在这次应用软件设计课程中,要求从今年的软件杯大赛上的项目选择一个实现。我选的是"网店工商信息提取",具体要求就是:从给出的带水印的图片中提取出企业名称和企业注册号,并根据这些信息生成excel表格。
刚刚开始以为这个要求挺难实现的,图片识别好像是很高深的技术啊。但是认真做起来从开工到完成也没花多少时间,并不是我完成了图片识别的代码,而是我用到了谷歌一个图片识别的源码包(TESS4J)。其实不止是图片识别这部分,生成excel表也是用的第三方源码包(感觉好方便)。早知道这么容易,后悔没有报名软件杯。。。
这样,项目四个模块的功能(水印处理、图片识别、信息提取、生成excel表)我自己实现的其实只有信息提取和水印处理。虽然如此,还是有必要记录一下。
下面上代码:
首先是主函数RP.java:
import java.awt.Rectangle;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;import net.sourceforge.tess4j.*;
import org.apache.poi.ss.usermodel.HorizontalAlignment;
import org.apache.poi.xssf.usermodel.*;public class RP {private String a0="无法识别",c0="无法识别";public void PickUp(String s) //提取文字中的公司名和注册号{int c1=-1,c2=-1;c1=s.lastIndexOf("号 :");c2=s.indexOf("\n");if(c1!=-1&&c2!=-1){c0=s.substring(c1+4, c2);}int a1=-1,a2=-1;a1=s.indexOf("称 :");a2=s.lastIndexOf("\n");if(a1!=-1&&a2!=-1){a0=s.substring(a1+4, a2);}/* else{int b1=s.indexOf("名称:");int b2=s.lastIndexOf("有限公司");if(b1!=-1){b0=s.substring(b1+3, b2+2);}}*/}public void toExcel(int i,XSSFWorkbook wb,XSSFSheet sheet) //将文字信息做成表格{if(i==0) //第一行的话,就设置列名等属性{XSSFRow row=sheet.createRow(0);XSSFCellStyle style=(XSSFCellStyle)wb.createCellStyle();style.setAlignment(HorizontalAlignment.CENTER);XSSFCell cell=row.createCell(0);cell.setCellValue("企业名称");cell.setCellStyle(style); cell = row.createCell(1); cell.setCellValue("企业注册号"); cell.setCellStyle(style);}else //不是第一行就将识别到的信息输入表格{XSSFRow row = sheet.createRow(i); row.createCell(0).setCellValue(this.a0); row.createCell(1).setCellValue(this.c0); }}public static void main(String[] args) throws IOException {RP rp=new RP();int num=1;Rectangle ret=new Rectangle(0,0,550,80); //设置一个矩形区域,作为识别部分,减少运行时间提高识别率File root = new File(System.getProperty("user.dir") + "/imgs");//存放处理后的图片,imgs文件夹File res=new File(System.getProperty("user.dir") + "/res");//源图片位置,res文件夹下ITesseract instance = new Tesseract();instance.setLanguage("songti"); //使用训练好中文字库识别XSSFWorkbook wb=new XSSFWorkbook();XSSFSheet sheet=wb.createSheet("信息汇总");rp.toExcel(0,wb,sheet); //设置列名try {File[] ress = res.listFiles();int i=0;for(File file : ress){i++;WaterMark.Clean(file.getAbsolutePath(),"F:\\eclipse-workspace\\ReadPicture\\imgs\\"+i+".png");} //去除源图片水印,处理后的图片放到img文件夹File[] files = root.listFiles();for (File file : files) { //对去除水印后的图片逐个处理String result = instance.doOCR(file,ret); //开始采用doOCR(file)效率很低,因为图片内容太多System.out.print(result);rp.a0="无法识别";rp.c0="无法识别";rp.PickUp(result); //调用信息提取的函数,提取出企业名和企业注册号rp.toExcel(num,wb,sheet); //调用toExcel函数,将提取到的信息写入num++;}} catch (TesseractException e) {System.err.println(e.getMessage());}try { FileOutputStream fout = new FileOutputStream("F:\\company imformation\\company.xlsx"); wb.write(fout); fout.close(); } catch (IOException e) { e.printStackTrace(); } //把写好信息的表输出}}然后是水印处理的:WaterMark.java:
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
import java.awt.Color;public class WaterMark {public static void Clean( String frompath,String topath) throws IOException {File file1 = new File(frompath);BufferedImage image = ImageIO.read(file1);for(int i=0;i<550;i++) //这里只取x轴550,y轴80区域的像素点,因为需要识别的信息只在这个区域,这样可以节约程序运行时间{for(int j=0;j<80;j++){int pixel = image.getRGB(i, j); //获得坐标(i,j)的像素int red = (pixel & 0xff0000) >> 16; int green = (pixel & 0xff00) >> 8;int blue = (pixel & 0xff); //通过坐标(i,j)的像素值获得r,g,b的值if(red>=10&&red<=20&&green>=10&&green<=20&&blue>=10&&blue<=20) //组成字符的像素点置为黑色{int cover=new Color(0,0,0).getRGB();image.setRGB(i,j,cover);}else {int white=new Color(255,255,255).getRGB(); //其他全改为白色image.setRGB(i,j,white);}}}/*for(int i=1;i<550;i++) //获取一个像素点的四周像素点的rgb,如果这个点的上下都是黑或左右都是黑,则把这个点置为黑。减少失真程度{for(int j=1;j<80;j++){int t=0,d=0,r=0,l=0;int pixeltop = image.getRGB(i, j-1);int redtop = (pixeltop & 0xff0000) >> 16;int greentop = (pixeltop & 0xff00) >> 8;int bluetop = (pixeltop & 0xff);int pixelleft = image.getRGB(i-1, j);int redleft = (pixelleft & 0xff0000) >> 16;int greenleft = (pixelleft & 0xff00) >> 8;int blueleft = (pixelleft & 0xff);int pixelright = image.getRGB(i+1, j);int redright = (pixelright & 0xff0000) >> 16;int greenright= (pixelright& 0xff00) >> 8;int blueright = (pixelright & 0xff);int pixeldown = image.getRGB(i, j+1);int reddown = (pixeldown & 0xff0000) >> 16;int greendown= (pixeldown& 0xff00) >> 8;int bluedown = (pixeldown & 0xff);if(redtop==0&&greentop==0&&bluetop==0){t=1;}if(redleft==0&&greenleft==0&&blueleft==0){l=1;}if(redright==0&&greenright==0&&blueright==0){r=1;}if(reddown==0&&greendown==0&&bluedown==0){d=1;}if(r==1&&l==1) //上下同时为黑,就把这个点置为黑{int cover=new Color(0,0,0).getRGB();image.setRGB(i,j,cover);}if(d==1&&t==1) //左右同时为黑,就把这个点置为黑{int cover=new Color(0,0,0).getRGB();image.setRGB(i,j,cover);}}}*/ //其实这个处理步骤没有影响好像也不大,识别率也相当高了(训练了字库的前提下)File file2=new File(topath);ImageIO.write(image,"png",file2); //图片更改后重新写入另一个文件夹}
}这里解释下获取RGB的代码:
int pixel = image.getRGB(i, j);
int red = (pixel & 0xff0000) >> 16;
int green = (pixel & 0xff00) >> 8;
int blue = (pixel & 0xff);对一个像素点getRGB后得到32位的值,r,g,b的值各占8位,如图:

