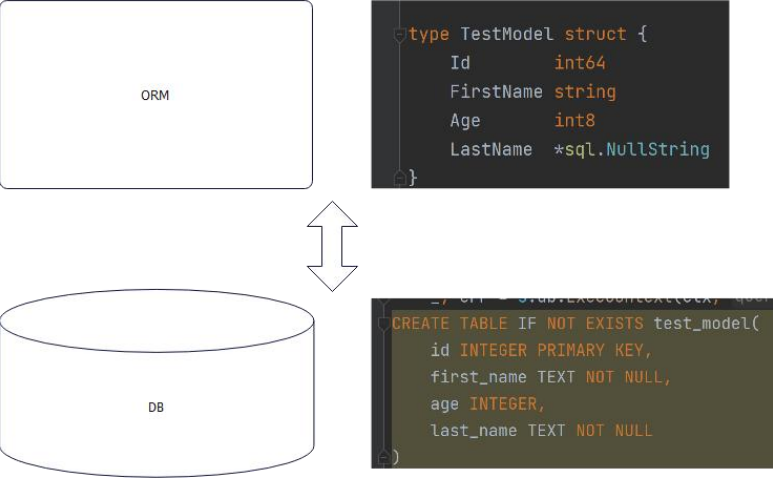
什么是元数据
orm 框架一般需要定义表的模型,然后模型与表生成映射关系,那么就一定少不了解析模型然后找到与之映射的数据库表,所以,元数据是解析模型获得的,这些元数据将被用于构建 SQL、执行校验,以及用 于处理结果集。
模型:一般是指对应到数据库表的 Go 结构体定 义,也被称为 Schema、Table、Meta 等
开源实例
Beego orm
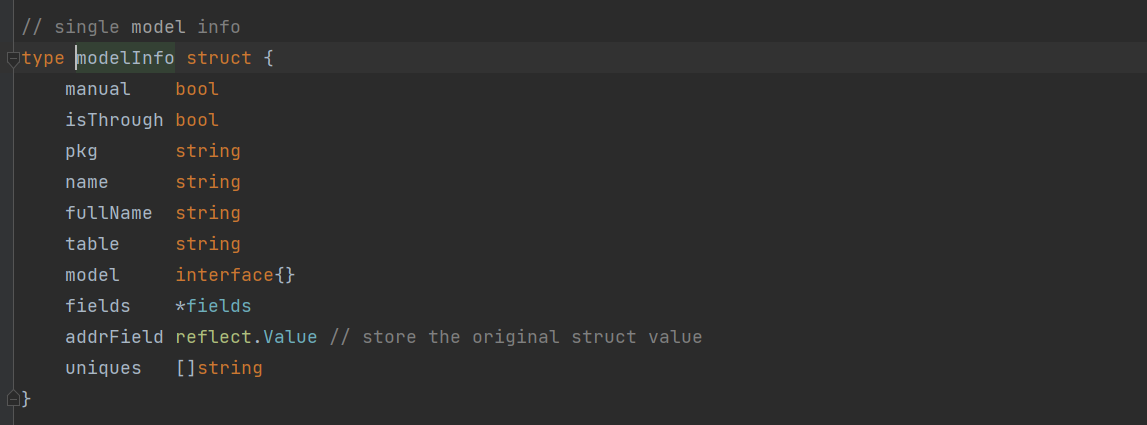
Gorm
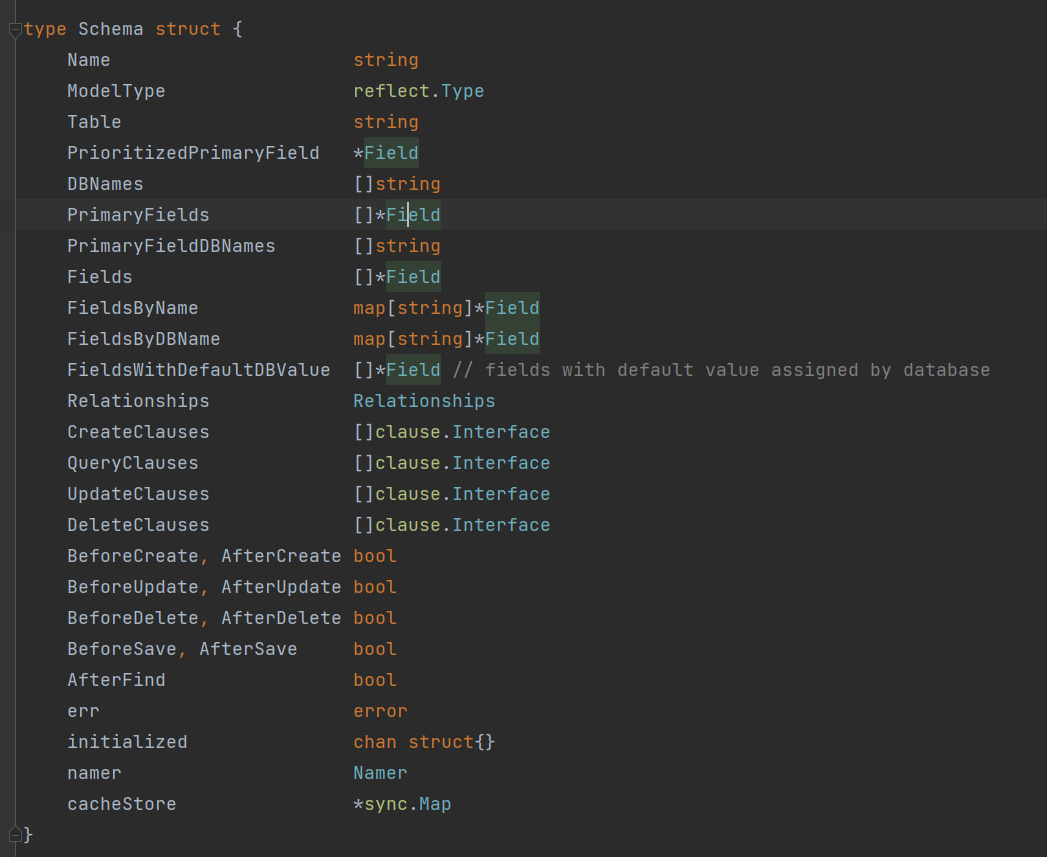
设计总结
不管是哪个框架,要考虑保存对应的表的元数据信息,那就避免不了,Model 和 Field 这两个类,Model 保存表维度的信息;Field 保存字段维度的信息;
Model: 表名、索引、主键、关联关系
Field:列名、Go 类型、数据库类型、是否主键、是否外键……
由此可以推断,开源实例的元数据设计看上去很复杂但其设计的演化过程如下:
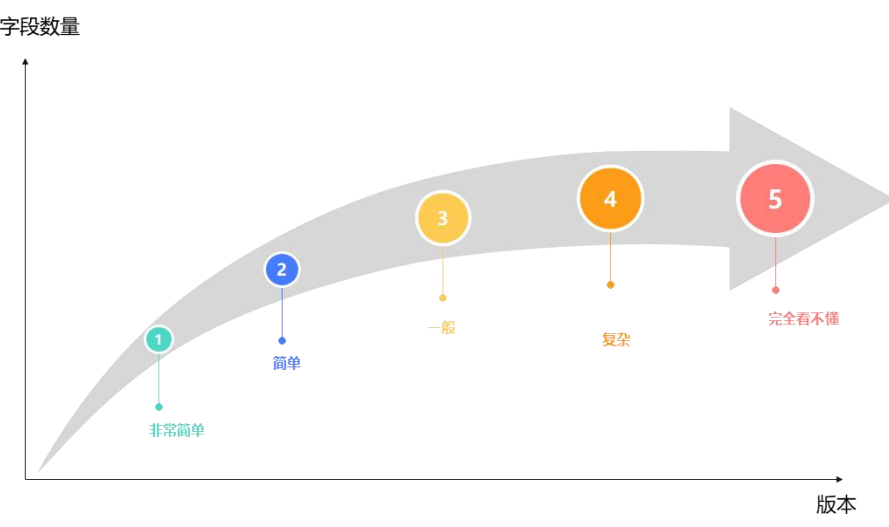
解析模型
元数据最简单的版本如下:
// field 字段
type Field struct {colName string
}
type Model struct {// tableName 结构体对应的表名tableName string// 字段名到字段的元数据fieldMap map[string]*Field
}
其实从已有的功能 From 和 Where 来看,那么最少也就需要两个东西:列名、表名;现在如何吧这两个信息解析出来呢?答案就是利用 go 的反射机制; 这里可以优先参考常见的开源实例如下,看看这里是怎么做的。
Beego orm
beego orm 采用了用 reflect.Value 接收待解析的模型类参数。
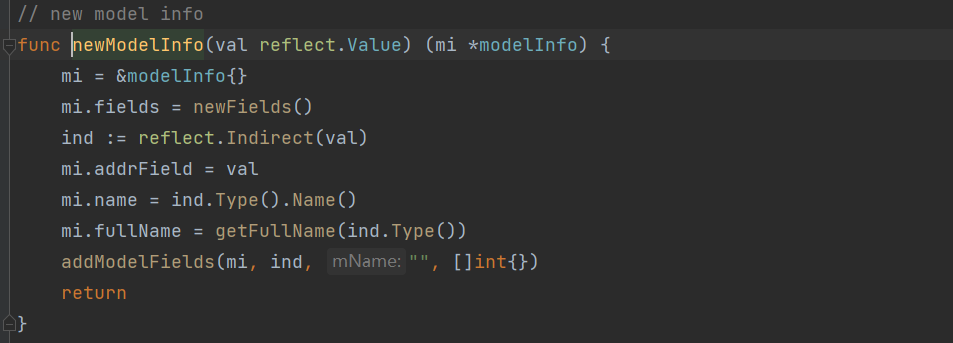
一般来说考虑组合定义的模型时,就难免需要使用递归
Gorm
Gorm 总体上也是设计思想也是相近的,不过它将元数据模型称为 Schema,解析模型得到元数据的代码在 Parse 方法中,方法的逻辑中展示了 Gorm 支持什 么样的模型定义。
