文章目录
- 0 前言
- 1 VGG网络
- 2 风格迁移
- 3 内容损失
- 4 风格损失
- 5 主代码实现
- 6 迁移模型实现
- 7 效果展示
- 8 最后
0 前言
🔥 这两年开始毕业设计和毕业答辩的要求和难度不断提升,传统的毕设题目缺少创新和亮点,往往达不到毕业答辩的要求,这两年不断有学弟学妹告诉学长自己做的项目系统达不到老师的要求。
为了大家能够顺利以及最少的精力通过毕设,学长分享优质毕业设计项目,今天要分享的是
🚩 毕设 深度学习图像风格迁移 - opencv python
🥇学长这里给一个题目综合评分(每项满分5分)
- 难度系数:3分
- 工作量:3分
- 创新点:4分
🧿 选题指导, 项目分享:
https://gitee.com/dancheng-senior/project-sharing-1/blob/master/%E6%AF%95%E8%AE%BE%E6%8C%87%E5%AF%BC/README.md
图片风格迁移指的是将一个图片的风格转换到另一个图片中,如图所示:

原图片经过一系列的特征变换,具有了新的纹理特征,这就叫做风格迁移。
1 VGG网络
在实现风格迁移之前,需要先简单了解一下VGG网络(由于VGG网络不断使用卷积提取特征的网络结构和准确的图像识别效率,在这里我们使用VGG网络来进行图像的风格迁移)。
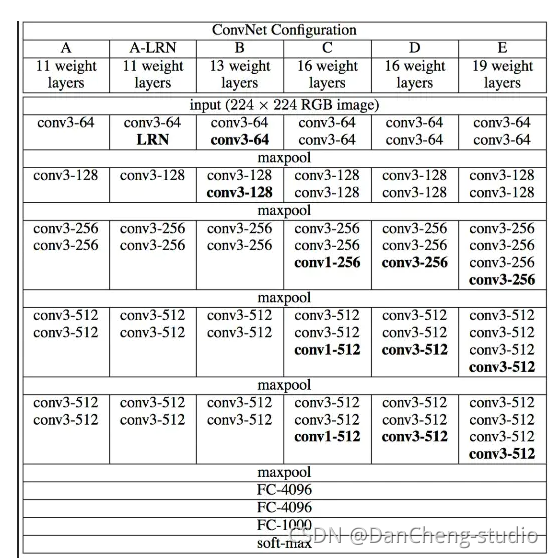
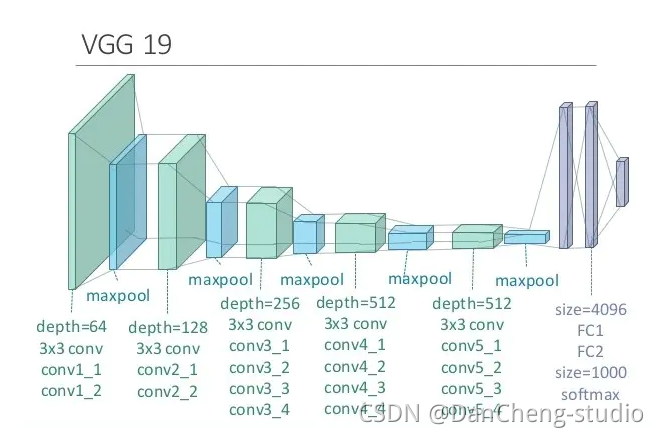
如上图所示,从A-E的每一列都表示了VGG网络的结构原理,其分别为:VGG-11,VGG-13,VGG-16,VGG-19,如下图,一副图片经过VGG-19网络结构可以最后得到一个分类结构。
2 风格迁移
对一副图像进行风格迁移,需要清楚的有两点。
- 生成的图像需要具有原图片的内容特征
- 生成的图像需要具有风格图片的纹理特征
根据这两点,可以确定,要想实现风格迁移,需要有两个loss值:
一个是生成图片的内容特征与原图的内容特征的loss,另一个是生成图片的纹理特征与风格图片的纹理特征的loss。
而对一张图片进行不同的特征(内容特征和纹理特征)提取,只需要使用不同的卷积结构进行训练即可以得到。这时我们需要用到两个神经网络。
再回到VGG网络上,VGG网络不断使用卷积层来提取特征,利用特征将物品进行分类,所以该网络中提取内容和纹理特征的参数都可以进行迁移使用。故需要将生成的图片经过VGG网络的特征提取,再分别针对内容和纹理进行特征的loss计算。
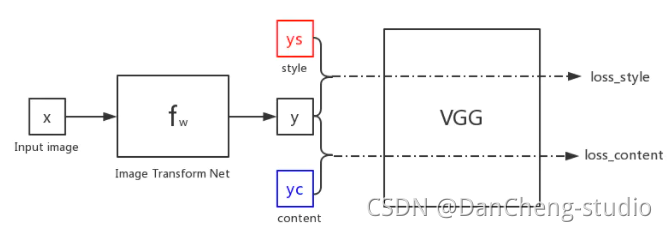
如图,假设初始化图像x(Input image)是一张随机图片,我们经过fw(image Transform Net)网络进行生成,生成图片y。
此时y需要和风格图片ys进行特征的计算得到一个loss_style,与内容图片yc进行特征的计算得到一个loss_content,假设loss=loss_style+loss_content,便可以对fw的网络参数进行训练。
现在就可以看网上很常见的一张图片了:
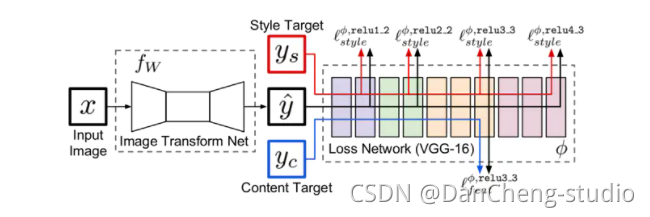
相较于我画的第一张图,这即对VGG内的loss求值过程进行了细化。
细化的结果可以分为两个方面:
- (1)内容损失
- (2)风格损失
3 内容损失
由于上图中使用的模型是VGG-16,那么即相当于在VGG-16的relu3-3处,对两张图片求得的特征进行计算求损失,计算的函数如下:
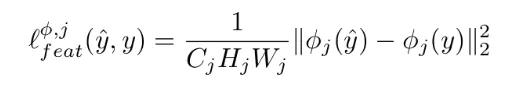
简言之,假设yc求得的特征矩阵是φ(y),生成图片求得的特征矩阵为φ(y^),且c=φ.channel,w=φ.weight,h=φ.height,则有:
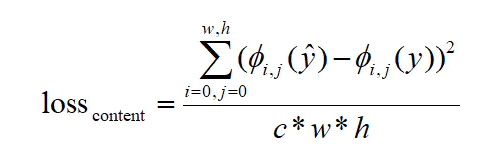
代码实现:
def content_loss(content_img, rand_img):content_layers = [('relu3_3', 1.0)]content_loss = 0.0# 逐个取出衡量内容损失的vgg层名称及对应权重for layer_name, weight in content_layers:# 计算特征矩阵p = get_vgg(content_img, layer_name)x = get_vgg(rand_img, layer_name)# 长x宽xchannelM = p.shape[1] * p.shape[2] * p.shape[3]# 根据公式计算损失,并进行累加content_loss += (1.0 / M) * tf.reduce_sum(tf.pow(p - x, 2)) * weight# 将损失对层数取平均content_loss /= len(content_layers)return content_loss
4 风格损失
风格损失由多个特征一同计算,首先需要计算Gram Matrix
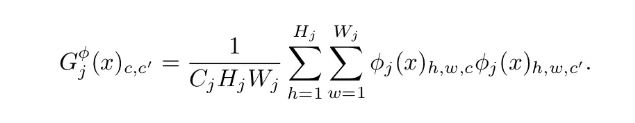
Gram Matrix实际上可看做是feature之间的偏心协方差矩阵(即没有减去均值的协方差矩阵),在feature map中,每一个数字都来自于一个特定滤波器在特定位置的卷积,因此每个数字就代表一个特征的强度,而Gram计算的实际上是两两特征之间的相关性,哪两个特征是同时出现的,哪两个是此消彼长的等等,同时,Gram的对角线元素,还体现了每个特征在图像中出现的量,因此,Gram有助于把握整个图像的大体风格。有了表示风格的Gram Matrix,要度量两个图像风格的差异,只需比较他们Gram Matrix的差异即可。 故在计算损失的时候函数如下:
