目录
- pdf复制出乱码解决方案
- 一、pdf格式基础
- 二、ttf格式基础
- 三、解决乱码
- 1.提取文字,识别文字
- a.和原文件比对
- b.OCR+手工辅助识别
- 2.修改pdf中的文字,使其可复制
- a.选择pdf开发库
- b.修改pdf
- c.完整代码
pdf复制出乱码解决方案
偶然发现有一类pdf文档中的文字虽然能被选中,在拷贝时却出现了乱码。遂拿来研究一下
一、pdf格式基础
网上的pdf格式介绍文章包括adobe官方文档已经介绍的相当全面了,这里不加赘述
pdf格式介绍文章
一个极小的pdf文件demo
pdf1.7官方文档
总结下来本问题需要了解一下几点(最近两天粗略看的,不知道理解的对不对):
- pdf中的内容是以对象构成,类似于以下的方式进行组织
class Object {int id;int ref;virtual std::string name()=0;
}
class Page : public Object{virtual std::string name() {return "Page";}Object* content;Object* image;Object* font;
}
class Content: public Object{virtual std::string name() {return "Content";}Object* contentstream;....
}
class Image: public Object{virtual std::string name() {return "Image";}Object *imagestream;...
}
class Font: public Object{virtual std::string name() {return "Font";}Object *fontstream;...
}
class Stream:....
- pdf中的文字对象大多是流的形式构成,流中的内容是由某种压缩算法指定,需要解压后才能看到原始的值,流中的文本对象以BT开始,以ET结束,其中内容有两种表示方式,一种是十六进制的方式,用尖括号表示,例如<31323334>,表示文本0x31,0x32,0x33,0x34,即1234,也可以直接使用明文表示,比如(1234),也表示文本1234.
- 文本中使用的字体在BT和ET之间,末尾以Tf结束,比如/G1 1 Tf,表示使用G1字体,大小为1,G1字体到底是什么参见下面的5
- ToUnicode,自行阅读pdf1.7文档5.9.2 ToUnicode CMaps
- pdf中某一页的字体有一个特殊的映射表,一个可能的Page对象如下所示
94 0 obj
<< /Type /Page /Parent 3 0 R /Resources 97 0 R /Contents 95 0 R /MediaBox
[0 0 595.2756 841.8898] >>
endobj
97 0 obj
<< /ProcSet [ /PDF /Text /ImageB /ImageC /ImageI ] /ColorSpace << /Cs1 7 0 R
>> /ExtGState << /Gs4 59 0 R /Gs3 60 0 R /Gs1 26 0 R >> /Font << /TT4 20 0 R
/G1 8 0 R /TT1 11 0 R >> /XObject << /Im14 98 0 R >> >>
94号对象是Page,可以看出,他的Resouce是97号对象,其中字体存在如下映射
/Font << /TT4 20 0 R /G1 8 0 R /TT1 11 0 R >>
TT4表示第20个字体对象,G1表示第8个字体对象,TT1表示第11个字体对象,所以上述的G1字体应该存在obj 8里
8 0 obj
<< /Type /Font /Subtype /Type0 /Encoding /Identity-H /DescendantFonts [260 0 R]
/BaseFont /QWWOYD+STSongti-SC-Bold /ToUnicode 261 0 R >>
endobj
该字体的名字是QWWOYD+STSongti-SC-Bold,存在第260个对象中,此时可以根据对象的引用继续查找,找到该字体对应的二进制编码,解压后就是相应的ttf/ocf/cff字体文件
也可以使用pdffont工具直接提取pdf中的字体文件(链接)
二、ttf格式基础
ttf是一种字体文件,存储着某个unicode/ascii编码到对应字体的映射,可以利用fontcreator等软件读取整个文件,值得注意的是,这个映射不一定包含了所有的字体,可以包含某几个特定的字体(例如在pdf中提取的ttf文件可能只有几KB,显然没有包含所有字体),而且其中的unicode等编码的映射关系也是自定义的。也就是说,在生成pdf时,假如使用可嵌入字体,可能unicode到对应字体之间的关系是错的。本来“的”这个字的unicode编码是U+7684,但是可能在ttf文件中被定义成了U+0001
三、解决乱码
1.提取文字,识别文字
由于ttf中unicode编码的映射顺序是乱的,无法直接根据序号做一一映射,有两种方法进行提取文字识别:
a.和原文件比对
由于字体文件中有字体名,可以从网上找一份完整的ttf文件,和该文件进行比对,找出每个文字在原ttf文件上的位置
可以通过fontTools库中TTFont.saveXML方法把ttf文件中的关键信息提取成xml文件,发现每个字符都在ttf文件上维护了一个如下的点集,类似于svg文件的格式,这个点集中的pt标签猜测代表了绘制文字时需要走的“路径”。
<TTGlyph name="glyph1" xMin="110" yMin="-165" xMax="937" yMax="783"><contour><pt x="641" y="529" on="1"/><pt x="596" y="438" on="0"/><pt x="489" y="298" on="1"/>...</contour>\<instructions/></TTGlyph>
对比了一下完整的ttf文件和从pdf中dump出的ttf文件,发现不是很一致,不过大部分的x,y坐标时相同的。有可能在生成pdf时,对字模进行了重编码的优化?不过可以通过启发式的算法(更为通俗的叫法是——乱搞)来生成pdf中字体自定义的unicode编码到真实unicode编码之间的映射。