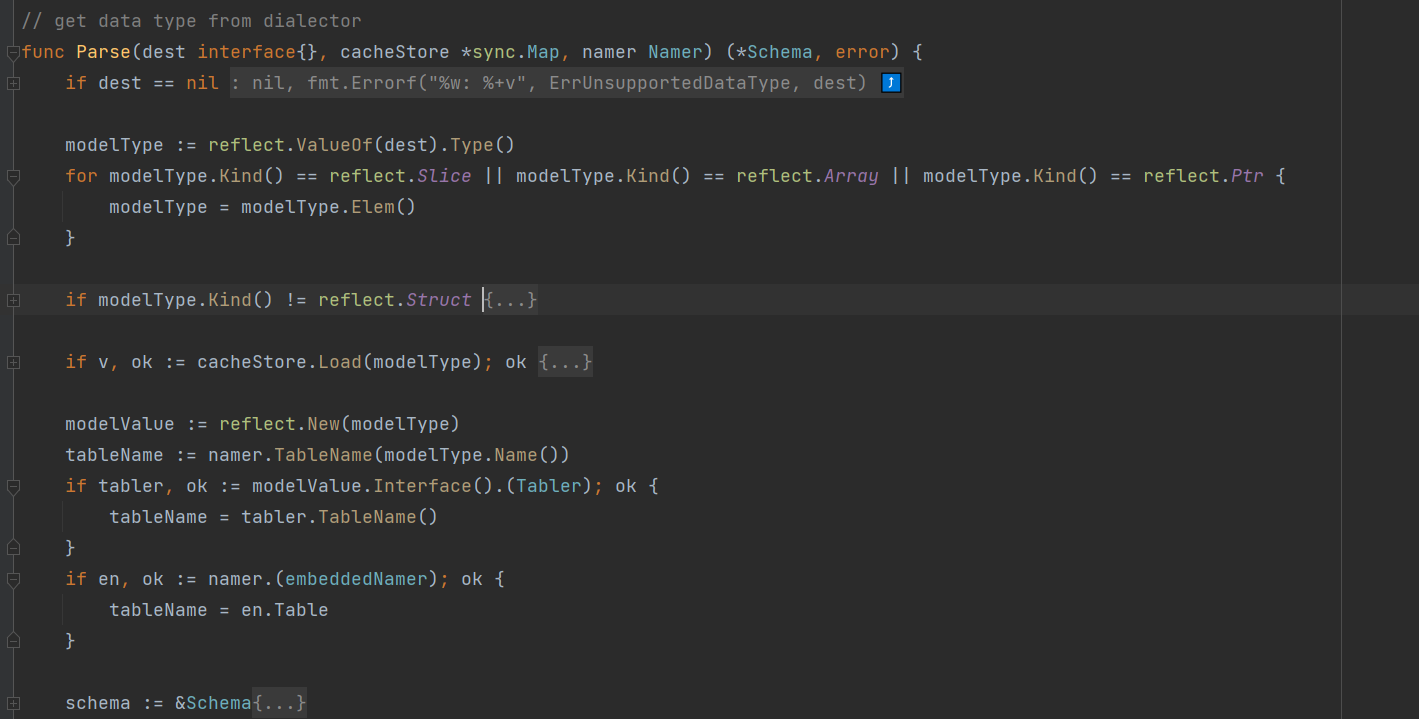
逐个字段解析,可以清晰看到,它只解析公开字段。 GORM 利用 tag 来允许用户设置一些对字段的描述, 例如是否是主键、是否允许自增。从官网也可以看到定义模型,使用 tag。
那么接下来,可以思考一下,实际在自己的 orm 框架中;元数据该怎么定义:
type model struct {// tableName 结构体对应的表名tableName stringfieldMap map[string]*field
}
// field 字段
type field struct {colName string
}
当模型相关的类型定义好后,就开始着眼于要如何解析模型了,模型解析时要考虑通常在 go 开发中,结构体的命名一般采取驼峰式命名;这时将这个结构体映射到数据库表中,必然要考虑如何将驼峰式的命名作一个转换的问题;这里采用驼峰转下划线的方式将模型名称转换为数据库表名,例如:在用户不特殊指定表名 的情况下,如果表模型结构体为 TestModel{} 那么转换到数据库中的表名为 test_model; 包括结构体中的字段也是一样的。
func parseModel(val any) (*Model, error) {if val == nil {return nil, errs.ErrInputNil}ptrTyp := reflect.TypeOf(val)typ := ptrTyp.Elem()if ptrTyp.Kind() != reflect.Ptr || typ.Kind() != reflect.Struct {return nil, errs.ErrPointerOnly}
// 获得字段的数量numField := typ.NumField()fds := make(map[string]*Field, numField)for i := 0; i < numField; i++ {fdType := typ.Field(i)fds[fdType.Name] = &Field{colName: underscoreName(fdType.Name),}}return &Model{tableName: underscoreName(typ.Name()),fieldMap: fds,}, nil