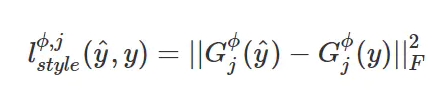
在实际使用时,该loss的层级一般选择由低到高的多个层,比如VGG16中的第2、4、7、10个卷积层,然后将每一层的style loss相加。
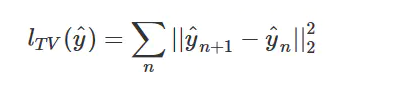
第三个部分不是必须的,被称为Total Variation Loss。实际上是一个平滑项(一个正则化项),目的是使生成的图像在局部上尽可能平滑,而它的定义和马尔科夫随机场(MRF)中使用的平滑项非常相似。 其中yn+1是yn的相邻像素。
代码实现以上函数:
# 求gamm矩阵
def gram(x, size, deep):x = tf.reshape(x, (size, deep))g = tf.matmul(tf.transpose(x), x)return gdef style_loss(style_img, rand_img):style_layers = [('relu1_2', 0.25), ('relu2_2', 0.25), ('relu3_3', 0.25), ('reluv4_3', 0.25)]style_loss = 0.0# 逐个取出衡量风格损失的vgg层名称及对应权重for layer_name, weight in style_layers:# 计算特征矩阵a = get_vgg(style_img, layer_name)x = get_vgg(rand_img, layer_name)# 长x宽M = a.shape[1] * a.shape[2]N = a.shape[3]# 计算gram矩阵A = gram(a, M, N)G = gram(x, M, N)# 根据公式计算损失,并进行累加style_loss += (1.0 / (4 * M * M * N * N)) * tf.reduce_sum(tf.pow(G - A, 2)) * weight# 将损失对层数取平均style_loss /= len(style_layers)return style_loss
5 主代码实现
代码实现主要分为4步:
- 1、随机生成图片
- 2、读取内容和风格图片
- 3、计算总的loss
- 4、训练修改生成图片的参数,使得loss最小
def main():# 生成图片rand_img = tf.Variable(random_img(WIGHT, HEIGHT), dtype=tf.float32)with tf.Session() as sess:content_img = cv2.imread('content.jpg')style_img = cv2.imread('style.jpg')# 计算loss值cost = ALPHA * content_loss(content_img, rand_img) + BETA * style_loss(style_img, rand_img)optimizer = tf.train.AdamOptimizer(LEARNING_RATE).minimize(cost)sess.run(tf.global_variables_initializer())for step in range(TRAIN_STEPS):# 训练sess.run([optimizer, rand_img])if step % 50 == 0:img = sess.run(rand_img)img = np.clip(img, 0, 255).astype(np.uint8)name = OUTPUT_IMAGE + "//" + str(step) + ".jpg"cv2.imwrite(name, img)
6 迁移模型实现
由于在进行loss值求解时,需要在多个网络层求得特征值,并根据特征值进行带权求和,所以需要根据已有的VGG网络,取其参数,重新建立VGG网络。
注意:在这里使用到的是VGG-19网络:
在重建的之前,首先应该下载Google已经训练好的VGG-19网络,以便提取出已经训练好的参数,在重建的VGG-19网络中重新利用。

下载得到.mat文件以后,便可以进行网络重建了。已知VGG-19网络的网络结构如上述图1中的E网络,则可以根据E网络的结构对网络重建,VGG-19网络:

进行重建即根据VGG-19模型的结构重新创建一个结构相同的神经网络,提取出已经训练好的参数作为新的网络的参数,设置为不可改变的常量即可。
