不用考虑。
Listwise同时考虑多个样本,找到最优顺序。List-wise的Loss更关注整个列表中物品顺序关系,会从列表整体中物品顺序的角度考虑,来优化模型。
pairwise 用于推荐系统的排序任务时,效果却差于 pointwise?

(1)point wise虽然简单,但是存在不少问题。比如搜索场景,我们确实可以预估每个query到每个document的点击率做为排序依据,但是点击率要考虑rank,例如排的越靠前的document点击率上占据优势,这些point-wise模型很难考虑进去。
(2)pair wise是在搜索排序中提出的,是基于相关性标注的,正负例之间是有明显界限的,基于它产生的排序结果能输出明确的相关性。这种正负例之间的明显界限,是因为我们搜索时是有意识的、有Query的,搜索结果的排序是推荐是被动的。
(3)推荐是发散的、无意识的,是基于场景的主动推荐,在推荐场景中用户的反馈具有随机性,同样相关性高的两个Item A/B曝光给用户,用户点击了Item A,说明用户对A有兴趣,当时这能说明用户对B没有兴趣吗?与此同时精准性并不是推荐的唯一指标,多样性是一个必要的指标。在多样性前提下,曝光给用户的item集合是通过推荐系统层层的召回、排序、重排等过程,选出的最符合用户兴趣的item,此时用户的负反馈就有一定的随机性,这也就导致推荐场景不像搜索场景,可以有适合做pairwise的样本。
接下来,聊一聊3种方法各自的优缺点。
(一)pairwise

Pair-wise的方法是将同一个查询中两个不同的Item作为一个样本,主要思想是把rank问题转换为二值分类问题。对于同一Query的相关文档集中,对任何两个不同label的文档,都可以得到一个训练实例(di,dj),如果di>dj则赋值+1,反之-1,于是我们就得到了二元分类器训练所需的训练样本了。

常用Pair-wise实现有SVMRank、RankBoost、RankNet等。
优点
输出空间中样本是 pairwise preference;
假设空间中样本是二变量函数;
输入空间中样本是同一 query 对应的两个 doc和对应 query构成的两个特征向量;
损失函数评估 doc pair 的预测 preference 和真实 preference 之间差异;
缺点
只考虑了两篇文档的相对顺序,没有考虑他们出现在搜索结果列表中的位置;即:Pair-wise方法仅考虑了doc-pair的相对位置,损失函数还是没有模型到预测排序中的位置信息;
对于不同的查询相关文档集的数量差异很大,转换为文档对后,有的查询可能只有十几个文档对,而有的查询可能会有数百个对应的文档对,这对学习系统的效果评价带来了偏置;
Pair-wise对噪声标注更敏感,即一个错误标注会引起多个doc-pair标注错误;
(二)pointwise

Point-wise排序是将训练集中的每个Item看作一个样本获取rank函数,主要解决方法是把分类问题转换为单个item的分类或回归问题。就是输入用户特征和单个Item特征,对这个物品进行打分,物品之间的排序,就是谁应该在谁前面,不用考虑。Point-wise方法很好理解,即使用传统的机器学习方法对给定查询下的文档的相关度进行学习,比如CTR就可以采用PointWise的方法学习,但是有时候排序的先后顺序是很重要的,而Point-wise方法学习到全局的相关性,并不对先后顺序的优劣做惩罚。
明显这种方式无论是训练还是在线推理,都非常简单直接效率高,但是它的缺点是没有考虑物品直接的关联,而这在排序中其实是有用的。
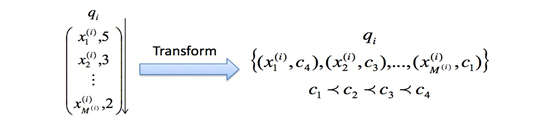
常用Point-wise实现基于回归的算法、基于分类的算法、基于有序回归的算法等。
优点
使用传统的机器学习方法对给定查询下的文档的相关度进行学习;
输入空间中样本是单个document和对应query构成的特征向量;
输出空间中样本是单个documen和对应query的相关度;
假设空间中样本是打分函数,损失函数评估单个 doc 的预测得分和真实得分之间差异。
缺点
Point-wise类方法并没有考虑同一个query对应的documents间的内部依赖性,完全从单文档的分类角度计算,没有考虑文档之间的相对顺序;
和Pair-wise类似,损失函数也没有模型到预测排序中的Position位置信息;
(三)listwise