记pdf中字体某个unicode编码i对应的点集为 T A R G E T i = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x n , y n ) } TARGET_i=\{(x_1,y_1),(x_2,y_2),...,(x_n,y_n)\} TARGETi={(x1,y1),(x2,y2),...,(xn,yn)} ,真实的unicode编码j对应的点集为 B A S E j = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x m , y m ) } BASE_j=\{(x_1,y_1),(x_2,y_2),...,(x_m,y_m)\} BASEj={(x1,y1),(x2,y2),...,(xm,ym)} ,,定义 ( s c o r e 2 ) i j (score_2)_{ij} (score2)ij 为二者元素个数的差 ∣ c a r d ( T A R G E T i ) − c a r d ( B A S E j ) ∣ |card(TARGET_i)-card(BASE_j)| ∣card(TARGETi)−card(BASEj)∣ ,定义 ( s c o r e 1 ) i j (score_1)_{ij} (score1)ij 为二者的交集元素的个数 c a r d ( T A R G E T i ∩ B A S E j ) card(TARGET_i \cap BASE_j) card(TARGETi∩BASEj) ,定义两个字模之间的整体差异 s c o r e i j = − ( s c o r e 1 ) i j + ( s c o r e 2 ) i j score_{ij} = -(score_1)_{ij}+(score_2)_{ij} scoreij=−(score1)ij+(score2)ij ,我们需要做的就是对一个pdf中的字模i,找到真实编码中的字模j,使得 s c o r e i j score_{ij} scoreij 最大,从而字模i真实的unicode编码可以认为就是j。
经过测试,上述的算法可以识别测试用的pdf中所有的文字(340个)对应的unicode编码。出于时间问题,只写了暴力手段进行字模搜索的代码
from fontTools.ttLib import TTFont
from fontTools.pens.basePen import BasePen
from reportlab.graphics.shapes import Path
from reportlab.lib import colors
import jsonclass ReportLabPen(BasePen):"""A pen for drawing onto a reportlab.graphics.shapes.Path object."""def __init__(self, glyphSet, path=None):BasePen.__init__(self, glyphSet)if path is None:path = Path()self.path = pathdef _moveTo(self, p):(x,y) = pself.path.moveTo(x,y)def _lineTo(self, p):(x,y) = pself.path.lineTo(x,y)def _curveToOne(self, p1, p2, p3):(x1,y1) = p1(x2,y2) = p2(x3,y3) = p3self.path.curveTo(x1, y1, x2, y2, x3, y3)def _closePath(self):self.path.closePath()baseFontName = "STSongti-SC-Bold"
fontName = "QWWOYD+STSongti-SC-Bold"def getTTFMap(font_):fontName="%s.ttf"%font_font = TTFont(fontName)gs = font.getGlyphSet()ascii_map={}reverse_map=font.getReverseGlyphMap()for key in reverse_map:ascii_map[reverse_map[key]]=keyupdated_map={}for table in font["cmap"].tables:if len(table.cmap)<len(ascii_map):updated_map=table.cmap for key in updated_map:ascii_map[key]=updated_map[key]ttfinfo={}for index in ascii_map:i=ascii_map[index]if i[0] == '.':#跳过'.notdef', '.null'continueg = gs[i]pen = ReportLabPen(gs, Path(fillColor=colors.black, strokeWidth=1))g.draw(pen)ttfinfo[index]=pen.path.pointscontinuereturn ttfinfobaseTTFInfo=getTTFMap(baseFontName)
TTFInfo=getTTFMap(fontName)
ttfMap={}
def getMap(lst):mp={}for item in lst:if item in mp.keys():mp[item]+=1else:mp[item]=1 return mp
for key in TTFInfo:maxn=-1e9dst=-1for each in baseTTFInfo:target = TTFInfo[key]base = baseTTFInfo[each]score1=-abs(len(target)-len(base))targetMp=getMap(target)baseMp=getMap(base)score2=0for pos in targetMp:if pos in baseMp:score2+=min(targetMp[pos],baseMp[pos])score=score1+score2if (score>=maxn):maxn=scoredst=eachttfMap[key]=chr(dst)print("key %d is %s"%(key,chr(dst)))lst=json.dumps(ttfMap)
open("%s.json"%fontName,"w").write(lst)b.OCR+手工辅助识别
刚开始,笔者尚未从网上找到STSongti-SC-Bold这个字体对应的ttf文件,对于这种情况,只能退而求其次,用网上现有的模型跑神经网络或者用封装好的库进行OCR,其中识别出现问题的保存在文件中手工辅助识别,python代码如下:
from fontTools.ttLib import TTFont
from fontTools.pens.basePen import BasePen
from reportlab.graphics.shapes import Path
from reportlab.lib import colors