def vgg19():layers=('conv1_1','relu1_1','conv1_2','relu1_2','pool1','conv2_1','relu2_1','conv2_2','relu2_2','pool2','conv3_1','relu3_1','conv3_2','relu3_2','conv3_3','relu3_3','conv3_4','relu3_4','pool3','conv4_1','relu4_1','conv4_2','relu4_2','conv4_3','relu4_3','conv4_4','relu4_4','pool4','conv5_1','relu5_1','conv5_2','relu5_2','conv5_3','relu5_3','conv5_4','relu5_4','pool5')vgg = scipy.io.loadmat('D://python//imagenet-vgg-verydeep-19.mat')weights = vgg['layers'][0]network={}net = tf.Variable(np.zeros([1, 300, 450, 3]), dtype=tf.float32)network['input'] = netfor i,name in enumerate(layers):layer_type=name[:4]if layer_type=='conv':kernels = weights[i][0][0][0][0][0]bias = weights[i][0][0][0][0][1]conv=tf.nn.conv2d(net,tf.constant(kernels),strides=(1,1,1,1),padding='SAME',name=name)net=tf.nn.relu(conv + bias)elif layer_type=='pool':net=tf.nn.max_pool(net,ksize=(1,2,2,1),strides=(1,2,2,1),padding='SAME')network[name]=netreturn network
由于计算风格特征和内容特征时数据都不会改变,所以为了节省训练时间,在训练之前先计算出特征结果(该函数封装在以下代码get_neck()函数中)。
总的代码如下:
import tensorflow as tf
import numpy as np
import scipy.io
import cv2
import scipy.miscHEIGHT = 300
WIGHT = 450
LEARNING_RATE = 1.0
NOISE = 0.5
ALPHA = 1
BETA = 500TRAIN_STEPS = 200OUTPUT_IMAGE = "D://python//img"
STYLE_LAUERS = [('conv1_1', 0.2), ('conv2_1', 0.2), ('conv3_1', 0.2), ('conv4_1', 0.2), ('conv5_1', 0.2)]
CONTENT_LAYERS = [('conv4_2', 0.5), ('conv5_2',0.5)]def vgg19():layers=('conv1_1','relu1_1','conv1_2','relu1_2','pool1','conv2_1','relu2_1','conv2_2','relu2_2','pool2','conv3_1','relu3_1','conv3_2','relu3_2','conv3_3','relu3_3','conv3_4','relu3_4','pool3','conv4_1','relu4_1','conv4_2','relu4_2','conv4_3','relu4_3','conv4_4','relu4_4','pool4','conv5_1','relu5_1','conv5_2','relu5_2','conv5_3','relu5_3','conv5_4','relu5_4','pool5')vgg = scipy.io.loadmat('D://python//imagenet-vgg-verydeep-19.mat')weights = vgg['layers'][0]network={}net = tf.Variable(np.zeros([1, 300, 450, 3]), dtype=tf.float32)network['input'] = netfor i,name in enumerate(layers):layer_type=name[:4]if layer_type=='conv':kernels = weights[i][0][0][0][0][0]bias = weights[i][0][0][0][0][1]conv=tf.nn.conv2d(net,tf.constant(kernels),strides=(1,1,1,1),padding='SAME',name=name)net=tf.nn.relu(conv + bias)elif layer_type=='pool':net=tf.nn.max_pool(net,ksize=(1,2,2,1),strides=(1,2,2,1),padding='SAME')network[name]=netreturn network# 求gamm矩阵