}
// underscoreName 驼峰转字符串命名
func underscoreName(tableName string) string {var buf []bytefor i, v := range tableName {if unicode.IsUpper(v) {if i != 0 {buf = append(buf, '_')}buf = append(buf, byte(unicode.ToLower(v)))} else {buf = append(buf, byte(v))}}return string(buf)
}
注意: 这里模型的解析,只支持一级指针
另外,这里的 error 也是单独拆出来定义的,也叫中心式的 error 定义;从长远维护,或者考虑将来要对 error 进行改造来看,一个集中创建 error 的地方能更高效。
var (// ErrPointerOnly 只支持一级指针作为输入// 看到这个 error 说明你输入了其它的东西// 我们并不希望用户能够直接使用 err == ErrPointerOnly// 所以放在我们的 internal 包里ErrPointerOnly = errors.New("orm: 只支持一级指针作为输入,例如 *User")
)
// NewErrUnknownField 返回代表未知字段的错误
// 一般意味着你可能输入的是列名,或者输入了错误的字段名
func NewErrUnknownField(fd string) error {return fmt.Errorf("orm: 未知字段 %s", fd)
}
// NewErrUnsupportedExpressionType 返回一个不支持该 expression 错误信息
func NewErrUnsupportedExpressionType(exp any) error {return fmt.Errorf("orm: 不支持的表达式 %v", exp)
}
部分错误需要错误信息,那么也可以用定义方法来创建。 wrap error 也可以;