从右到左即从0到31。加入要获取g,就将像素值和0xff00按位相与,得到一个16位的值,其中低8位全为0,这样再将这个16位的值右移8位就得到了g的值。
关于训练字库,这是我的同组同学完成的,可以参考这篇博客:
https://blog.csdn.net/why200981317/article/details/48265621
在导入所有的需要用到的jar包,并biuld path后,运行程序。源图片是这样的:

经过处理后是这样的:

有一些失真,但是经过训练字库影响不大。
提取信息生成的excel表格:
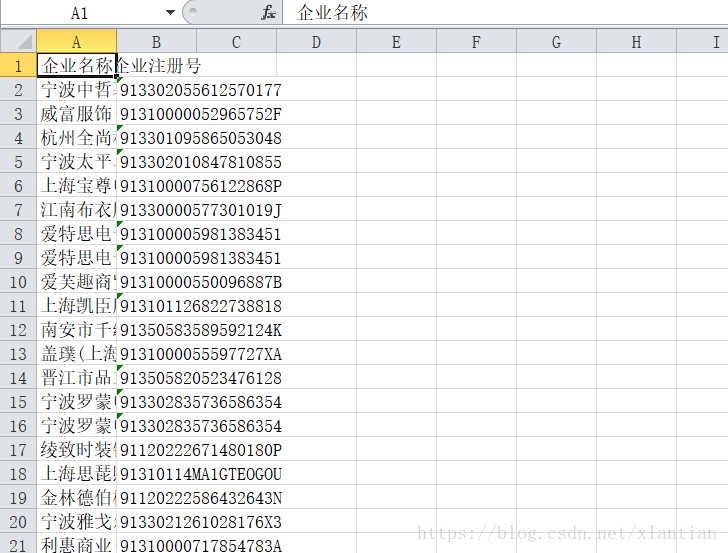
简述一下程序的流程:
1.对图片进行去水印处理,这里只处理图片的一部分以节约程序运行时间。
2.用训练好的字库识别图片信息,这里指定只识别部分区域以节约程序运行时间,识别图片信息源码包是TESS4J包.
3.提取图片信息,提取出企业名称和企业注册号信息。
4.用提取到的信息生成excel表格,用到的源码包是poi包。
不知道导入哪些jar包的可以去直接下载:https://download.csdn.net/download/xlantian/10495923。文件有点大是因为字库文件占用空间较大。
最后致谢:训练字库的同学。

![[软件工具] 如何批量获取图片信息,尺寸、大小、路径、文件名,然后导出表格或者txt的文本,下面教你使用方法](https://img.weiyun.com/vipstyle/nr/box/img/favicon.ico?max_age=31536000)






![[Matlab]篇----回归分析Matlab命令(regress篇)](https://img-blog.csdn.net/20180120184359370?watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvcXFfMTcxMTkyNjc=/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70/gravity/SouthEast)


![[matlab]多元线性回归-regress函数的用法](https://img-blog.csdn.net/20180807015234502?watermark/2/text/aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L1lpbkppYW54aWFuZw==/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70)


![[MATLAB]一元线性回归(regress参数检验说明)](https://img-blog.csdnimg.cn/20200331164710650.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L20wXzM3MTQ5MDYy,size_16,color_FFFFFF,t_70)