def gram(x, size, deep):x = tf.reshape(x, (size, deep))g = tf.matmul(tf.transpose(x), x)return gdef style_loss(sess, style_neck, model):style_loss = 0.0for layer_name, weight in STYLE_LAUERS:# 计算特征矩阵a = style_neck[layer_name]x = model[layer_name]# 长x宽M = a.shape[1] * a.shape[2]N = a.shape[3]# 计算gram矩阵A = gram(a, M, N)G = gram(x, M, N)# 根据公式计算损失,并进行累加style_loss += (1.0 / (4 * M * M * N * N)) * tf.reduce_sum(tf.pow(G - A, 2)) * weight# 将损失对层数取平均style_loss /= len(STYLE_LAUERS)return style_lossdef content_loss(sess, content_neck, model):content_loss = 0.0# 逐个取出衡量内容损失的vgg层名称及对应权重for layer_name, weight in CONTENT_LAYERS:# 计算特征矩阵p = content_neck[layer_name]x = model[layer_name]# 长x宽xchannelM = p.shape[1] * p.shape[2]N = p.shape[3]lss = 1.0 / (M * N)content_loss += lss * tf.reduce_sum(tf.pow(p - x, 2)) * weight# 根据公式计算损失,并进行累加# 将损失对层数取平均content_loss /= len(CONTENT_LAYERS)return content_lossdef random_img(height, weight, content_img):noise_image = np.random.uniform(-20, 20, [1, height, weight, 3])random_img = noise_image * NOISE + content_img * (1 - NOISE)return random_imgdef get_neck(sess, model, content_img, style_img):sess.run(tf.assign(model['input'], content_img))content_neck = {}for layer_name, weight in CONTENT_LAYERS:# 计算特征矩阵p = sess.run(model[layer_name])content_neck[layer_name] = psess.run(tf.assign(model['input'], style_img))style_content = {}for layer_name, weight in STYLE_LAUERS:# 计算特征矩阵a = sess.run(model[layer_name])style_content[layer_name] = areturn content_neck, style_contentdef main():model = vgg19()content_img = cv2.imread('D://a//content1.jpg')content_img = cv2.resize(content_img, (450, 300))content_img = np.reshape(content_img, (1, 300, 450, 3)) - [128.0, 128.2, 128.0]style_img = cv2.imread('D://a//style1.jpg')style_img = cv2.resize(style_img, (450, 300))style_img = np.reshape(style_img, (1, 300, 450, 3)) - [128.0, 128.2, 128.0]# 生成图片rand_img = random_img(HEIGHT, WIGHT, content_img)with tf.Session() as sess:# 计算loss值content_neck, style_neck = get_neck(sess, model, content_img, style_img)cost = ALPHA * content_loss(sess, content_neck, model) + BETA * style_loss(sess, style_neck, model)optimizer = tf.train.AdamOptimizer(LEARNING_RATE).minimize(cost)sess.run(tf.global_variables_initializer())sess.run(tf.assign(model['input'], rand_img))for step in range(TRAIN_STEPS):print(step)# 训练sess.run(optimizer)if step % 10 == 0:img = sess.run(model['input'])img += [128, 128, 128]img = np.clip(img, 0, 255).astype(np.uint8)name = OUTPUT_IMAGE + "//" + str(step) + ".jpg"img = img[0]cv2.imwrite(name, img)img = sess.run(model['input'])img += [128, 128, 128]img = np.clip(img, 0, 255).astype(np.uint8)cv2.imwrite("D://end.jpg", img[0])main()
7 效果展示