接下来就是顺着解析模型,去改造 Selector 了:
// Selector 用于构造 SELECT 语句
type Selector[T any] struct {sb strings.Builderargs []anytable stringwhere []Predicatemodel *model
}
// From 指定表名,如果是空字符串,那么将会使用默认表名
func (s *Selector[T]) From(tbl string) *Selector[T] {s.table = tblreturn s
}
func (s *Selector[T]) Build() (*Query, error) {var (t Terr error)s.model, err = parseModel(&t)if err != nil {return nil, err}s.sb.WriteString("SELECT * FROM ")if s.table == "" {s.sb.WriteByte('`')s.sb.WriteString(s.model.tableName)s.sb.WriteByte('`')} else {s.sb.WriteString(s.table)}
// 构造 WHEREif len(s.where) > 0 {// 类似这种可有可无的部分,都要在前面加一个空格s.sb.WriteString(" WHERE ")p := s.where[0]for i := 1; i < len(s.where); i++ {p = p.And(s.where[i])}if err := s.buildExpression(p); err != nil {return nil, err}}s.sb.WriteString(";")return &Query{SQL: s.sb.String(),Args: s.args,}, nil
}
func (s *Selector[T]) buildExpression(e Expression) error {if e == nil {return nil}switch exp := e.(type) {case Column:fd, ok := s.model.fieldMap[exp.name]if !ok {return errs.NewErrUnknownField(exp.name)}s.sb.WriteByte('`')s.sb.WriteString(fd.colName)s.sb.WriteByte('`')case value:s.sb.WriteByte('?')s.args = append(s.args, exp.val)case Predicate:_, lp := exp.left.(Predicate)if lp {s.sb.WriteByte('(')}if err := s.buildExpression(exp.left); err != nil {return err}if lp {s.sb.WriteByte(')')}
s.sb.WriteByte(' ')s.sb.WriteString(exp.op.String())s.sb.WriteByte(' ')
_, rp := exp.right.(Predicate)if rp {s.sb.WriteByte('(')}if err := s.buildExpression(exp.right); err != nil {return err}if rp {s.sb.WriteByte(')')}default:return errs.NewErrUnsupportedExpressionType(exp)}return nil
}
// Where 用于构造 WHERE 查询条件。如果 ps 长度为 0,那么不会构造 WHERE 部分
func (s *Selector[T]) Where(ps ...Predicate) *Selector[T] {s.where = psreturn s
}
func NewSelector[T any]() *Selector[T] {return &Selector[T]{}
}
元数据注册中心
它有这样一个问题:每个 Selector 都要解析一 遍,即便是我们测试的 TestModel 也是重复解析 来解析去。能不能一个类型只解析一次?比如说 TestModel 只需要解析一次,后面的就复用前面解析的结果?