List-wise排序是将整个item序列看作一个样本,通过直接优化信息检索的评价方法和定义损失函数两种方法来实现。它是直接基于评价指标的算法非直接基于评价指标的算法。在推荐中,List-wise损失函数因为训练数据的制作难,训练速度慢,在线推理速度慢等多种原因,尽管用的还比较少,但是因为更注重排序结果整体的最优性,所以也是目前很多推荐系统正在做的事情。
和其他X-wise方法比较,List-wise方法往往更加直接,它专注于自己的目标和任务,直接对文档排序结果进行优化,因此往往效果也是最好的。Listwise常用方法有AdaRank、SoftRank、LambdaMART、LambdaRank等。
优点
输入空间中样本是同一query对应的所有documents构成的多个特征向量;
输出空间中样本是这些documents和对应query的相关度排序列表或者排列;
假设空间中样本是多变量函数,对于documents得到其排列,实践中,通常是一个打分函数,根据打分函数对所有documents的打分进行排序得到documents相关度的排列;
listwise 类相较 pointwise、pairwise 对 ranking 的 model 更自然,解决了 ranking 应该基于 query 和 position 问题。
缺点
一些ranking算法需要基于排列来计算 loss,从而使得训练复杂度较高,如 ListNet和 BoltzRank。
位置信息并没有在loss中得到充分利用,可以考虑在ListNet和ListMLE loss中引入位置折扣因子。
(四)应用实践

这里,介绍一下用 XGBoost 如何实践上面的几种方法,本章节已有实践经验的可自行忽略。
首先要明确的是训练数据,训练数据必须包含一列query id,该id下指明哪些样本要放到一起进行排序.同时特别需要注意的是,在训练集和测试集进行拆分时,需要按query id进行分割,如果直接随机拆分,同一个query id下的数据就会被分开,这样会导致模型出问题。我们可以用如下代码进行拆分:
from sklearn.model_selection import GroupShuffleSplit
gss = GroupShuffleSplit(test_size=.40, n_splits=1, random_state = 7).split(df, groups=df['query_id'])
X_train_inds, X_test_inds = next(gss)train_data= df.iloc[X_train_inds]
X_train = train_data.loc[:, ~train_data.columns.isin(['id','rank'])]
y_train = train_data.loc[:, train_data.columns.isin(['rank'])]# 模型需要输入按query_id排序后的样本
# 并且需要给定每个query_id下样本的数量
groups = train_data.groupby('id').size().to_frame('size')['size'].to_numpy()test_data= df.iloc[X_test_inds]#We need to keep the id for later predictions
X_test = test_data.loc[:, ~test_data.columns.isin(['rank'])]
y_test = test_data.loc[:, test_data.columns.isin(['rank'])]我们的数据格式应该如下所示,如果数据长这样,那么我们上述代码中的groups就是[3, 4]:

然后我们就可以建模了,可以用XGBRanker训练排序模型,在这个场景下,我们无法自定义objective,,也无法自定义mertic了。
import xgboost as xgbmodel = xgb.XGBRanker( tree_method='gpu_hist',booster='gbtree',objective='rank:pairwise',random_state=42, learning_rate=0.1,colsample_bytree=0.9, eta=0.05, max_depth=6, n_estimators=110, subsample=0.75 )model.fit(X_train, y_train, group=groups, verbose=True)训练完后我们就可以进行预估,因为预估方法并不会输入groups,所以我们需要做一些特殊处理:
def predict(model, df):return model.predict(df.loc[:, ~df.columns.isin(['id'])])predictions = (data.groupby('id').apply(lambda x: predict(model, x)))这里选择了"rank:pairwise"作为loss,看官方文档还有其他rank loss可供尝试:

pairwise 方法相比pointwise有优势,可以学习到一些顺序。但是pairwise也有缺点:
1.只能给出排序,并不能给出有多好,好多少。比如在搜索场景下,可能一条与query相关的doc都没,pointwise可以通过卡阈值得到这个信息,但是rank方式就不能区分。
2.当一个query下有很多doc,会产生大量的pairs。
3.对噪声的label 非常敏感。
参考资料

https://zhuanlan.zhihu.com/p/613354685
一起交流
想和你一起学习进步!『NewBeeNLP』目前已经建立了多个不同方向交流群(机器学习 / 深度学习 / 自然语言处理 / 搜索推荐 / 图网络 / 面试交流 / 等),名额有限,赶紧添加下方微信加入一起讨论交流吧!(注意一定o要备注信息才能通过)