from reportlab.graphics import renderPM
from reportlab.graphics.shapes import Group, Drawing
import jsonclass ReportLabPen(BasePen):"""A pen for drawing onto a reportlab.graphics.shapes.Path object."""def __init__(self, glyphSet, path=None):BasePen.__init__(self, glyphSet)if path is None:path = Path()self.path = pathdef _moveTo(self, p):(x,y) = pself.path.moveTo(x,y)def _lineTo(self, p):(x,y) = pself.path.lineTo(x,y)def _curveToOne(self, p1, p2, p3):(x1,y1) = p1(x2,y2) = p2(x3,y3) = p3self.path.curveTo(x1, y1, x2, y2, x3, y3)def _closePath(self):self.path.closePath()import easyocr
fontName = "QWWOYD+STSongti-SC-Bold"available_chars={}
for i in range(32,128):available_chars[chr(i)]=i
available_chars["space"]=ord(" ")def ttfToImage(font_,imagePath,fmt="png"):fontName="%s.ttf"%font_font = TTFont(fontName)gs = font.getGlyphSet()ascii_map={}reverse_map=font.getReverseGlyphMap()for key in reverse_map:ascii_map[reverse_map[key]]=keyupdated_map={}for table in font["cmap"].tables:if len(table.cmap)<len(ascii_map):updated_map=table.cmap for key in updated_map:ascii_map[key]=updated_map[key]reader = easyocr.Reader(['ch_sim','en']) # need to run only once to load model into memoryttfinfo={}for index in ascii_map:i=ascii_map[index]if i[0] == '.':#跳过'.notdef', '.null'continueprint((index,i))g = gs[i]pen = ReportLabPen(gs, Path(fillColor=colors.black, strokeWidth=1))g.draw(pen)w, h = g.width, g.widthg = Group(pen.path)g.translate(0, 200)d = Drawing(w/4, h/4)d.add(g)d.scale(0.1,0.1)imageFile = "tmp.png"renderPM.drawToFile(d, imageFile, fmt)result = reader.readtext(imageFile,detail=0)if (len(result)==1 and len(result[0])==1):ttfinfo[index]=result[0][0]else:ttfinfo[index]=Noneprint("%s recognize failed"%i)renderPM.drawToFile(d, "images/%s.png"%i, fmt)lst=json.dumps(ttfinfo)open("%s.json"%font_,"w").write(lst)return ttfinfottfinfo=ttfToImage(font_=fontName,imagePath="images")for key in ttfinfo.keys():if (ttfinfo[key]==None):s=input("charater in index %s:"%key)print("charater in index %s is %s"%(key,json.dumps(s)))ttfinfo[key]=slst=json.dumps(ttfinfo)
open("%s.json"%fontName,"w").write(lst)
上述两种方式的代码最终都输出一个json文件,key是ttf文件中自定义的unicode编码,value是真实的字体所对应的unicode编码
2.修改pdf中的文字,使其可复制
a.选择pdf开发库
知乎上有一篇文章(链接)总结了一下操作pdf常用的python库,总结就是从文章中盗的该图片:
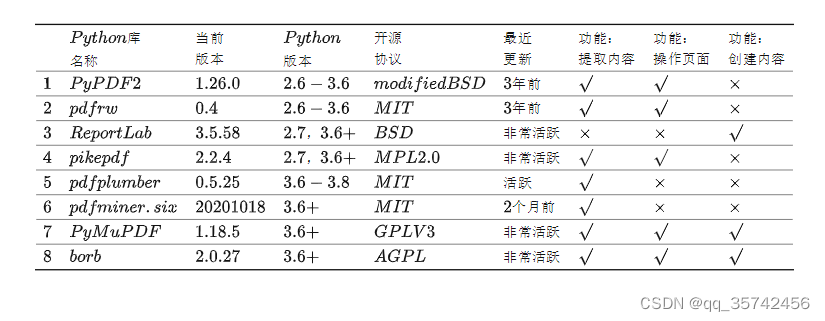
看了一下pymupdf和borb的repo,感觉borb的文档比较齐全,选择直接用borb进行开发。
但是borb的文档中貌似没有给直接从流层面修改文字的api,参考了一下源码的写法,只需要新建一个stream替换原有的即可。(新建stream的demo见源码中为pdf添加JavaScript代码片段 链接)
b.修改pdf
一个简单的思路是,直接用真实的编码替换原pdf中的字符编码,但是会出现一个问题是虽然可以复制了,但是输出的pdf文档会是乱码。
修复方案
- 用pdf编辑软件替换pdf中的字体,只要替换成非pdf中的内嵌字体,按理说就可以正常显示
- 直接修改pdf文件,向其中硬编码进对应字体的完整ttf文件
方案一读者可以自行实现,下面主要介绍方案二的实现
使用常见字体(本文中以楷体为例)替换pdf中的内嵌字体
from borb.pdf.canvas.font.simple_font.true_type_font import TrueTypeFont
commom_unicode_font=TrueTypeFont.true_type_font_from_file(Path("C:/windows/fonts/simkai.ttf"))
for page_number in range(pages):page = pdf.get_page(page_number)font_resource = page["Resources"]["Font"]for font_name in font_resource:if (full_name == replace_font_name):font_resource[font_name]=commom_unicode_fontfull_name=font_resource[font_name]["BaseFont"]