func (s *Selector[T]) Build() (*Query, error) {var (t Terr error)s.model, err = parseModel(&t) // 这里每个 Selector 都会重复解析if err != nil {return nil, err}s.sb.WriteString("SELECT * FROM ")if s.table == "" {s.sb.WriteByte('`')s.sb.WriteString(s.model.tableName)s.sb.WriteByte('`')} else {s.sb.WriteString(s.table)}
// 构造 WHEREif len(s.where) > 0 {// 类似这种可有可无的部分,都要在前面加一个空格s.sb.WriteString(" WHERE ")p := s.where[0]for i := 1; i < len(s.where); i++ {p = p.And(s.where[i])}if err := s.buildExpression(p); err != nil {return nil, err}}s.sb.WriteString(";")return &Query{SQL: s.sb.String(),Args: s.args,}, nil
}
答案是可以的,通过一个公共的模块来存放该元数据可以达到该效果,这个公共的模块就叫做元数据注册中心;那元数据注册中心要如何定义?
全局map:
var models = map[reflect.Type]*model{}
-
缺乏扩展性:无法在 models 上定义任何方法
-
缺乏隔离性:如果不同 DB 之间需要隔离,那么 毫无办法
-
难以测试:包变量的天然缺点,会间接引起不同 测试之间的耦合
定义了 registry,但是维持全局一个实例:
-
难以测试:包变量的天然缺点,会间接引起不 同测试之间的耦合
在 Go 的 SDK 里面经常能见到类似的设计。 大概可以看做:
-
有一个接口
-
有一个默认实现
-
维持一个包变量的默认实例
-
提供包方法,直接操作默认实例
Beego 里面的 modelCache 就是维持了一个全 局变量,所以它的 ORM 单元测试很难独立运行, 互相之间都会有影响。

个人看法:不到逼不得已,不要使用包变量。 所以我们需要考虑把注册中心交给一个东西来维护, 那么给谁呢?当然是 DB 模块了。
为什么说 DB 是最佳选择?
DB 在 ORM 中的地位,就相当于 HTTPServer 在 Web 框架中的地位。
-
允许用户使用多个 DB 实例
-
每个 DB 实例可以单独配置,例如配置元数据中心
-
DB 就是天然的隔离和治理单位
-
例如超时配置
-
方言:例如 MySQL DB 和 SQLite DB
-
慢查询阈值
-
创建DB
type DBOption func(*DB)
type DB struct {r *registry
}
func NewDB(opts ...DBOption) (*DB, error) {db := &DB{r: ®istry{},}for _, opt := range opts {opt(db)}return db, nil
}
暂时设计一个 NewDB 的方法,并且留下了 Option 模式的口子,为将来留下扩展性的口子。后面支持更多功能的时候,会在 DB 里面不断添 加字段。
registry 定义
理论上来说,models 的 key 有三种选择:
-
结构体名字(类型名字):例如 User。其实不太行,因为用户有同名结构体但是 表名不一样的需求,例如 buyer 包下面的 User 和 seller 包下面的 User。
-
表名:例如 user_t。这个肯定不行,因为在拿到元数据之前我们都不知道表名是 什么。
-
reflect.Type:唯一的选择
type registry struct {// model key 是类型名// 这种定义方式是不行的// 1. 类型名冲突,例如都是 User,但是一个映射过去 buyer_t// 一个映射过去 seller_t// 2. 并发不安全// model map[string]*model
lock sync.RWMutexmodels map[reflect.Type]*Model
使用 sync.Map//model sync.Map
}
-
models 字段:采用的是反射类型 => 元数据 的映射关系
-
get 方法:会首先查找 models,没有找到就会开 始解析,解析完放回去 models
// 使用读写锁的并发安全解决思路
func (r *registry) get(val any) (*Model, error) {if val == nil {return nil, errs.ErrInputNil}r.lock.RLock()typ := reflect.TypeOf(val)m, ok := r.models[typ]r.lock.RUnlock()if ok {return m, nil}
r.lock.Lock()defer r.lock.Unlock()m, ok = r.models[typ]if ok {return m, nil}var err errorif m, err = r.parseModel(typ); err != nil {return nil, err}r.models[typ] = mreturn m, nil
}
最后再一次改造 Selector;构造 SELECT 语句的时候从 registry 里面拿元数据。
// Selector 用于构造 SELECT 语句
type Selector[T any] struct {sb strings.Builderargs []anytable stringwhere []Predicatemodel *model
db *DB
}
func (s *Selector[T]) Build() (*Query, error) {var (t Terr error)s.model, err = s.db.r.get(&t)if err != nil {return nil, err}s.sb.WriteString("SELECT * FROM ")if s.table == "" {s.sb.WriteByte('`')s.sb.WriteString(s.model.tableName)s.sb.WriteByte('`')} else {s.sb.WriteString(s.table)}
// 构造 WHEREif len(s.where) > 0 {// 类似这种可有可无的部分,都要在前面加一个空格s.sb.WriteString(" WHERE ")p := s.where[0]for i := 1; i < len(s.where); i++ {p = p.And(s.where[i])}if err := s.buildExpression(p); err != nil {return nil, err}}s.sb.WriteString(";")return &Query{SQL: s.sb.String(),Args: s.args,}, nil
}
自定义表名和列名
目前我们的策略是驼峰转下划线命名,例如 FirstName 变成 first_name。 但是用户会有各种个性化的需求:
-
自定义表名:比如说有些公司认为,User 结构体对 应的表名应该是 user_t
-
自定义列名:比如说字段 Status,在 user_t 里面 可能就叫做 user_statu
先来看看 Beego 和 Gorm 是怎么做的
Beego orm
Beego orm 里面提供了两种方式:
-
标签(Tag):用户可以在标签里面指定很多东 西,列名只是其中之一

-
实现特定接口:例如实现了 TableNameI 就可以自 定义表名
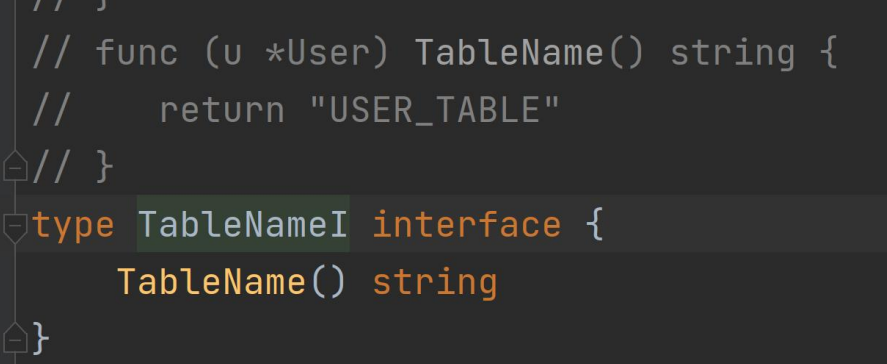
这两种做法都有限制,比如它们对 protobuf 生成的结 构体,就不太好用。自己手写的结构体就没什么问 题。
Gorm
Gorm 和 Beego 差不多,都是标签和接口两种形态。
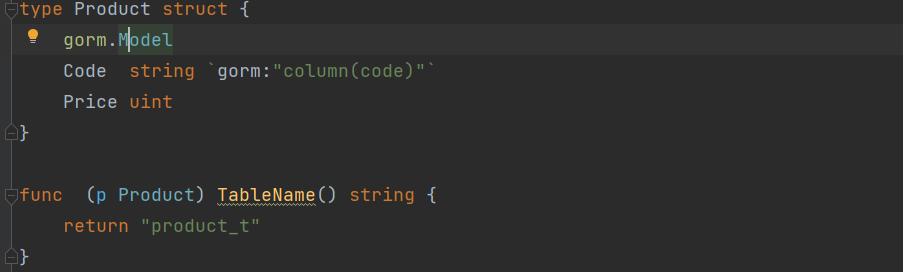
这里参考 beego 和 Grom 的策略 主要就是两个步骤: 定义标签的语法:这个完全就是个人偏好 解析标签:也就是利用反射提取到完整标 签,然后按照我们的需要进行切割
func (r *registry) parseTag(tag reflect.StructTag) (map[string]string, error) {ormTag := tag.Get("orm")if ormTag == "" {// 返回一个空的 map,这样调用者就不需要判断 nil 了return map[string]string{}, nil}// 这个初始化容量就是我们支持的 key 的数量,// 现在只有一个,所以我们初始化为 1res := make(map[string]string, 1)