然后利用把pdf中的unicode编码改成真实的unicode编码
for mpos in range(rec,pos,4):index = int(''.join(list_text[mpos:mpos+4]),16)newcode = ord(ttfinfo[str(index)])code = "%04x"%newcodelist_text[mpos],list_text[mpos+1],list_text[mpos+2],list_text[mpos+3]=code[0],code[1],code[2],code[3]
此时转换的pdf文件依然是乱码,原因是系统中的楷体对应的ttf文件也维护了一套自己的ToUnicode表,需要将真实的unicode再转换成simkai.ttf中自定义的unicode编码:
for mpos in range(rec,pos,4):index = int(''.join(list_text[mpos:mpos+4]),16)newcode = commom_unicode_font.unicode_to_character_identifier((ttfinfo[str(index)]))code = "%04x"%newcodelist_text[mpos],list_text[mpos+1],list_text[mpos+2],list_text[mpos+3]=code[0],code[1],code[2],code[3]
c.完整代码
from borb.pdf import PDF
from pathlib import Path
from borb.io.read.types import Name
from borb.io.read.types import Decimal as bDecimal
from borb.pdf.canvas.font.simple_font.true_type_font import TrueTypeFontimport zlib
import jsonin_file_handle=open("1.pdf", "rb")
pdf = PDF.loads(in_file_handle)
pages = int(pdf.get_xmp_document_info().get_number_of_pages())replace_font_name="QWWOYD+STSongti-SC-Bold"ttfinfo=json.loads(open("%s.json"%replace_font_name,"r").read())commom_unicode_font=TrueTypeFont.true_type_font_from_file(Path("C:/windows/fonts/simkai.ttf"))
for page_number in range(pages):print("converting page %d"%page_number)page = pdf.get_page(page_number)stream = page["Contents"]font_resource = page["Resources"]["Font"]font_map={}for font_name in font_resource:full_name=font_resource[font_name]["BaseFont"]if (full_name == replace_font_name):font_resource[font_name]=commom_unicode_fontfull_name=font_resource[font_name]["BaseFont"] font_map[str(font_name)]=str(full_name)text=stream["DecodedBytes"].decode("latin1")list_text=list(text)pos=text.find("Tf <")while (pos!=-1):fontpos=pos-2while (text[fontpos]!=' ' and text[fontpos]!='\n' and text[fontpos]!='\r'):fontpos-=1font_front_pos=fontposwhile (text[font_front_pos]!='/'):font_front_pos-=1text_font=text[font_front_pos+1:fontpos]text_font=font_map[text_font]pos+=4# if (text[pos-1]=='('):# rec = pos# pos=text.find(")",pos)# print(text[rec-15:pos+5])# pos=text.find("Tf ",pos)# continuerec=pospos=text.find(">",pos)if (pos == -1):breakfor mpos in range(rec,pos,4):index = int(''.join(list_text[mpos:mpos+4]),16)newcode = commom_unicode_font.unicode_to_character_identifier((ttfinfo[str(index)]))code = "%04x"%newcodelist_text[mpos],list_text[mpos+1],list_text[mpos+2],list_text[mpos+3]=code[0],code[1],code[2],code[3]pos=text.find("Tf <",pos)text_new=''.join(list_text)stream[Name("DecodedBytes")] = bytes(text_new, "latin1")stream[Name("Bytes")] = zlib.compress(stream[Name("DecodedBytes")], 9)stream[Name("Length")] = bDecimal(len(stream[Name("Bytes")]))page[Name("Contents")]=stream#store the PDF
with open("output.pdf", "wb") as pdf_file_handle:PDF.dumps(pdf_file_handle, pdf)


![[RK3568 Android12] GT911触摸屏调试](https://img-blog.csdnimg.cn/b8a0ff0d0b5e43ae98f6a8176cf8ad06.png)