// 接下来就是字符串处理了pairs := strings.Split(ormTag, ",")for _, pair := range pairs {kv := strings.Split(pair, "=")if len(kv) != 2 {return nil, errs.NewErrInvalidTagContent(pair)}res[kv[0]] = kv[1]}return res, nil
}
接口自定义表名
支持标签有一个很尴尬的问题:
-
Go 的标签只支持声明在字段上,也就是说你无法 为类型定义标签
所以在采用标签方案的时候,意味着我们只能支持字段。结构体级别(或者说表级别),需要额外的手段。 很显然,可以参考 Beego 和 ORM 的做法。 相比原来, parseModel 多调用了一次 reflect.Type, 但是这一点点性能消耗,完全不用在意。
// TableName 用户实现这个接口来返回自定义的表名
type TableName interface {TableName() string
}
// parseModel 支持从标签中提取自定义设置
// 标签形式 orm:"key1=value1,key2=value2"
// 改为接收最原始的 val
func (r *registry) parseModel(val any) (*model, error) { typ := reflect.TypeOf(val)if typ.Kind() != reflect.Ptr ||typ.Elem().Kind() != reflect.Struct {return nil, errs.ErrPointerOnly}typ = typ.Elem()
// 获得字段的数量numField := typ.NumField()fds := make(map[string]*field, numField)for i := 0; i < numField; i++ {fdType := typ.Field(i)// 解析 tagtags, err := r.parseTag(fdType.Tag)if err != nil {return nil, err}colName := tags[tagKeyColumn]if colName == "" {colName = underscoreName(fdType.Name)}fds[fdType.Name] = &field{colName: colName,}}var tableName string// 判断是否实现了 TableName 接口if tn, ok := val.(TableName); ok {tableName = tn.TableName()}
if tableName == "" {tableName = underscoreName(typ.Name())}
return &model{tableName: tableName,fieldMap: fds,}, nil
}
总结
-
ORM 框架是怎么将一个结构体映射为一张表的(或者反过来)?核心就是依赖于元数据,元数据描述 了两者之间的映射关系。
-
ORM 的元数据有什么用?在构造 SQL 的时候,用来将 Go 类型映射为表;在处理结果集的时候,用来 将表映射为 Go结构体。
-
ORM 的元数据一般包含什么?一般包含表信息、列信息、索引信息。在支持关联关系的时候,还包含 表之间的关联关系。
-
ORM 的表信息包含什么?主要就是表级别上的配置,例如表名。如果 ORM 本身支持分库分表,那么 还包含分库分表信息。
-
ORM 的列信息包含什么?主要就是列名、类型(和对应的 Go 类型)、索引、是否主键,以及关联关 系。
-
ORM 的索引信息包含什么?主要就是每一个索引的列,以及是否唯一。
-
ORM 如何获得模型信息?主要是利用反射来解析 Go 类型,同时可以利用 Tag,或者暴露编程接口, 允许用户额外定制模型(例如指定表名)。
-
Go 字段上的 Tag(标签)有什么用?用来描述字段本身的额外信息,例如使用 json 来指示转化 json 之后的字段名字,或者如 GORM 使用 Tag 来指定列的名字、索引等。这种问题可能出在面试官问 Go 语法上。
-
GORM(Beego) 是如何实现的?只要回答构造 SQL + 处理结果集 + 元数据就可以了。剩下的可能就 是进一步问 SQL 怎么构造,以及结果集是如何被处理的。








![勒索病毒.[tsai.shen@mailfence.com].faust、.[support2022@cock.li].faust引起的数据被加密恢复](https://img-blog.csdnimg.cn/1cb61e7299d241738b9e270cc89a1e00.png)